<TensorFlow学习使用P1>——《TensorFlow教程》-程序员宅基地
技术标签: 《人工智能AI》 经验分享 # 《计算机视觉》 tensorflow python # 《深度学习》 计算机视觉 人工智能 分类
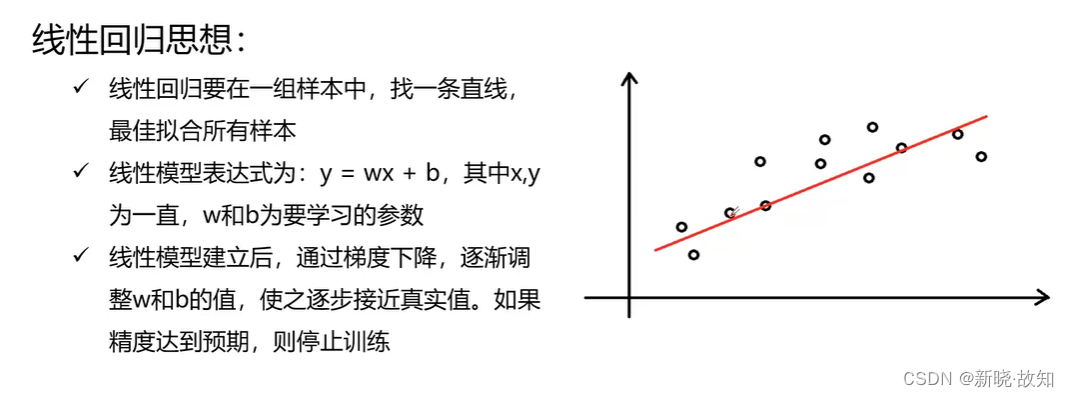
一、TensorFlow概述
前言:
本文中一些TensorFlow综合案例的代码逻辑一般正常,在本地均可运行。如有代码复现运行失败,原因如下:
(1)运行环境配置可能有误。
(2)由于一些数据集存储空间较大,这里没有上传,代码可能无法加载相应文件。
(3)涉及到一些存储、加载的文件路径没有填写正确等。
(4)本博客中涉及到TensorFlow的环境安装,这里没有详细展开,读者如有遇到环境安装问题,可通过开源社区互助解决。
- 读者可注意比对Pycharm中,左上部分的project文件区域,查看是否有相对应的文件或文件夹。作者这里入过坑,但经过不断修改,所有代码已验证均可正常运行。
- 作者在此向无数为科学研究及应用、推动人类文明向前发展,所付出心血的前辈们致敬!祝福开源世界蒸蒸日上,让知识不再因壁垒而淡去星辉!
1.什么是TensorFlow

TensorFlow的发展历史:

2.TensorFlow的特点

3.TensorFlow的安装

TensorFlow离线包地址链接:https://pypi.org/project/tensorflow/#files

4.TensorFlow的使用
示例1:使用TensorFlow打印“helloworld”
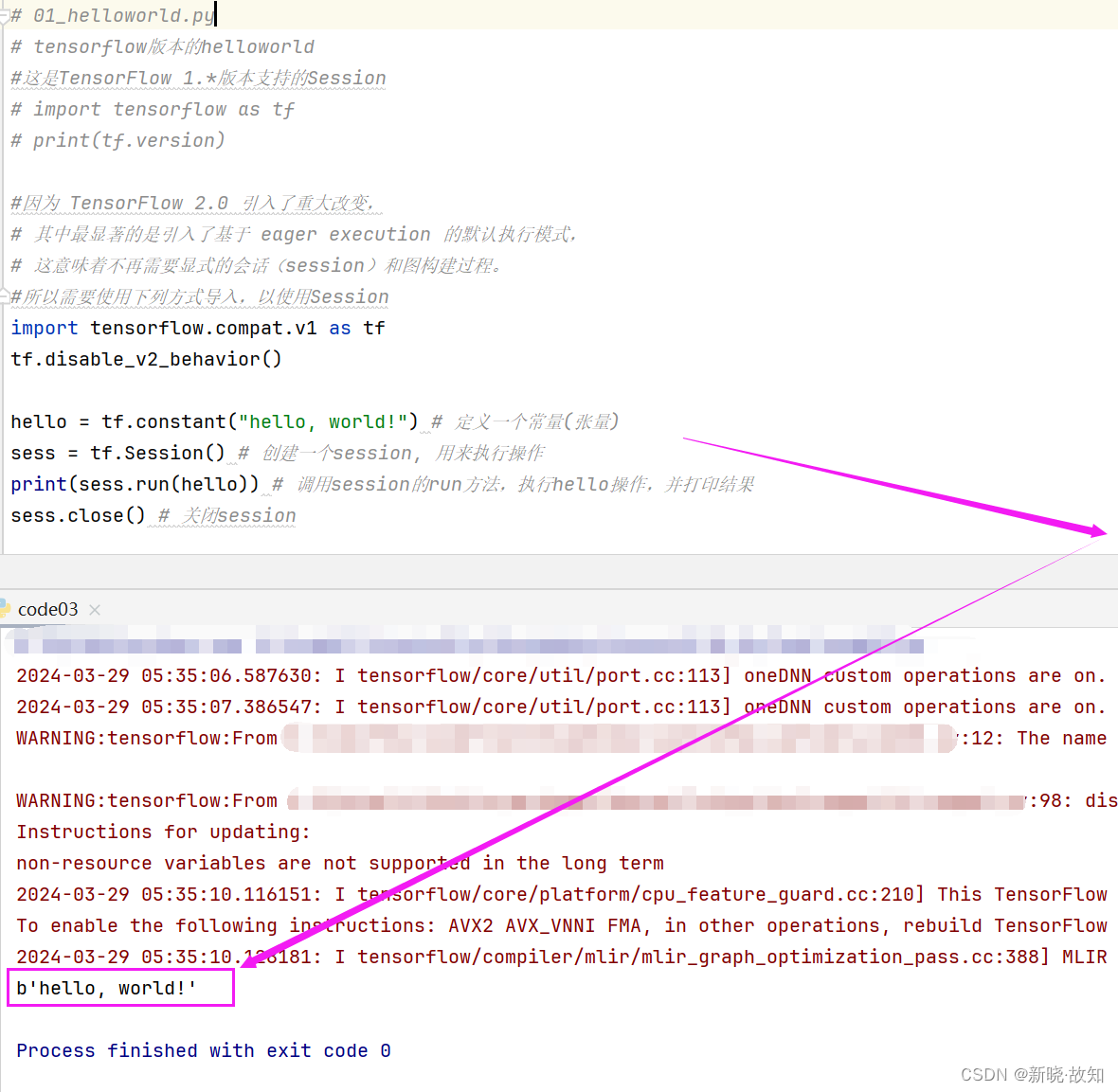
# 01_helloworld.py
# tensorflow版本的helloworld
#这是TensorFlow 1.*版本支持的Session
# import tensorflow as tf
# print(tf.version)
#因为 TensorFlow 2.0 引入了重大改变,
# 其中最显著的是引入了基于 eager execution 的默认执行模式,
# 这意味着不再需要显式的会话(session)和图构建过程。
#所以需要使用下列方式导入,以使用Session
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
hello = tf.constant("hello, world!") # 定义一个常量(张量)
sess = tf.Session() # 创建一个session, 用来执行操作
print(sess.run(hello)) # 调用session的run方法,执行hello操作,并打印结果
sess.close() # 关闭session
示例2:使用TensorFlow实现加法操作
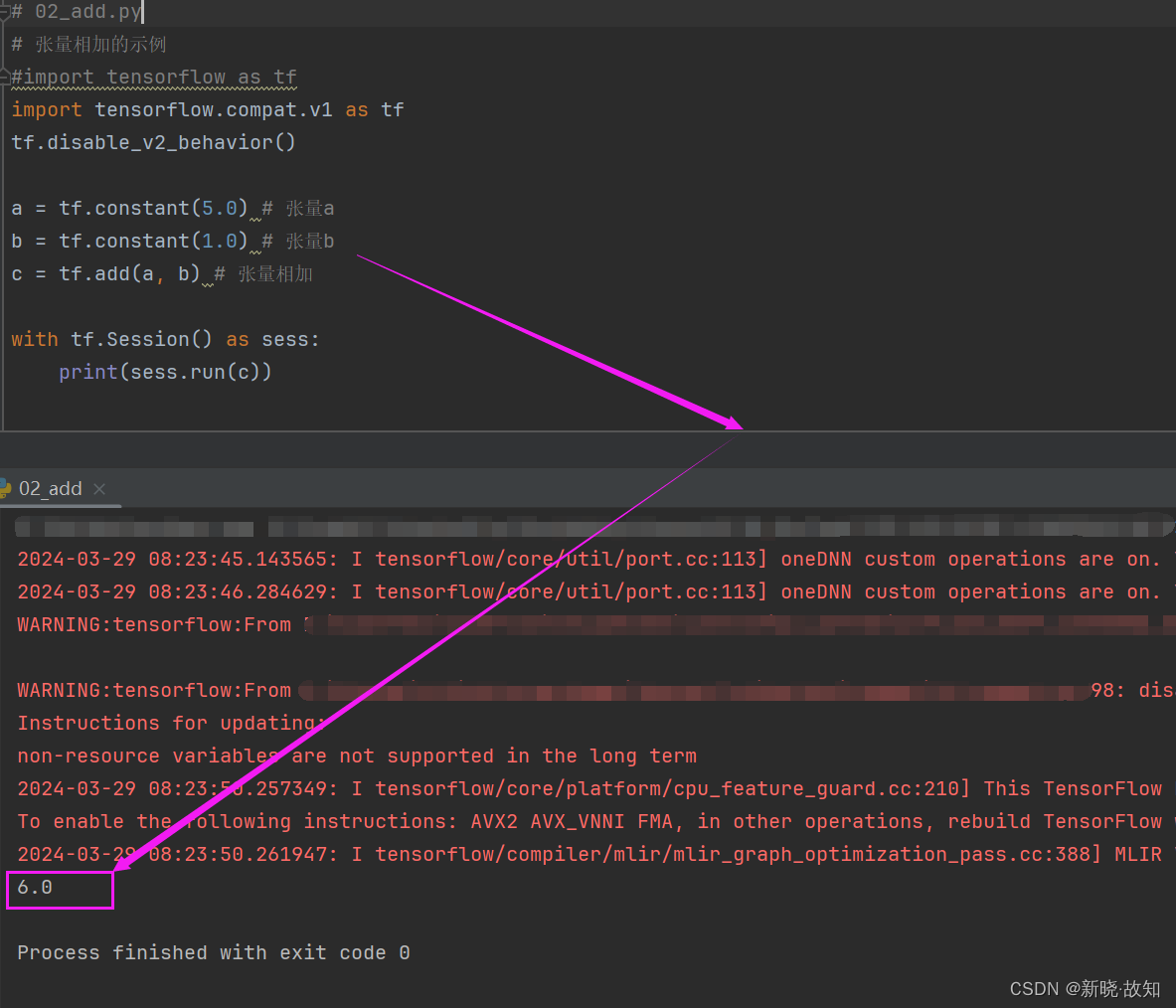
# 02_add.py
# 张量相加的示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a = tf.constant(5.0) # 张量a
b = tf.constant(1.0) # 张量b
c = tf.add(a, b) # 张量相加
with tf.Session() as sess:
print(sess.run(c))
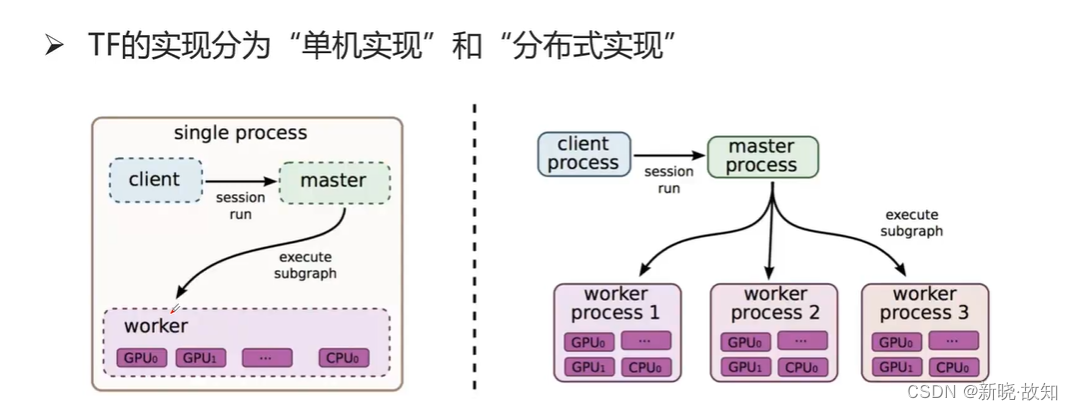
5.TensorFlow的体系结构
体系结构概述:

5.1单机模式与分布式模式
5.2后端逻辑层次
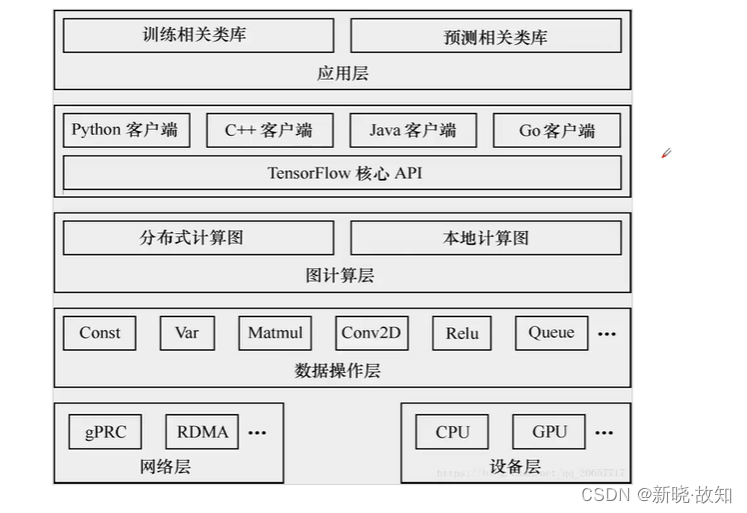
6.TensorFlow基本概念
张量:
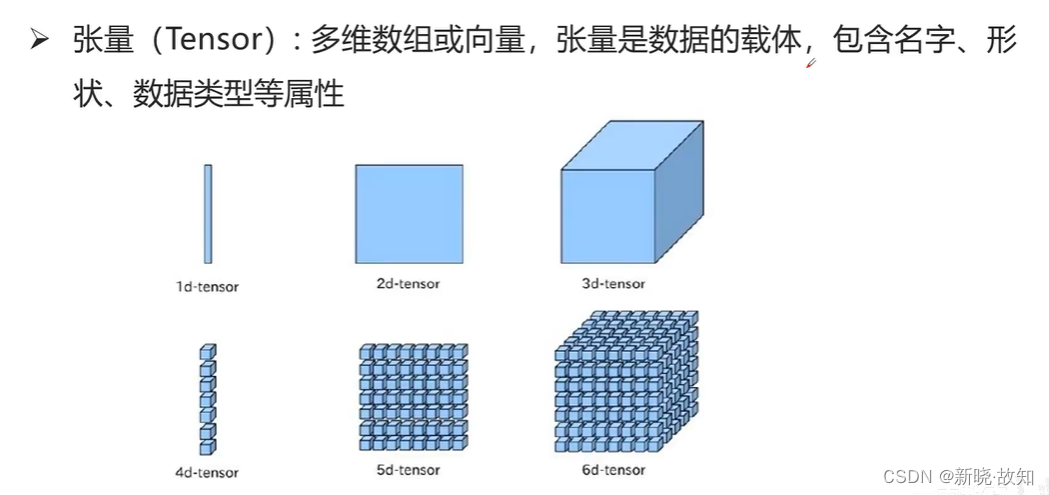
数据流:

操作:

图和会话:

变量和占位符:

二、TensorFlow基本操作
1.图和会话操作
1.1什么是图


会话的操作:

示例3:使用TensorFlow查看图对象、指定会话运行某个图

# 03_graph_attr.py
# 查看默认图的属性
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a = tf.constant(5.0)
print(a)
b = tf.constant(1.0)
c = tf.add(a, b)
graph = tf.get_default_graph() # 获取默认的图
print("graph:",graph)
# 新创建一个图
graph2 = tf.Graph()
print("graph2:",graph2)
with graph2.as_default(): # 设置为默认图
d = tf.constant(11.0) # 操作d属于graph2
with tf.Session(graph=graph2) as sess: # 指定执行graph2
# print(sess.run(c)) # 报错,因为c没有在默认graph2中
print(sess.run(d))
print(a.graph) # 打印张量的graph属性
print(c.graph) # 打印c操作的graph属性
print(sess.graph) # 打印session的graph属性
会话常见的错误及原因:

1.2张量的属性及基本运算
张量的阶与形状:

张量的数据类型:

示例4:使用TensorFlow查看张量属性
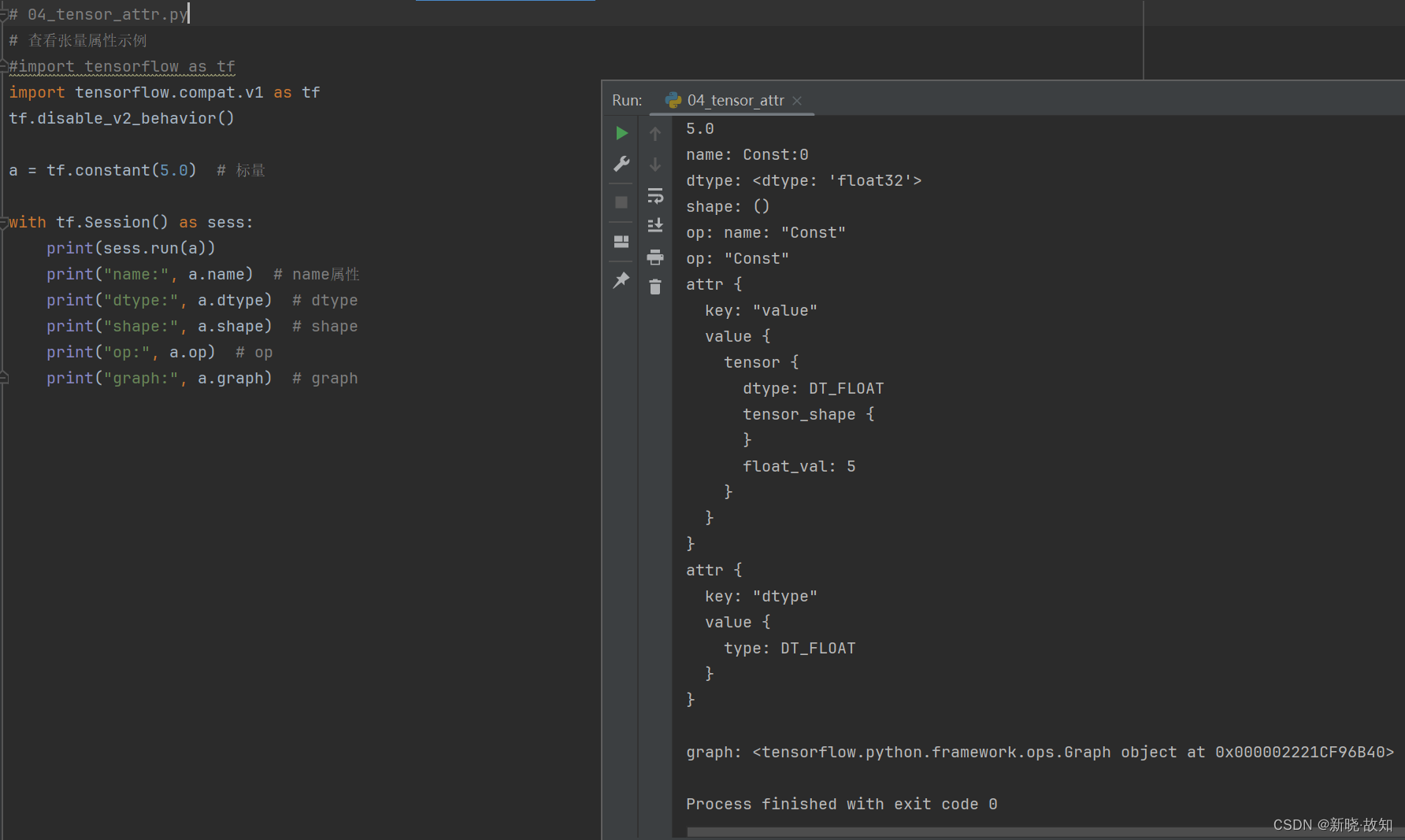
# 04_tensor_attr.py
# 查看张量属性示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a = tf.constant(5.0) # 标量
with tf.Session() as sess:
print(sess.run(a))
print("name:", a.name) # name属性
print("dtype:", a.dtype) # dtype
print("shape:", a.shape) # shape
print("op:", a.op) # op
print("graph:", a.graph) # graph
示例5:使用TensorFlow创建张量
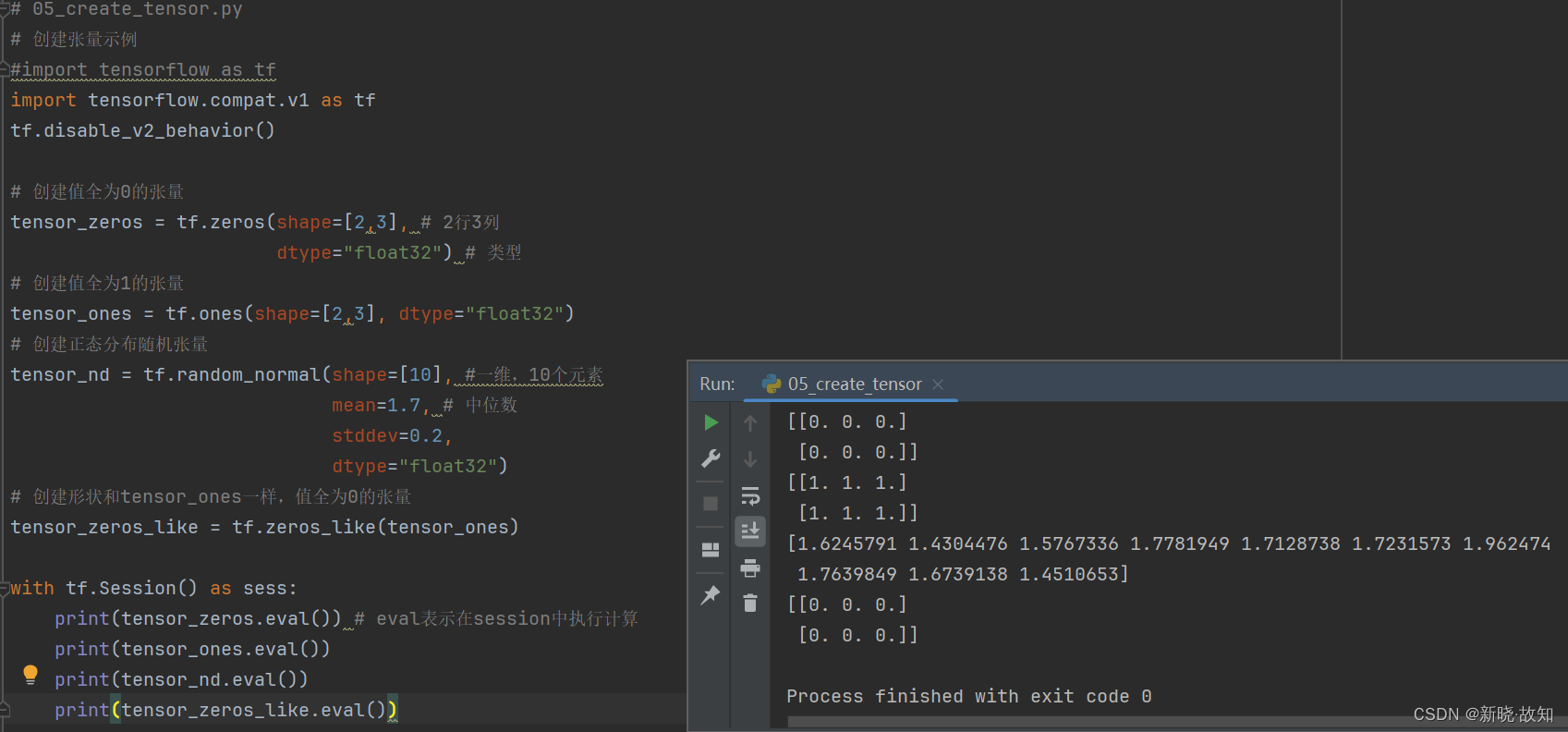
# 05_create_tensor.py
# 创建张量示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# 创建值全为0的张量
tensor_zeros = tf.zeros(shape=[2,3], # 2行3列
dtype="float32") # 类型
# 创建值全为1的张量
tensor_ones = tf.ones(shape=[2,3], dtype="float32")
# 创建正态分布随机张量
tensor_nd = tf.random_normal(shape=[10], #一维,10个元素
mean=1.7, # 中位数
stddev=0.2,
dtype="float32")
# 创建形状和tensor_ones一样,值全为0的张量
tensor_zeros_like = tf.zeros_like(tensor_ones)
with tf.Session() as sess:
print(tensor_zeros.eval()) # eval表示在session中执行计算
print(tensor_ones.eval())
print(tensor_nd.eval())
print(tensor_zeros_like.eval())
1.3张量类型转换
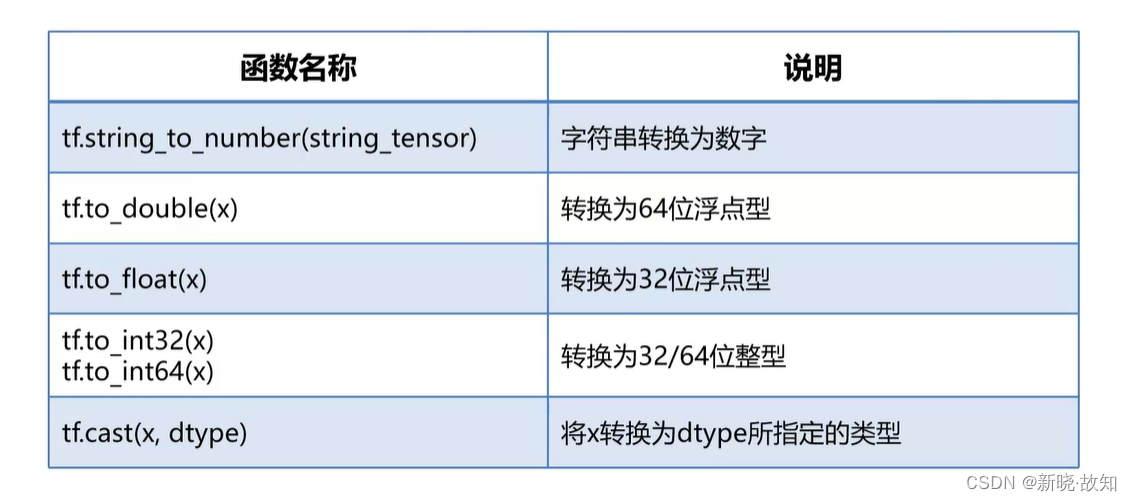
示例6:使用TensorFlow进行张量类型转换

# 06_cast.py
# 张量类型转换示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
tensor_ones = tf.ones(shape=[2,3], dtype="int32")
tensor_float = tf.constant([1.1, 2.2, 3.3])
with tf.Session() as sess:
print(tf.cast(tensor_ones, tf.float32).eval()) # 将tensor_ones转换为浮点型并打印
# print(tf.cast(tensor_float, tf.string).eval())
1.4占位符

示例7:占位符的使用

# 07_placeholder.py
# 占位符使用示例:占位符在使用时,必须传入参数
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# 定义两个占位符
plhd = tf.placeholder(tf.float32, [2, 3]) # 定义2行3列的占位符
plhd2 = tf.placeholder(tf.float32, [None, 3]) # N行3列占位符
plhd3 = tf.placeholder(tf.float32, [None, 4])
with tf.Session() as sess:
d = [[1, 2, 3],
[4, 5, 6]]
print(sess.run(plhd, feed_dict={
plhd:d})) # 执行占位符操作,需要传入数据
print(sess.run(plhd2, feed_dict={
plhd2:d})) # 定义为N行3列,执行时传入2行3列
# print(sess.run(plhd3, feed_dict={plhd3:d})) # 定义为N行4列,执行时传入2行3列
1.5张量形状改变

示例8:张量形状改变
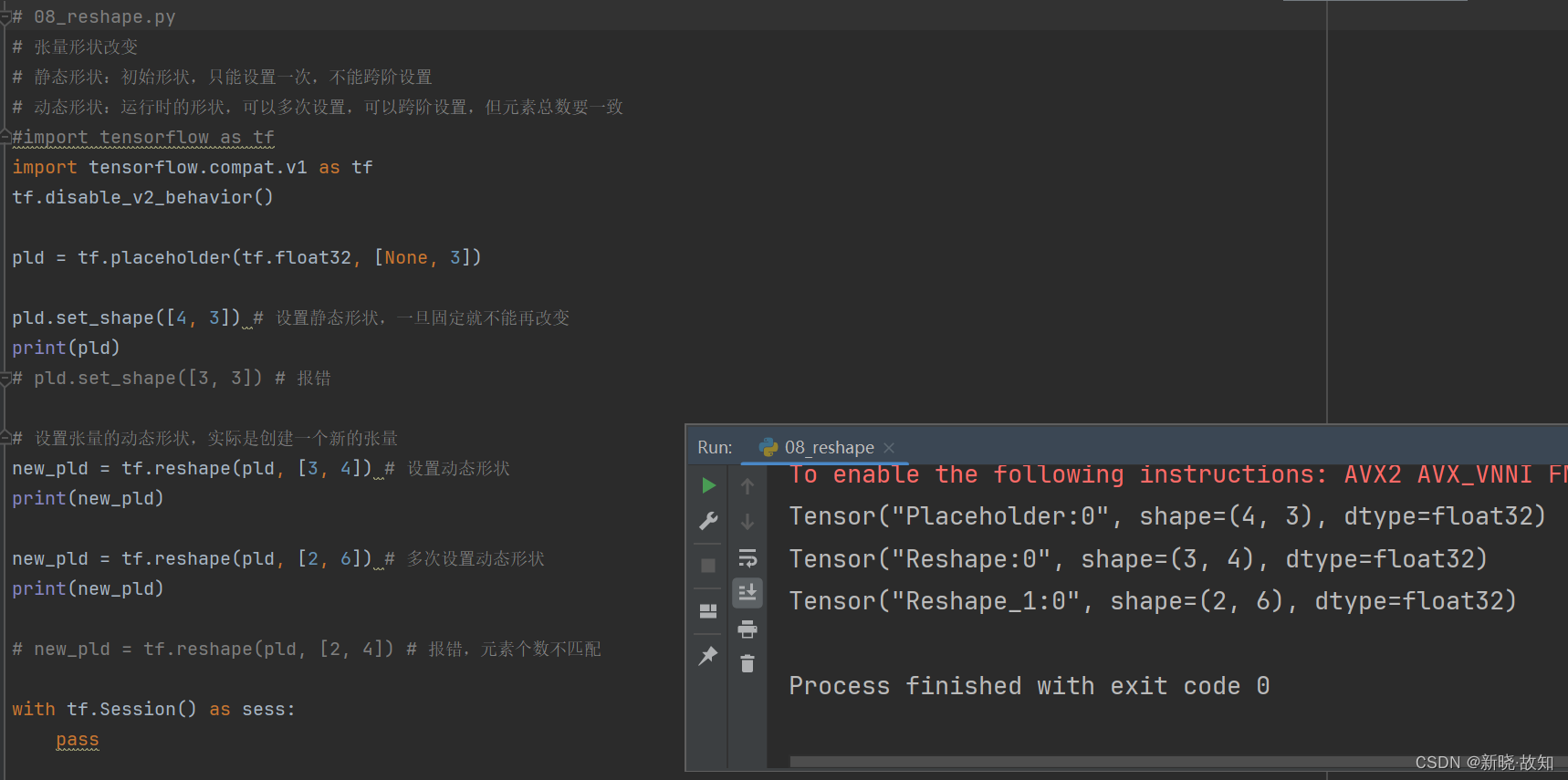
# 08_reshape.py
# 张量形状改变
# 静态形状:初始形状,只能设置一次,不能跨阶设置
# 动态形状:运行时的形状,可以多次设置,可以跨阶设置,但元素总数要一致
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
pld = tf.placeholder(tf.float32, [None, 3])
pld.set_shape([4, 3]) # 设置静态形状,一旦固定就不能再改变
print(pld)
# pld.set_shape([3, 3]) # 报错
# 设置张量的动态形状,实际是创建一个新的张量
new_pld = tf.reshape(pld, [3, 4]) # 设置动态形状
print(new_pld)
new_pld = tf.reshape(pld, [2, 6]) # 多次设置动态形状
print(new_pld)
# new_pld = tf.reshape(pld, [2, 4]) # 报错,元素个数不匹配
with tf.Session() as sess:
pass
1.6张量的数学计算

示例9:张量的数学计算
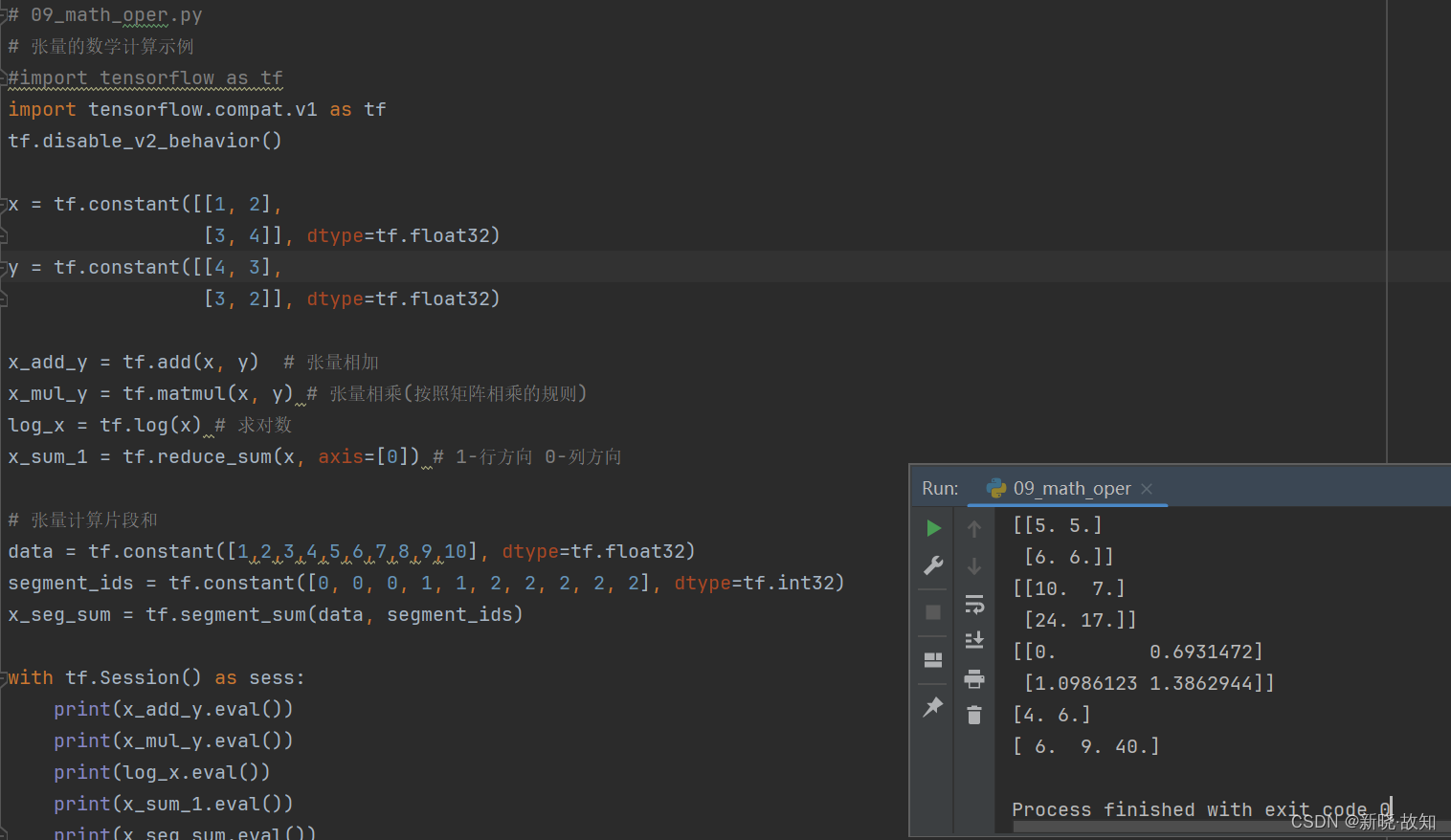
# 09_math_oper.py
# 张量的数学计算示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
x = tf.constant([[1, 2],
[3, 4]], dtype=tf.float32)
y = tf.constant([[4, 3],
[3, 2]], dtype=tf.float32)
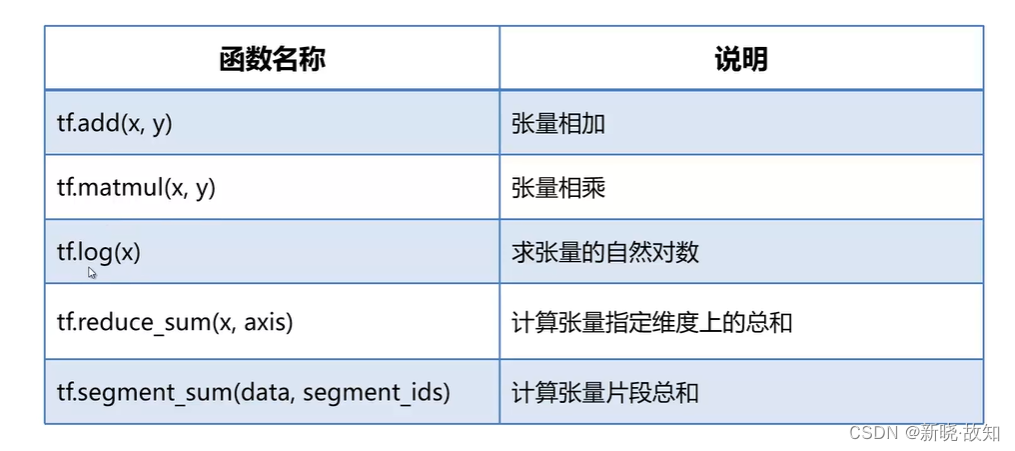
x_add_y = tf.add(x, y) # 张量相加
x_mul_y = tf.matmul(x, y) # 张量相乘(按照矩阵相乘的规则)
log_x = tf.log(x) # 求对数
x_sum_1 = tf.reduce_sum(x, axis=[0]) # 1-行方向 0-列方向
# 张量计算片段和
data = tf.constant([1,2,3,4,5,6,7,8,9,10], dtype=tf.float32)
segment_ids = tf.constant([0, 0, 0, 1, 1, 2, 2, 2, 2, 2], dtype=tf.int32)
x_seg_sum = tf.segment_sum(data, segment_ids)
with tf.Session() as sess:
print(x_add_y.eval())
print(x_mul_y.eval())
print(log_x.eval())
print(x_sum_1.eval())
print(x_seg_sum.eval())
1.7变量

示例10:变量使用
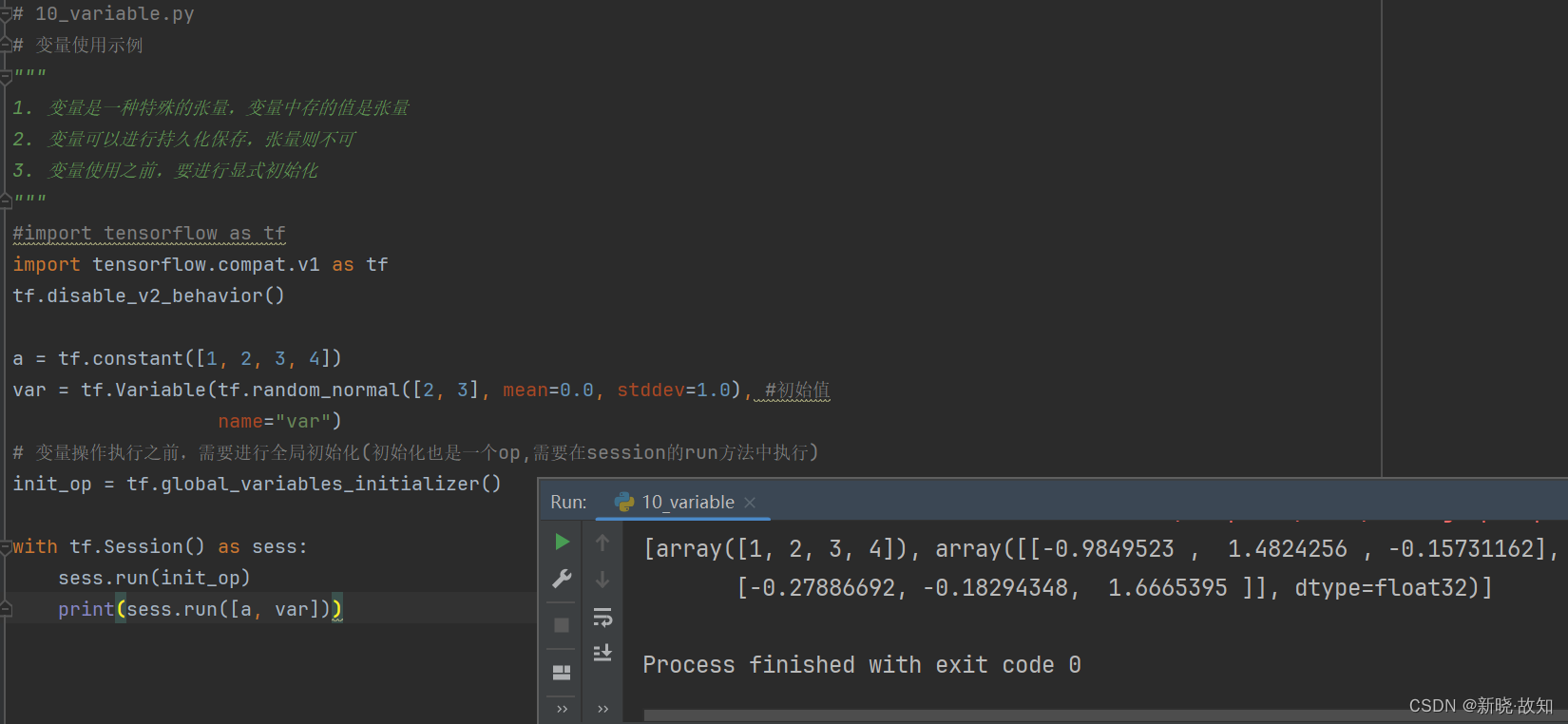
# 10_variable.py
# 变量使用示例
"""
1. 变量是一种特殊的张量,变量中存的值是张量
2. 变量可以进行持久化保存,张量则不可
3. 变量使用之前,要进行显式初始化
"""
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a = tf.constant([1, 2, 3, 4])
var = tf.Variable(tf.random_normal([2, 3], mean=0.0, stddev=1.0), #初始值
name="var")
# 变量操作执行之前,需要进行全局初始化(初始化也是一个op,需要在session的run方法中执行)
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print(sess.run([a, var]))
三、TensorFlow可视化
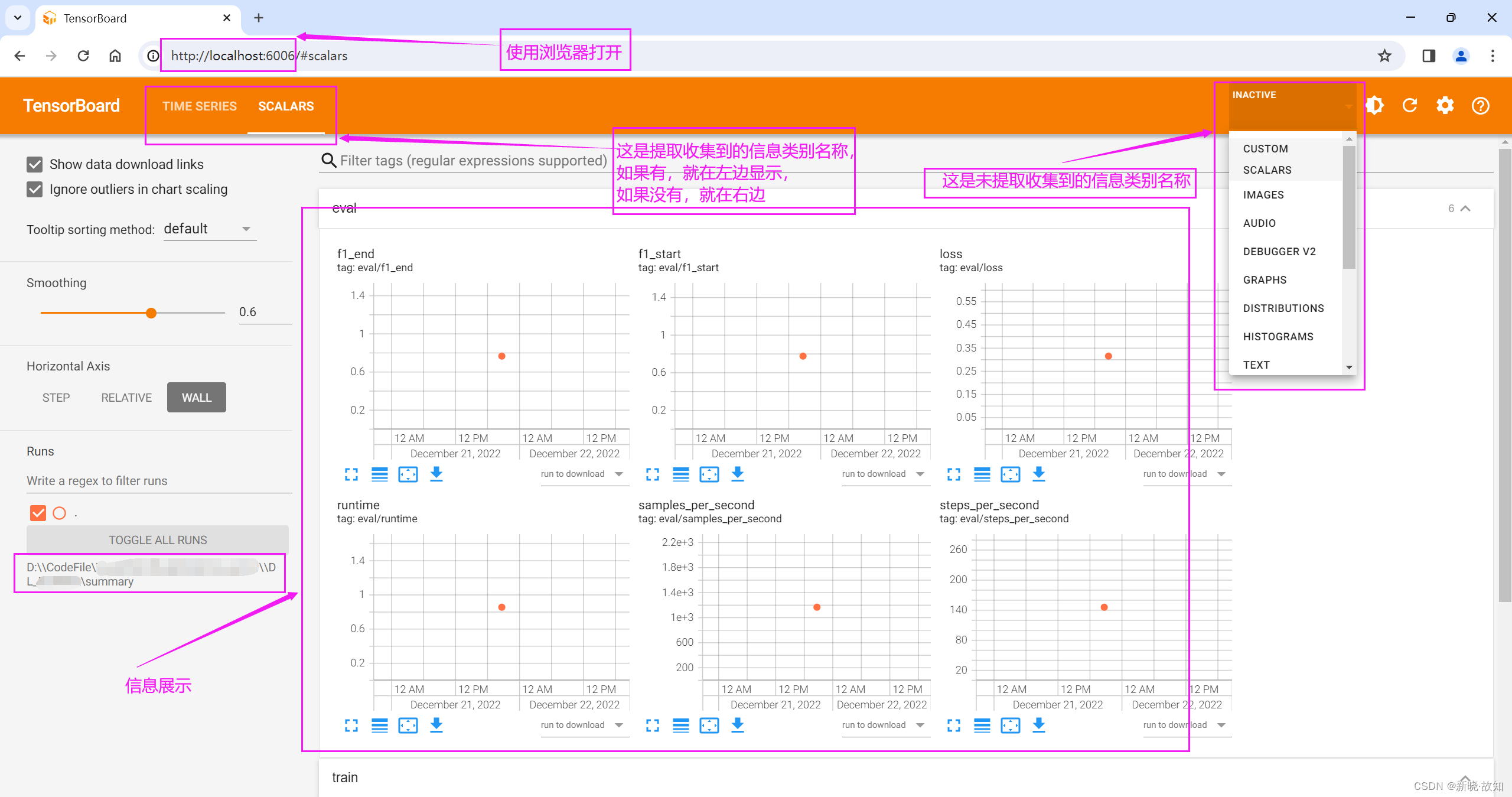
1.Tensorboard可视化
1.1什么是可视化

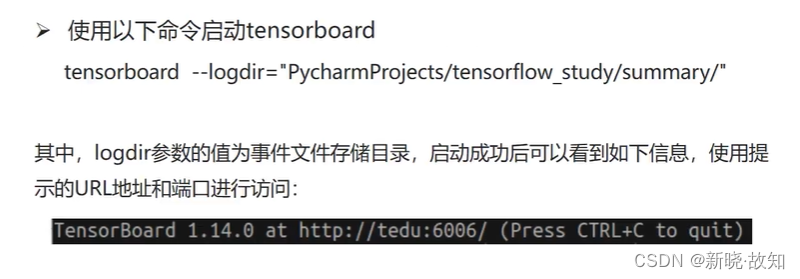
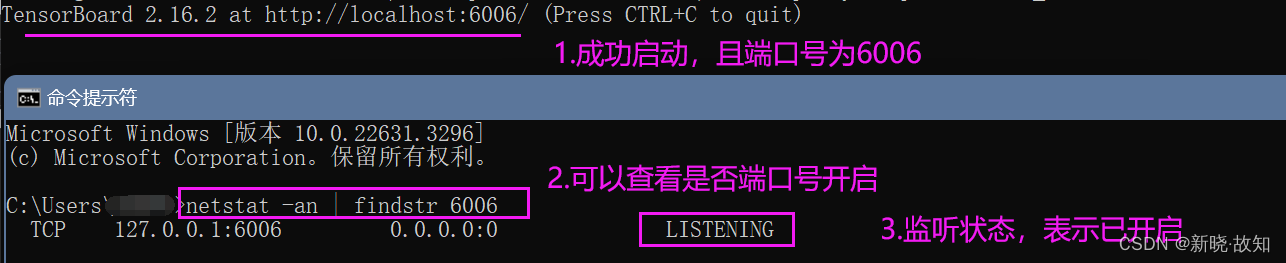
1.2启动Tensorboard
Windows环境下启动Tensorboard演示:
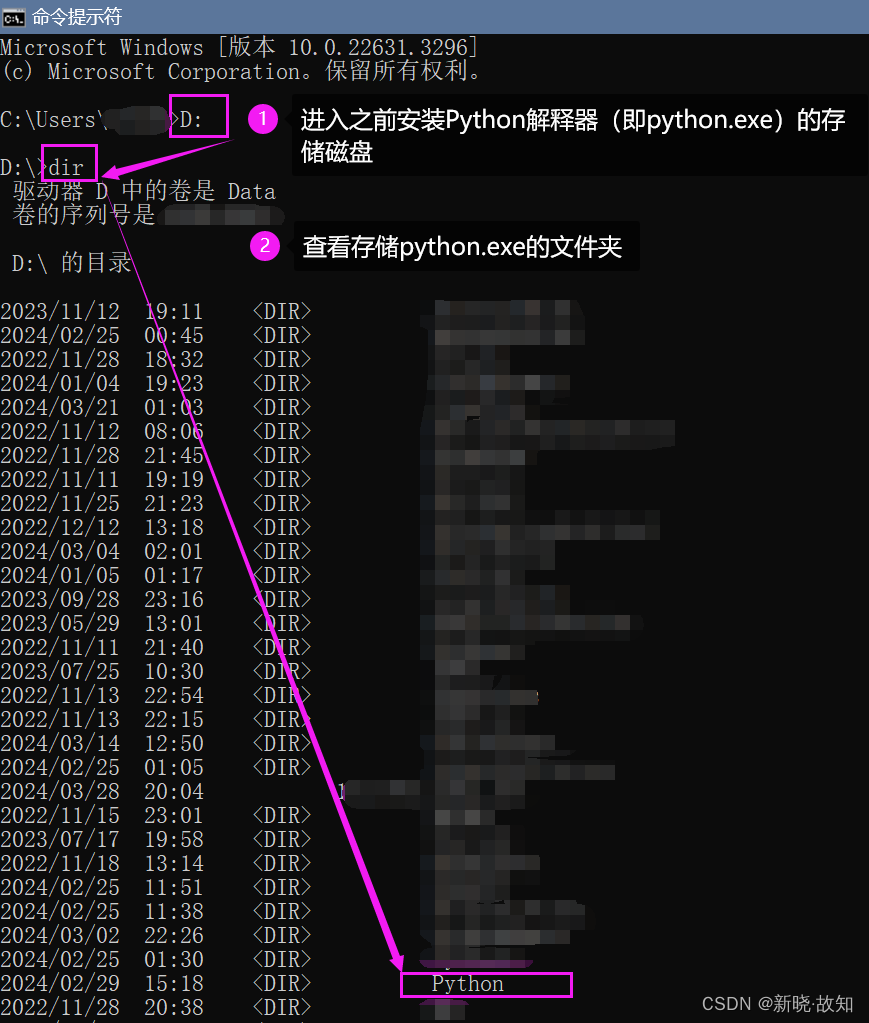
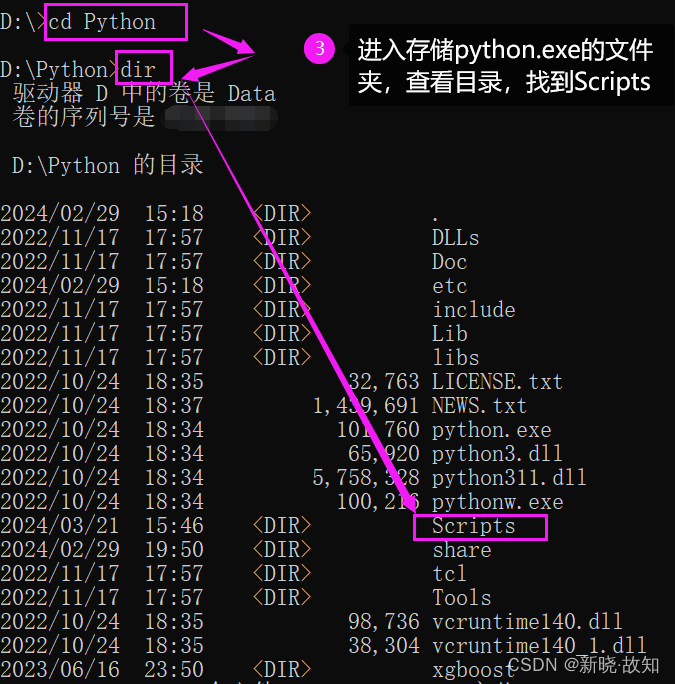
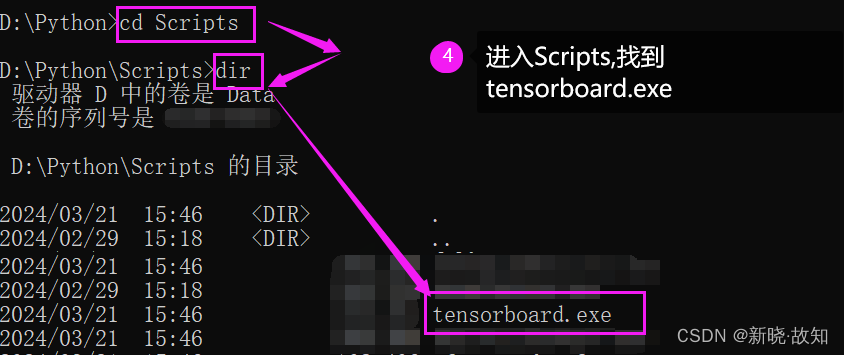


在Linux环境下可以直接使用:tensorboard --logdir=“文件路径”
例如:tensorboard --logdir=“PycharmProjects/tensorflow_study/summary/”
示例11:将图中的信息存入事件文件,并在tensorboard中显示示例
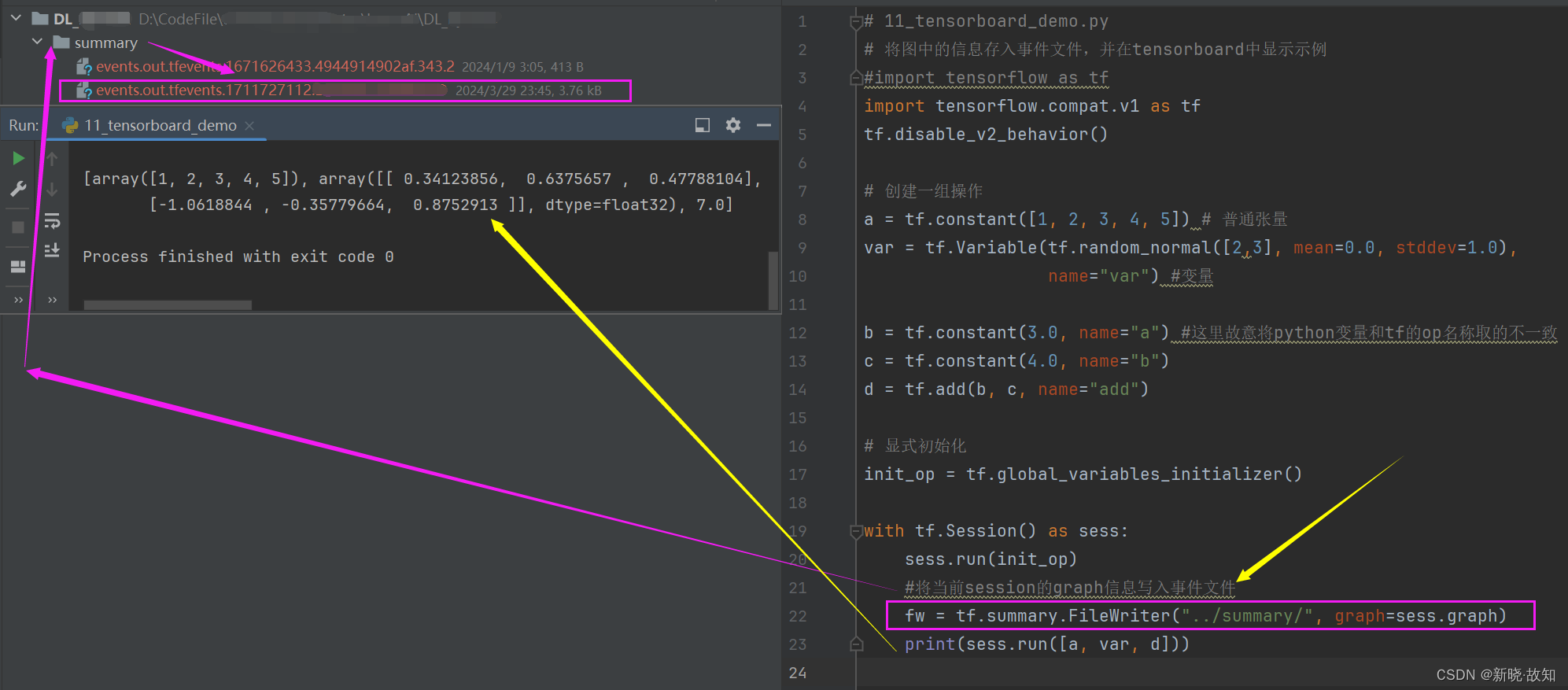
# 11_tensorboard_demo.py
# 将图中的信息存入事件文件,并在tensorboard中显示示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# 创建一组操作
a = tf.constant([1, 2, 3, 4, 5]) # 普通张量
var = tf.Variable(tf.random_normal([2,3], mean=0.0, stddev=1.0),
name="var") #变量
b = tf.constant(3.0, name="a") #这里故意将python变量和tf的op名称取的不一致
c = tf.constant(4.0, name="b")
d = tf.add(b, c, name="add")
# 显式初始化
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
#将当前session的graph信息写入事件文件
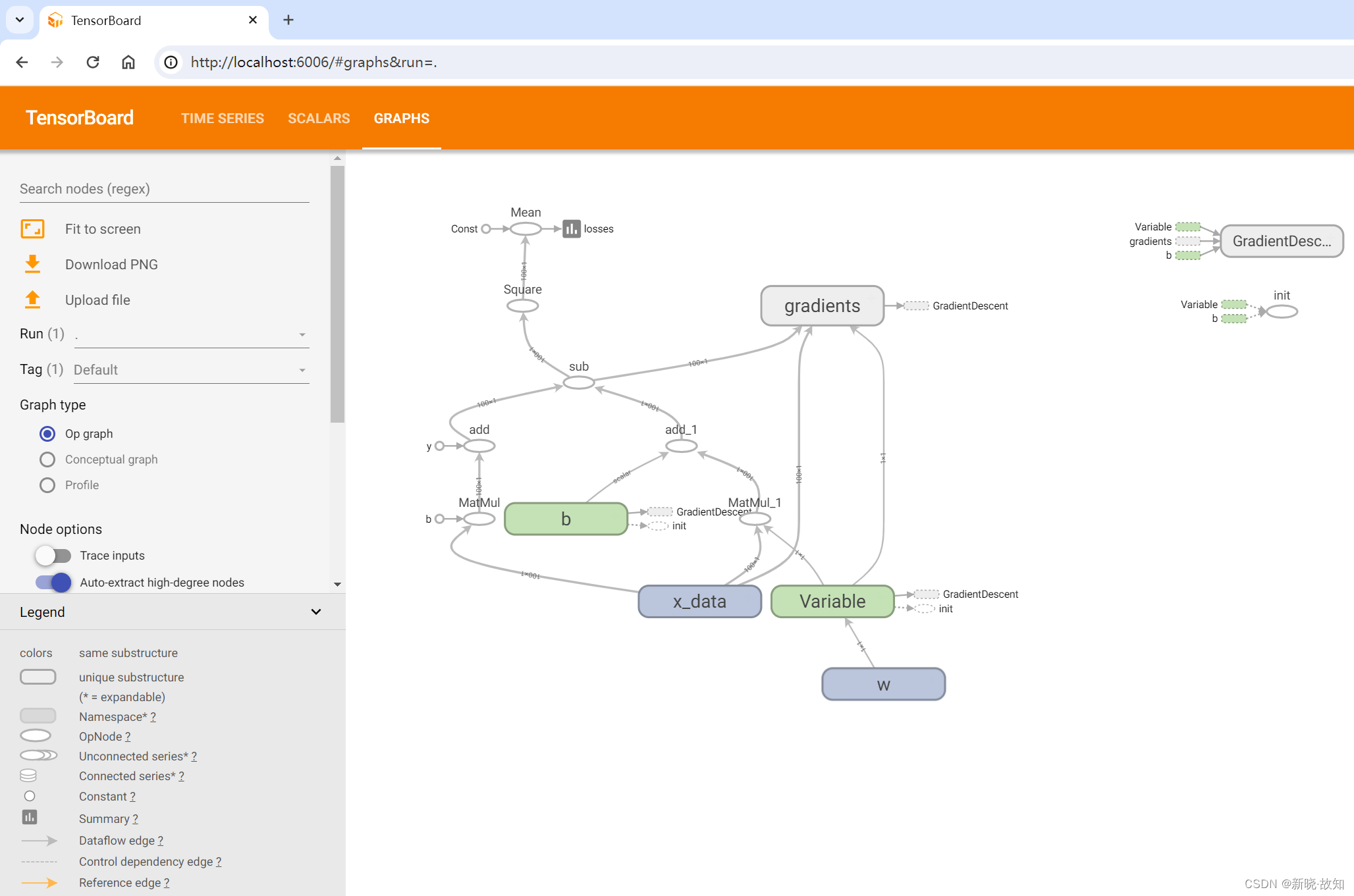
fw = tf.summary.FileWriter("../summary/", graph=sess.graph)
print(sess.run([a, var, d]))
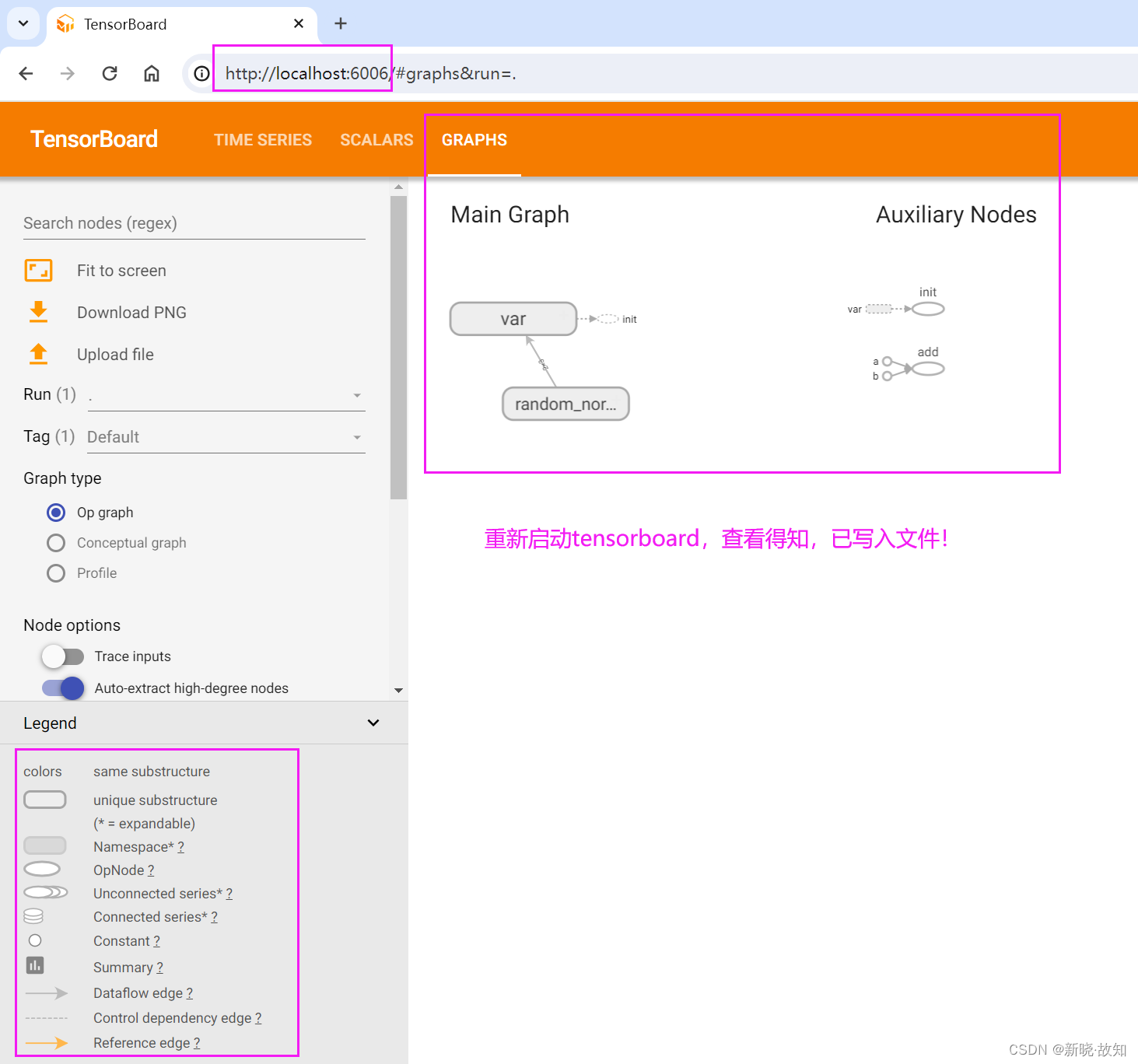
摘要与事件文件操作:

四、TensorFlow综合案例——实现线性回归

示例12:使用TensorFlow实现线性回归
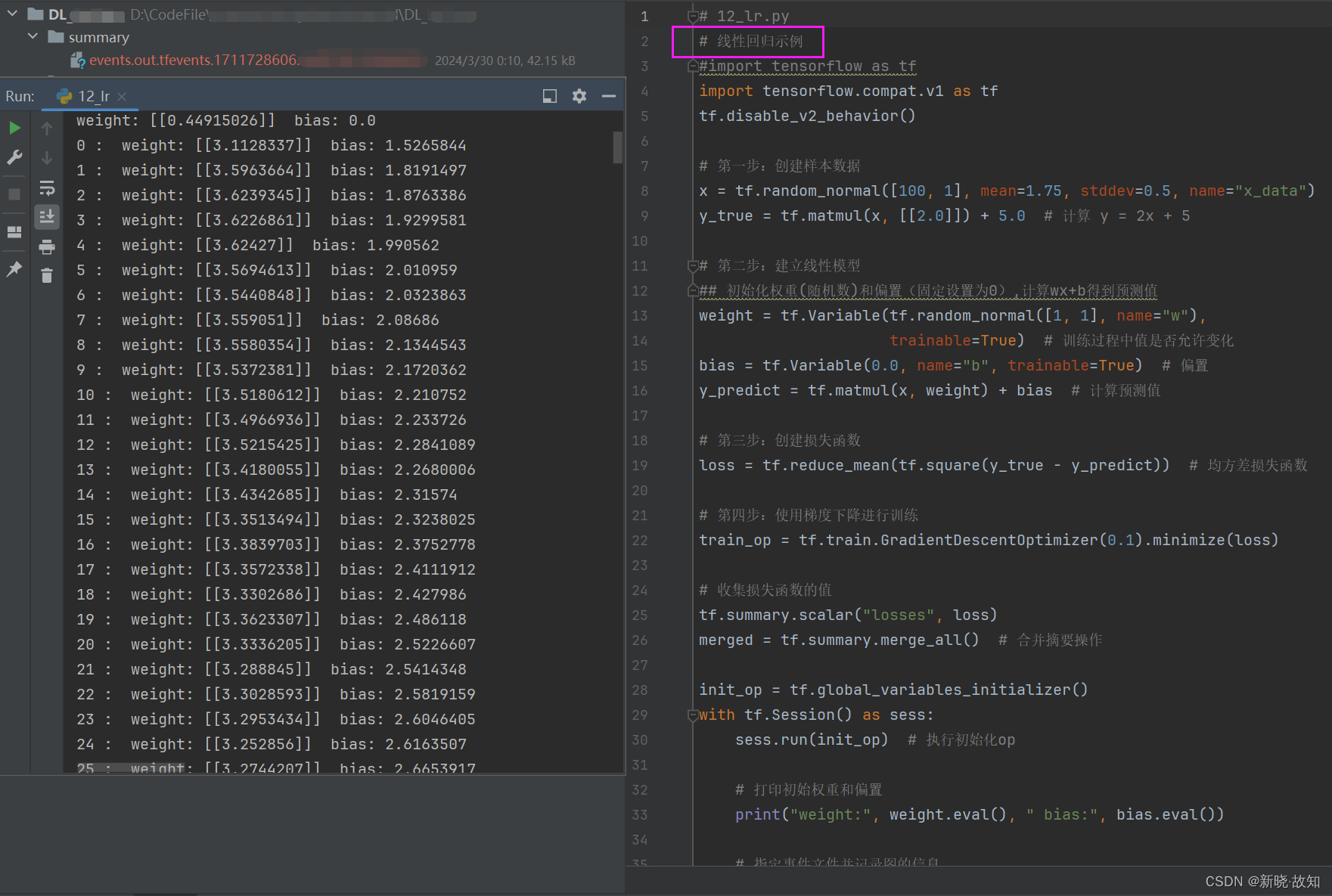
# 12_lr.py
# 线性回归示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# 第一步:创建样本数据
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5, name="x_data")
y_true = tf.matmul(x, [[2.0]]) + 5.0 # 计算 y = 2x + 5
# 第二步:建立线性模型
## 初始化权重(随机数)和偏置(固定设置为0),计算wx+b得到预测值
weight = tf.Variable(tf.random_normal([1, 1], name="w"),
trainable=True) # 训练过程中值是否允许变化
bias = tf.Variable(0.0, name="b", trainable=True) # 偏置
y_predict = tf.matmul(x, weight) + bias # 计算预测值
# 第三步:创建损失函数
loss = tf.reduce_mean(tf.square(y_true - y_predict)) # 均方差损失函数
# 第四步:使用梯度下降进行训练
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
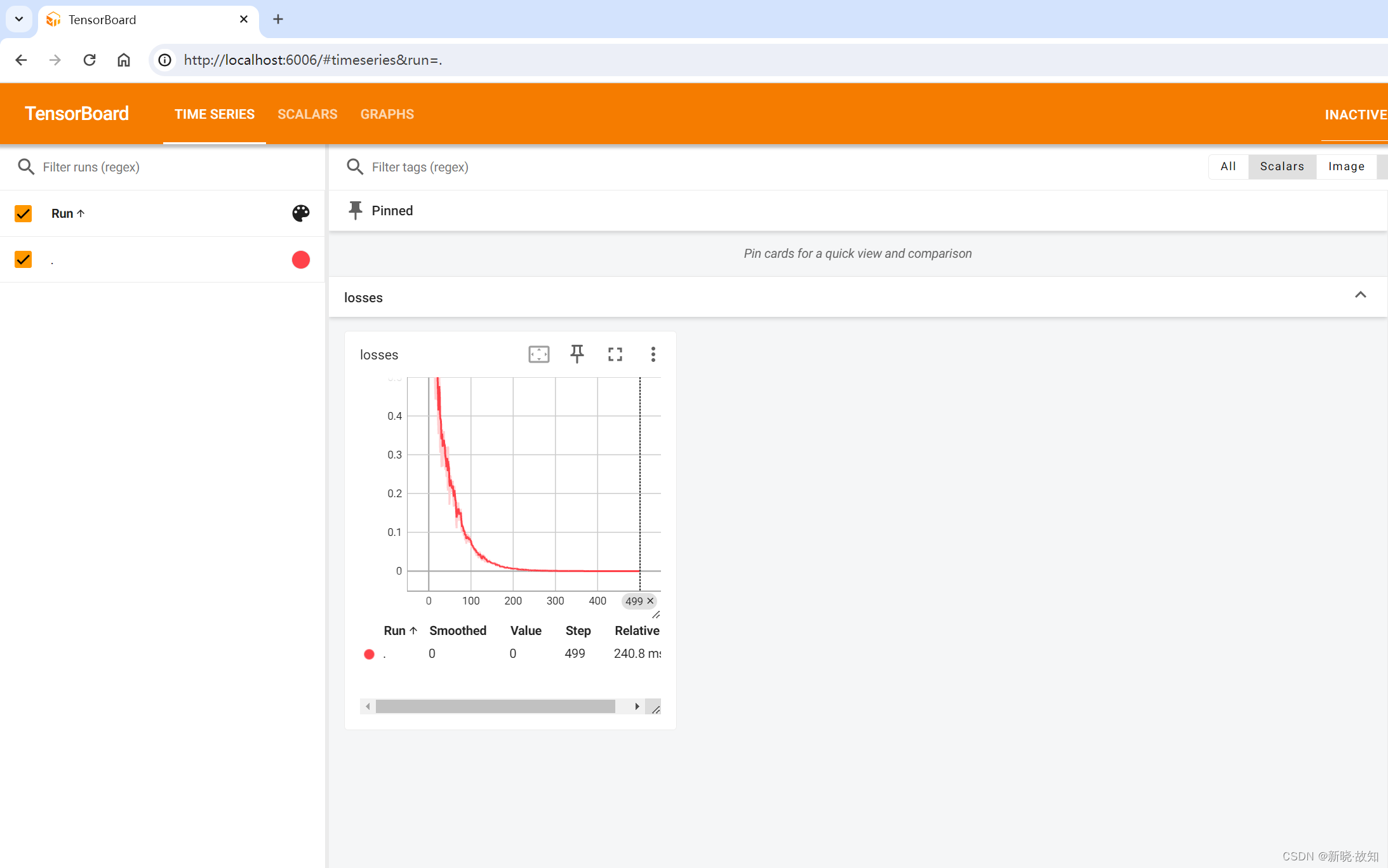
# 收集损失函数的值
tf.summary.scalar("losses", loss)
merged = tf.summary.merge_all() # 合并摘要操作
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op) # 执行初始化op
# 打印初始权重和偏置
print("weight:", weight.eval(), " bias:", bias.eval())
# 指定事件文件并记录图的信息
fw = tf.summary.FileWriter("../summary/", graph=sess.graph)
# 循环训练
for i in range(500):
sess.run(train_op) # 执行训练
summary = sess.run(merged) # 执行摘要合并操作
fw.add_summary(summary, i) # 写入事件文件
print(i, ":", " weight:", weight.eval(), " bias:", bias.eval())
启动Tensorboard运行:

五、TensorFlow数据读取
1.模型保存和加载
 模型保存和加载API:
模型保存和加载API:

示例13:线性回归的保存与加载
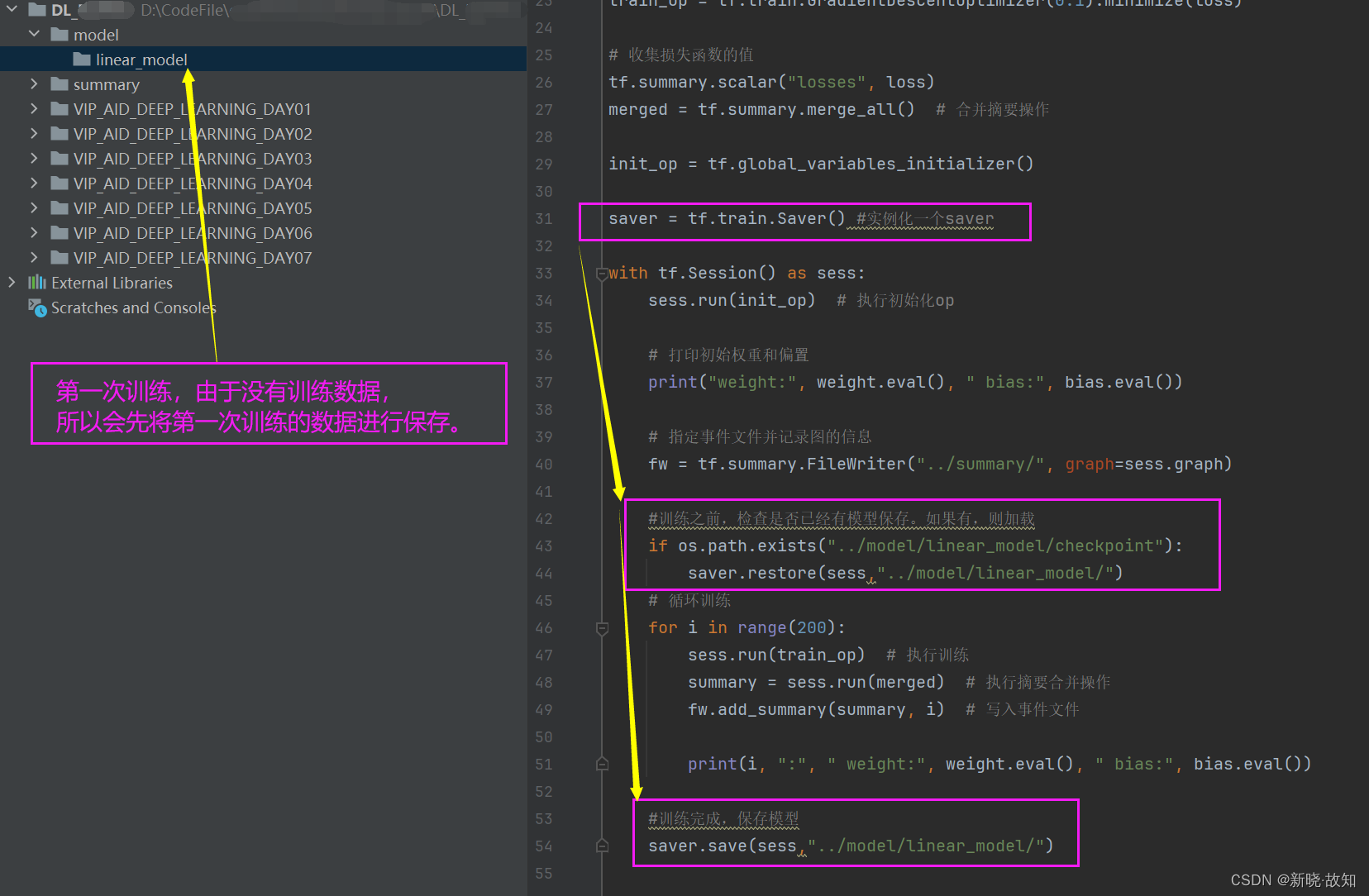
第一次训练:观察weight和bias的值
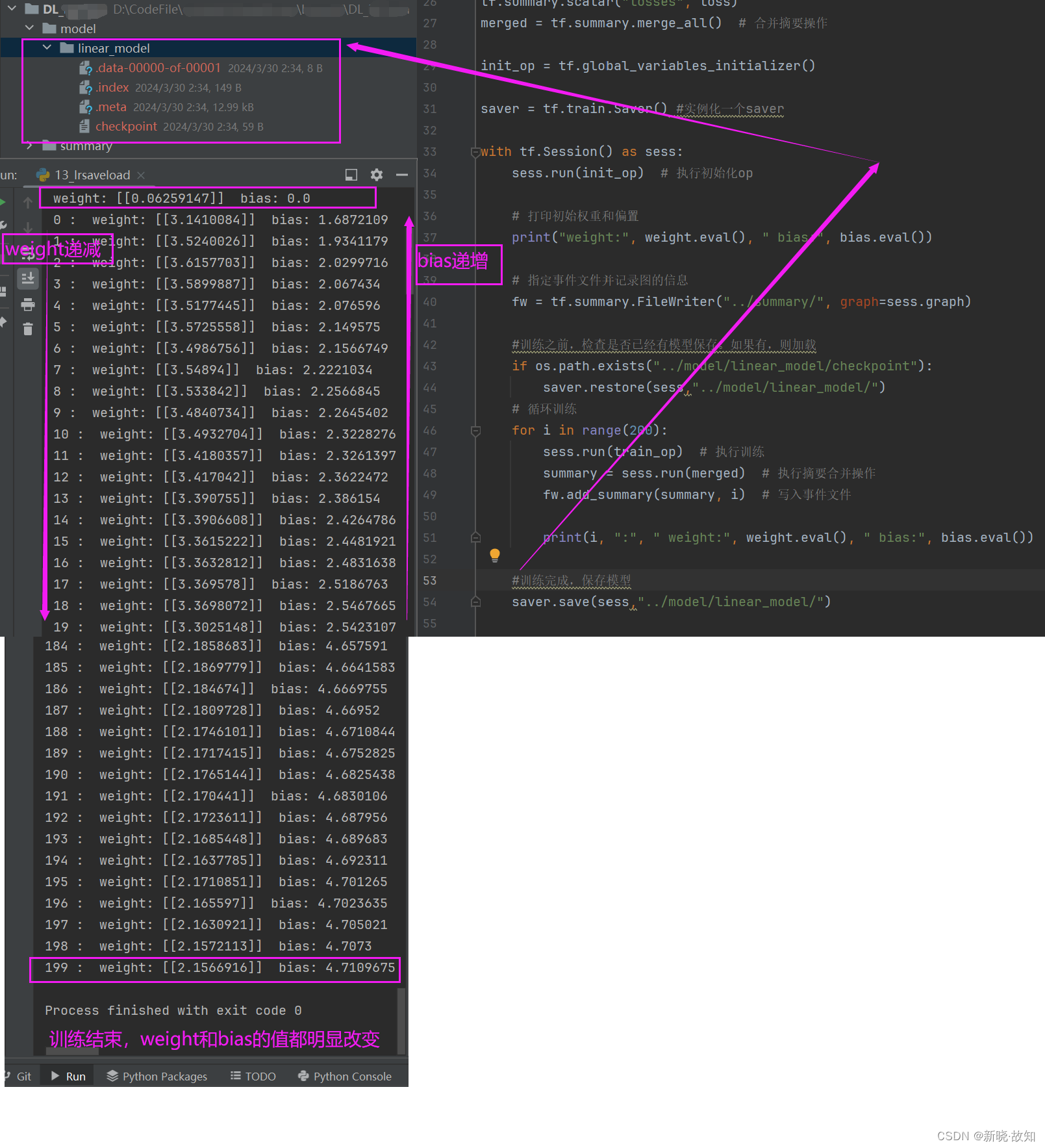
第二次训练:观察到weight和bias的初始值是第一次训练后的保存值!

继续训练,weight和bias的训练值将会更加接近预期值!
# 13_lrsaveload.py
# 线性回归示例,添加保存与加载模块
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import os
# 第一步:创建样本数据
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5, name="x_data")
y_true = tf.matmul(x, [[2.0]]) + 5.0 # 计算 y = 2x + 5
# 第二步:建立线性模型
## 初始化权重(随机数)和偏置(固定设置为0),计算wx+b得到预测值
weight = tf.Variable(tf.random_normal([1, 1], name="w"),
trainable=True) # 训练过程中值是否允许变化
bias = tf.Variable(0.0, name="b", trainable=True) # 偏置
y_predict = tf.matmul(x, weight) + bias # 计算预测值
# 第三步:创建损失函数
loss = tf.reduce_mean(tf.square(y_true - y_predict)) # 均方差损失函数
# 第四步:使用梯度下降进行训练
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 收集损失函数的值
tf.summary.scalar("losses", loss)
merged = tf.summary.merge_all() # 合并摘要操作
init_op = tf.global_variables_initializer()
saver = tf.train.Saver() #实例化一个saver
with tf.Session() as sess:
sess.run(init_op) # 执行初始化op
# 打印初始权重和偏置
print("weight:", weight.eval(), " bias:", bias.eval())
# 指定事件文件并记录图的信息
fw = tf.summary.FileWriter("../summary/", graph=sess.graph)
#训练之前,检查是否已经有模型保存。如果有,则加载
if os.path.exists("../model/linear_model/checkpoint"):
saver.restore(sess,"../model/linear_model/")
# 循环训练
for i in range(200):
sess.run(train_op) # 执行训练
summary = sess.run(merged) # 执行摘要合并操作
fw.add_summary(summary, i) # 写入事件文件
print(i, ":", " weight:", weight.eval(), " bias:", bias.eval())
#训练完成,保存模型
saver.save(sess,"../model/linear_model/")
2.数据读取
2.1文件读取机制


2.2文件读取API



六、TensorFlow数据读取案例
1.CSV文件读取
示例14:csv文件读取
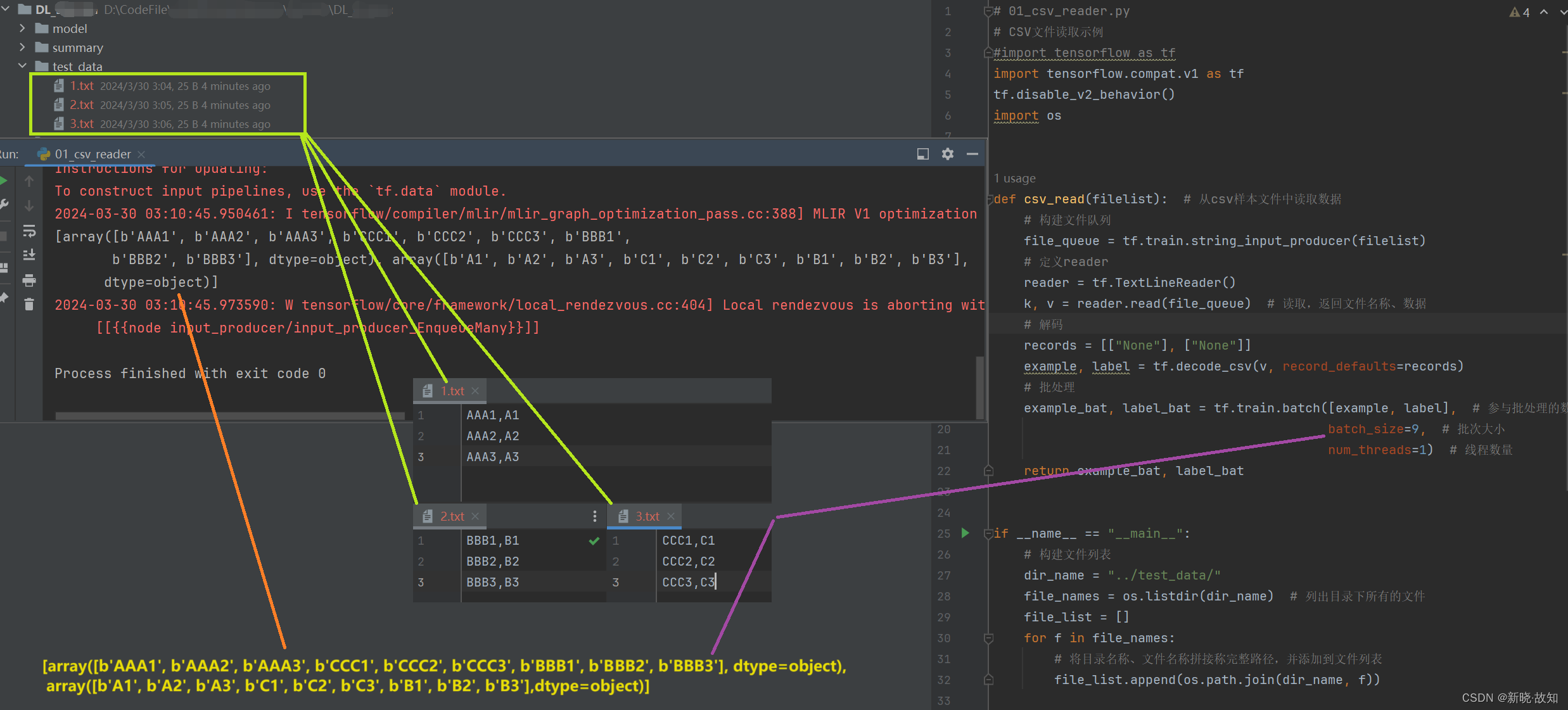
注:
(1)上述因为在读取的时候是做了随机化处理,读取顺序被打乱了。
(2)第一个数组为所有文本文件的第一列,第二个数组为所有文本文件的第二列。
(3)虽然读取顺序被打乱,但是第一列的数据和第二列的数据是一一对应的。
更改批次大小:
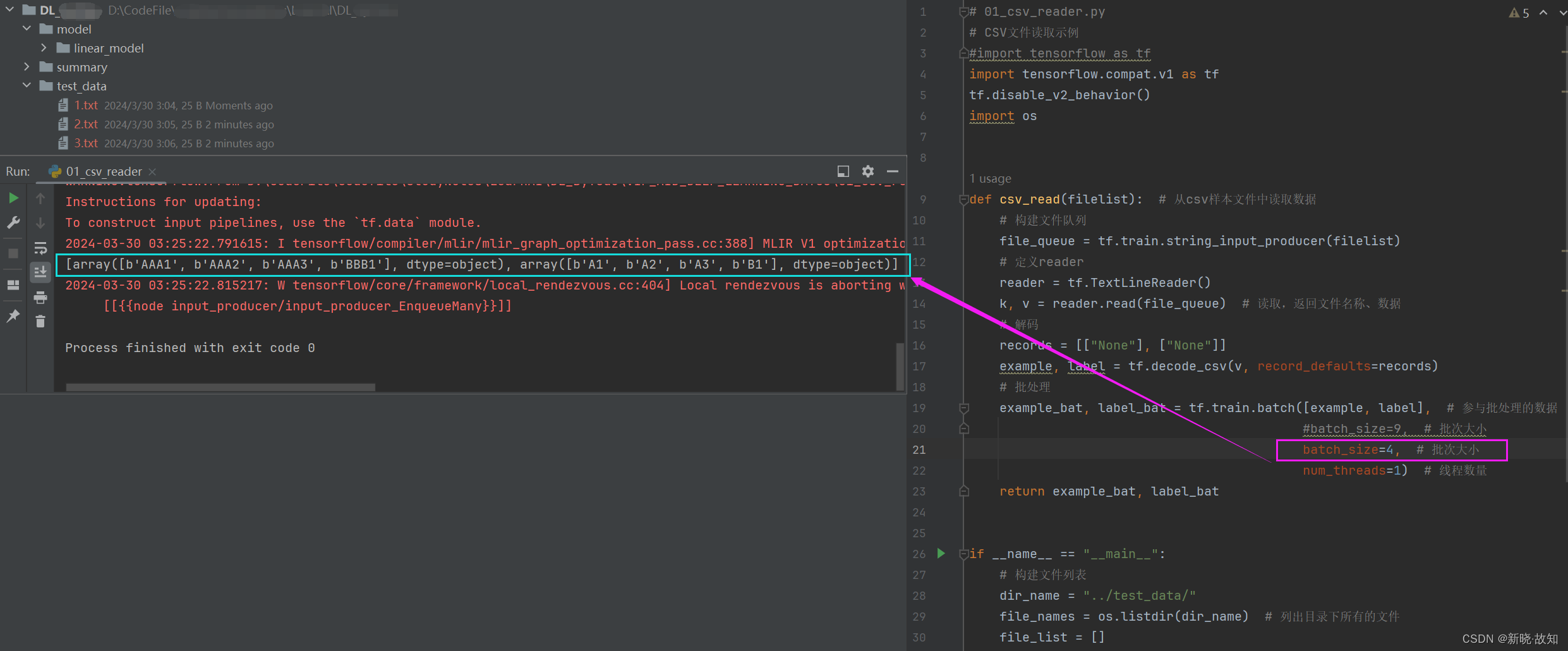
# 01_csv_reader.py
# CSV文件读取示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import os
def csv_read(filelist): # 从csv样本文件中读取数据
# 构建文件队列
file_queue = tf.train.string_input_producer(filelist)
# 定义reader
reader = tf.TextLineReader()
k, v = reader.read(file_queue) # 读取,返回文件名称、数据
# 解码
records = [["None"], ["None"]]
example, label = tf.decode_csv(v, record_defaults=records)
# 批处理
example_bat, label_bat = tf.train.batch([example, label], # 参与批处理的数据
#batch_size=9, # 批次大小
batch_size=4, # 批次大小
num_threads=1) # 线程数量
return example_bat, label_bat
if __name__ == "__main__":
# 构建文件列表
dir_name = "../test_data/"
file_names = os.listdir(dir_name) # 列出目录下所有的文件
file_list = []
for f in file_names:
# 将目录名称、文件名称拼接称完整路径,并添加到文件列表
file_list.append(os.path.join(dir_name, f))
example, label = csv_read(file_list) # 调用自定义函数,读取指定文件列表中的数据
# 开启Session,执行
with tf.Session() as sess:
coord = tf.train.Coordinator() # 定义线程协调器
threads = tf.train.start_queue_runners(sess, coord=coord)
print(sess.run([example, label])) # 执行操作
# 等待线程停止,并回收资源
coord.request_stop()
coord.join(threads)
2.图片文件的读取
2.1图片读取API


示例15:图像文件读取
# 02_img_reader.py
# 图像样本读取示例
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import os
# 图像样本读取函数
def img_read(filelist):
# 构建文件队列
file_queue = tf.train.string_input_producer(filelist)
# 定义reader
reader = tf.WholeFileReader()
k, v = reader.read(file_queue) # 读取整个文件内容
# 解码
img = tf.image.decode_jpeg(v)
# 批处理
img_resized = tf.image.resize(img, [200, 200]) # 将图像设置成200*200大小
img_resized.set_shape([200, 200, 3]) # 固定样本形状,批处理时对数据形状有要求
img_bat = tf.train.batch([img_resized],
batch_size=10,
num_threads=1)
return img_bat
if __name__ == "__main__":
# 构建文件列表
dir_name = "../test_img/"
file_names = os.listdir(dir_name)
file_list = []
for f in file_names:
# 将目录名、文件名拼接成完整路径放入文件列表中
file_list.append(os.path.join(dir_name, f))
imgs = img_read(file_list)
with tf.Session() as sess:
coord = tf.train.Coordinator() # 线程协调器
threads = tf.train.start_queue_runners(sess, coord=coord)
result = imgs.eval() # 调用函数,分批次读取样本
# 等待线程结束,并回收资源
coord.request_stop()
coord.join(threads)
# 显示图片
import matplotlib.pyplot as plt
plt.figure("Img Show", facecolor="lightgray")
for i in range(10): # 循环显示读取到的样本(批次读取,所以有多个样本)
plt.subplot(2, 5, i+1) # 显示子图, 2行5列的第i+1个子图
plt.xticks([])
plt.yticks([])
plt.imshow(result[i].astype("int32"))
plt.tight_layout()
plt.show()
3.深度学习平台数据读取总结
(1)深度学习平台对数据的读取,需要能够实现快速读取,因为训练的样本可能很多。
(2)需要能够实现随机的读取, 消除样本的顺序,对模型产生的影响。
(3)需要能够实现批量读取,分批处理。
七、TensorFlow综合案例——实现手写体识别
注:这里使用的是全连接模型作为分类器
1.MNIST数据集
MNIST数据集地址链接:http://yann.lecun.com/exdb/mnist/
任务目标:

2.网络结构
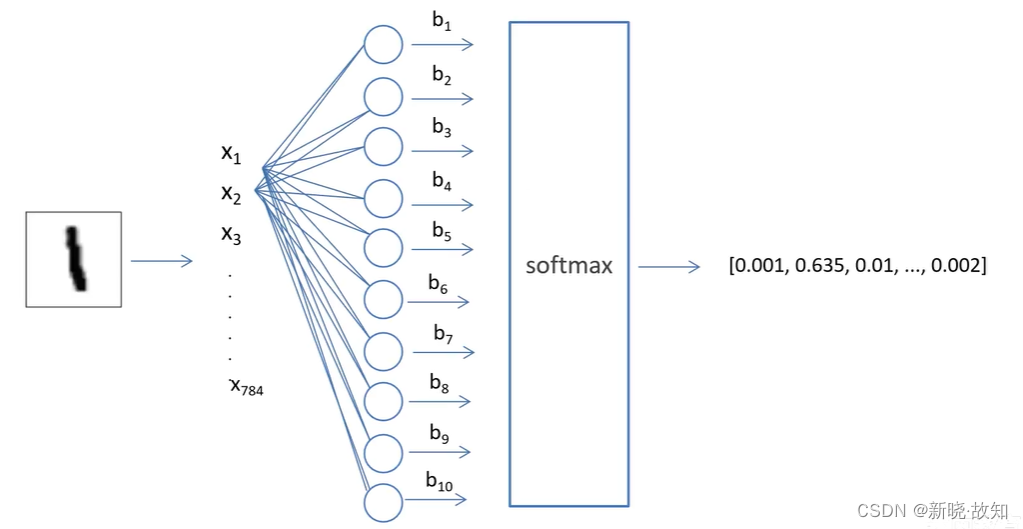
(输入:28x28)
3.相关API

示例16:mnist数据集手写数字识别
一些bug原因:
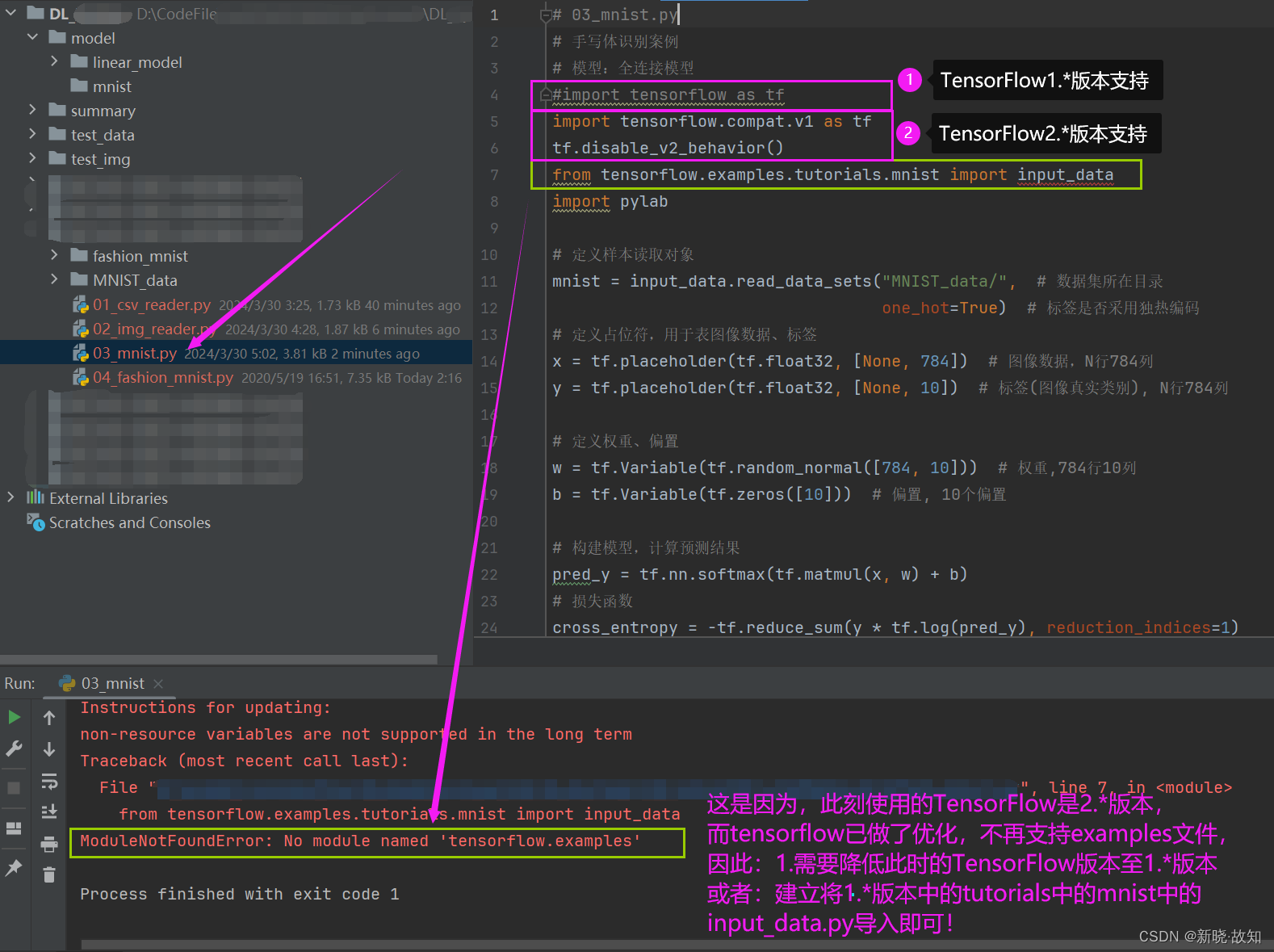
解决办法:
注:由于目前TensorFlow的最新版本是2.x,因此在代码中有一些bug是新版本不再支持1.x版本的调用方式。
“如果你正在使用的是 TensorFlow 2.x 版本,tensorflow.examples 已经不存在。TensorFlow 2.x 重构了许多组件,并引入了 Keras 作为主要接口,tensorflow.examples 中的许多内容已经迁移到其他位置或被新的 API 替代。”
解决办法:
(1)使用新的调用方式
(2)降低TensorFlow版本
(3)添加需要的代码包等
本次采用添加需要的代码包作为演示:
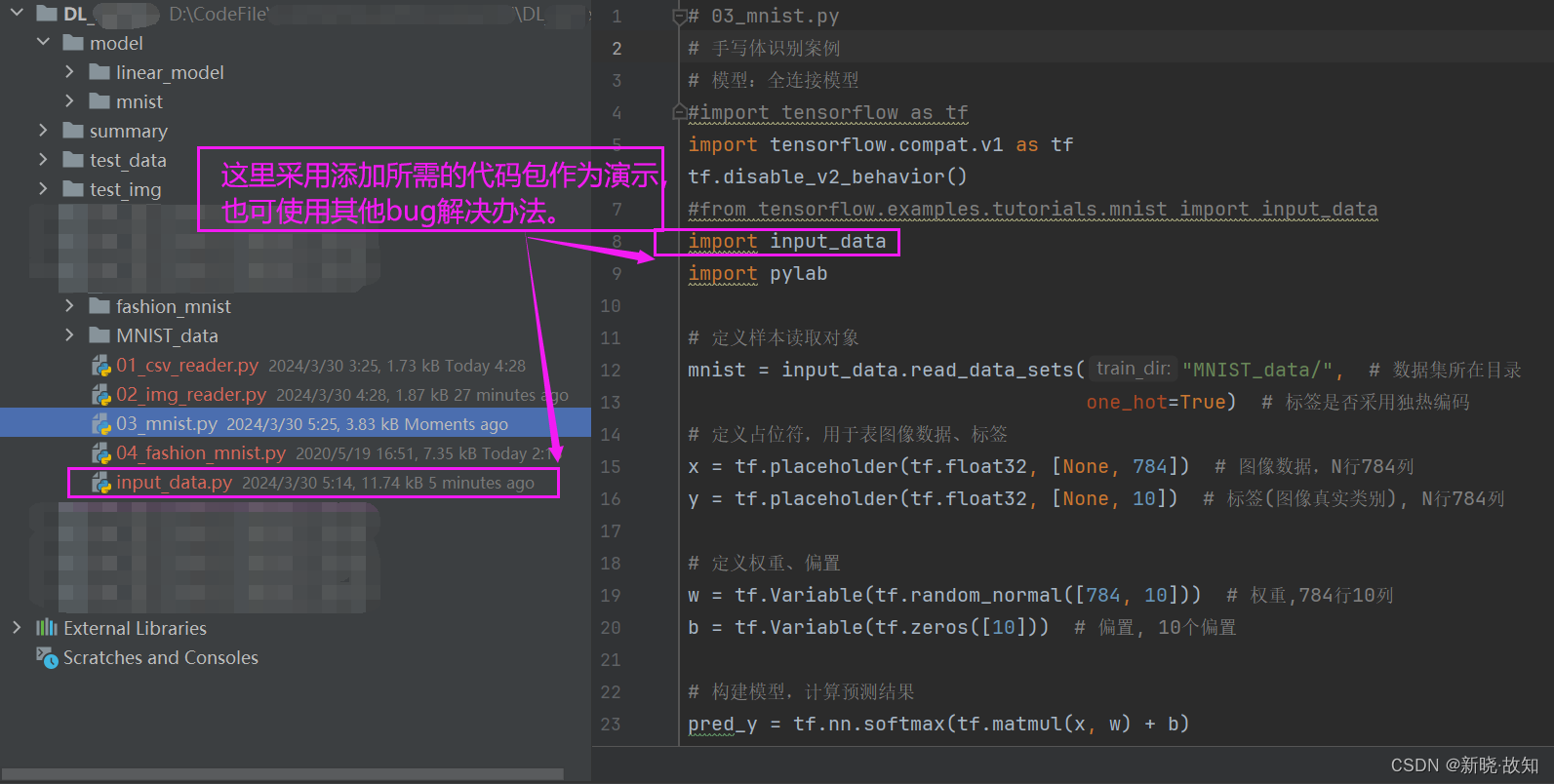
训练结果:
(这里是随机选取两张图片进行训练预测)
预测数字:
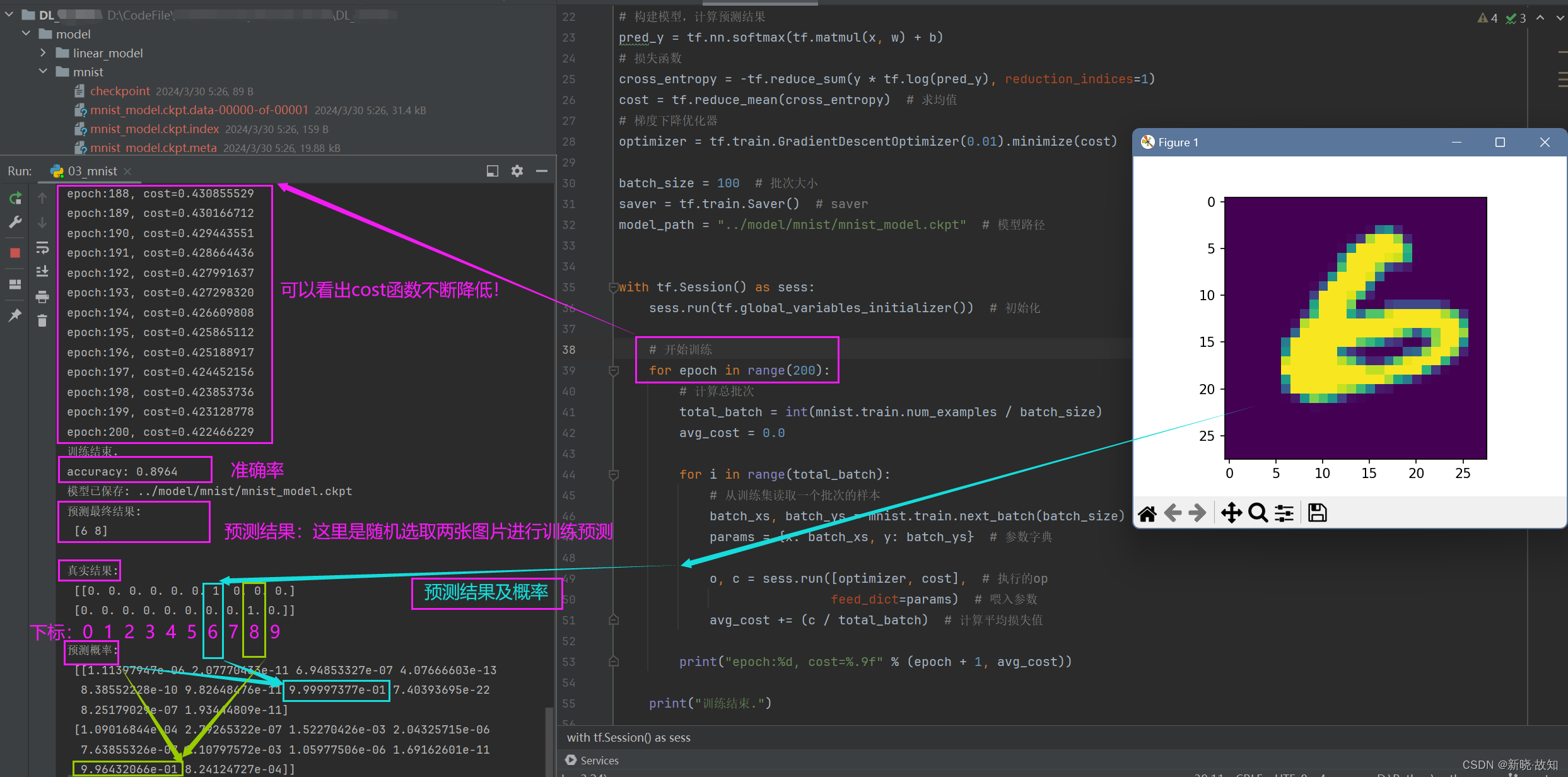
另一个预测数字:
注释训练模块代码,直接使用前次训练模型进行预测:
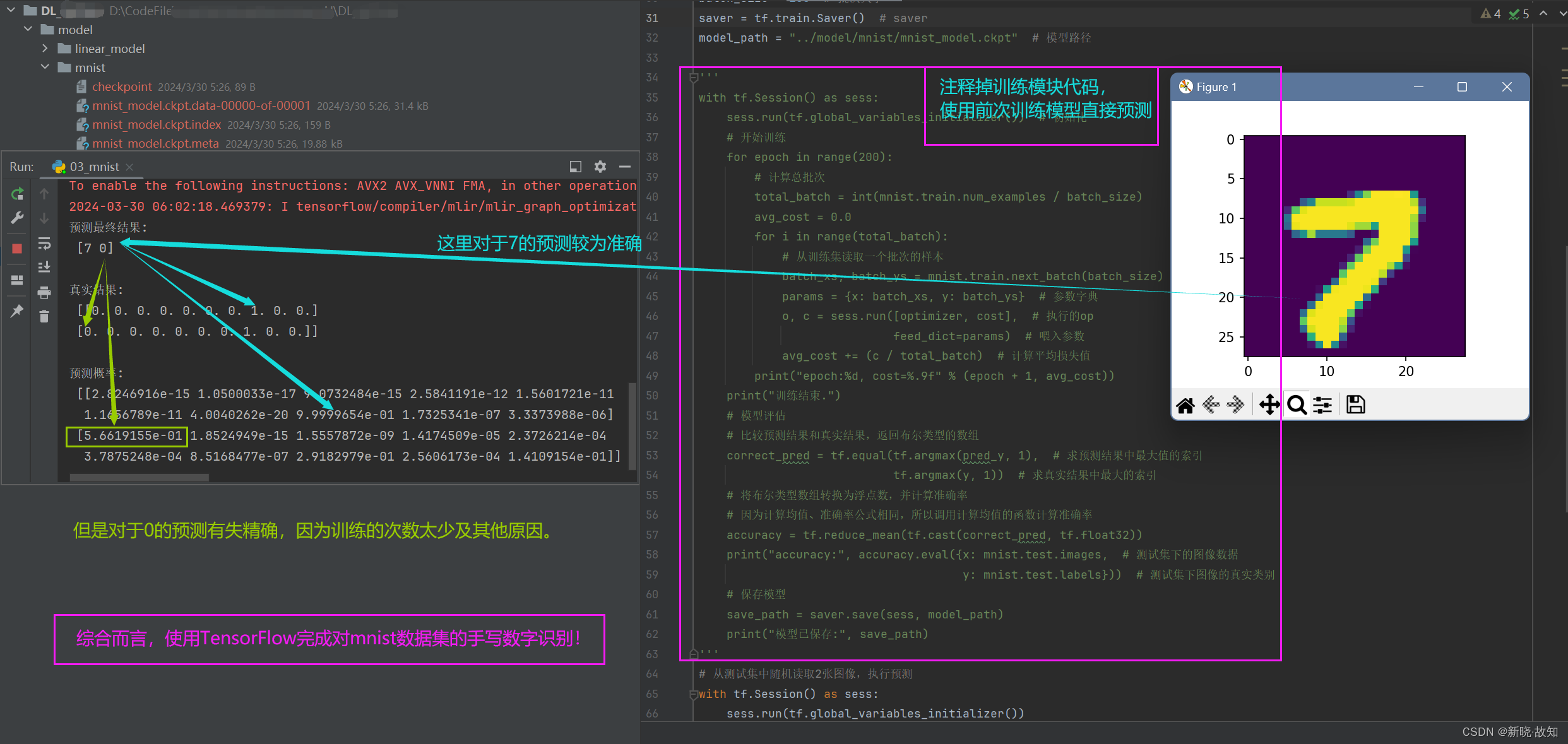
另一个预测数字:
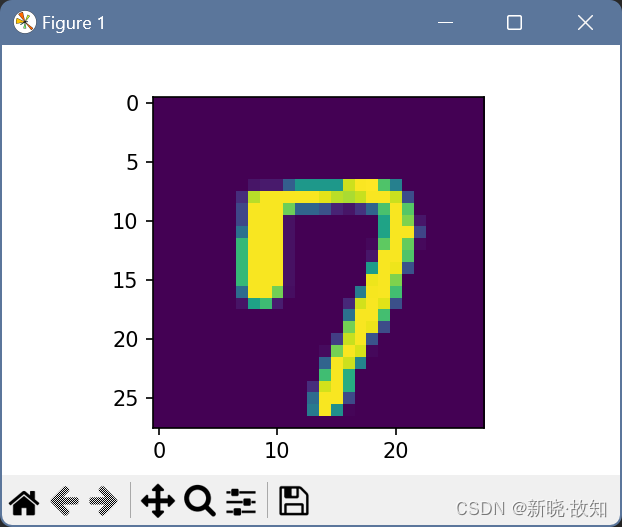
可以看出,另一个数字预测有失精确,但多加训练和调整参数/权重,可以提高精确度!
# 03_mnist.py
# 手写体识别案例
# 模型:全连接模型
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
#from tensorflow.examples.tutorials.mnist import input_data
import input_data
import pylab
# 定义样本读取对象
mnist = input_data.read_data_sets("MNIST_data/", # 数据集所在目录
one_hot=True) # 标签是否采用独热编码
# 定义占位符,用于表图像数据、标签
x = tf.placeholder(tf.float32, [None, 784]) # 图像数据,N行784列
y = tf.placeholder(tf.float32, [None, 10]) # 标签(图像真实类别), N行784列
# 定义权重、偏置
w = tf.Variable(tf.random_normal([784, 10])) # 权重,784行10列
b = tf.Variable(tf.zeros([10])) # 偏置, 10个偏置
# 构建模型,计算预测结果
pred_y = tf.nn.softmax(tf.matmul(x, w) + b)
# 损失函数
cross_entropy = -tf.reduce_sum(y * tf.log(pred_y), reduction_indices=1)
cost = tf.reduce_mean(cross_entropy) # 求均值
# 梯度下降优化器
optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
batch_size = 100 # 批次大小
saver = tf.train.Saver() # saver
model_path = "../model/mnist/mnist_model.ckpt" # 模型路径
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 初始化
# 开始训练
for epoch in range(200):
# 计算总批次
total_batch = int(mnist.train.num_examples / batch_size)
avg_cost = 0.0
for i in range(total_batch):
# 从训练集读取一个批次的样本
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
params = {
x: batch_xs, y: batch_ys} # 参数字典
o, c = sess.run([optimizer, cost], # 执行的op
feed_dict=params) # 喂入参数
avg_cost += (c / total_batch) # 计算平均损失值
print("epoch:%d, cost=%.9f" % (epoch + 1, avg_cost))
print("训练结束.")
# 模型评估
# 比较预测结果和真实结果,返回布尔类型的数组
correct_pred = tf.equal(tf.argmax(pred_y, 1), # 求预测结果中最大值的索引
tf.argmax(y, 1)) # 求真实结果中最大的索引
# 将布尔类型数组转换为浮点数,并计算准确率
# 因为计算均值、准确率公式相同,所以调用计算均值的函数计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
print("accuracy:", accuracy.eval({
x: mnist.test.images, # 测试集下的图像数据
y: mnist.test.labels})) # 测试集下图像的真实类别
# 保存模型
save_path = saver.save(sess, model_path)
print("模型已保存:", save_path)
#注释训练模块代码,使用训练模型进行直接预测检验
'''
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 初始化
# 开始训练
for epoch in range(200):
# 计算总批次
total_batch = int(mnist.train.num_examples / batch_size)
avg_cost = 0.0
for i in range(total_batch):
# 从训练集读取一个批次的样本
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
params = {x: batch_xs, y: batch_ys} # 参数字典
o, c = sess.run([optimizer, cost], # 执行的op
feed_dict=params) # 喂入参数
avg_cost += (c / total_batch) # 计算平均损失值
print("epoch:%d, cost=%.9f" % (epoch + 1, avg_cost))
print("训练结束.")
# 模型评估
# 比较预测结果和真实结果,返回布尔类型的数组
correct_pred = tf.equal(tf.argmax(pred_y, 1), # 求预测结果中最大值的索引
tf.argmax(y, 1)) # 求真实结果中最大的索引
# 将布尔类型数组转换为浮点数,并计算准确率
# 因为计算均值、准确率公式相同,所以调用计算均值的函数计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
print("accuracy:", accuracy.eval({x: mnist.test.images, # 测试集下的图像数据
y: mnist.test.labels})) # 测试集下图像的真实类别
# 保存模型
save_path = saver.save(sess, model_path)
print("模型已保存:", save_path)
'''
# 从测试集中随机读取2张图像,执行预测
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.restore(sess, model_path) # 加载模型
# 从测试集中读取样本
batch_xs, batch_ys = mnist.test.next_batch(2)
output = tf.argmax(pred_y, 1) # 直接取出预测结果中的最大值
output_val, predv = sess.run([output, pred_y], # 执行的op
feed_dict={
x: batch_xs}) # 预测,所以不需要传入标签
print("预测最终结果:\n", output_val, "\n")
print("真实结果:\n", batch_ys, "\n")
print("预测概率:\n", predv, "\n")
# 显示图片
im = batch_xs[0] # 第一个测试样本
im = im.reshape(-1, 28) # 28列,-1表示经过计算的值
pylab.imshow(im)
pylab.show()
im = batch_xs[1] # 第二个测试样本
im = im.reshape(-1, 28) # 28列,-1表示经过计算的值
pylab.imshow(im)
pylab.show()
八、TensorFlow综合案例——实现服饰识别
注:这里开始采用卷积神经网络进行识别
1.数据集介绍
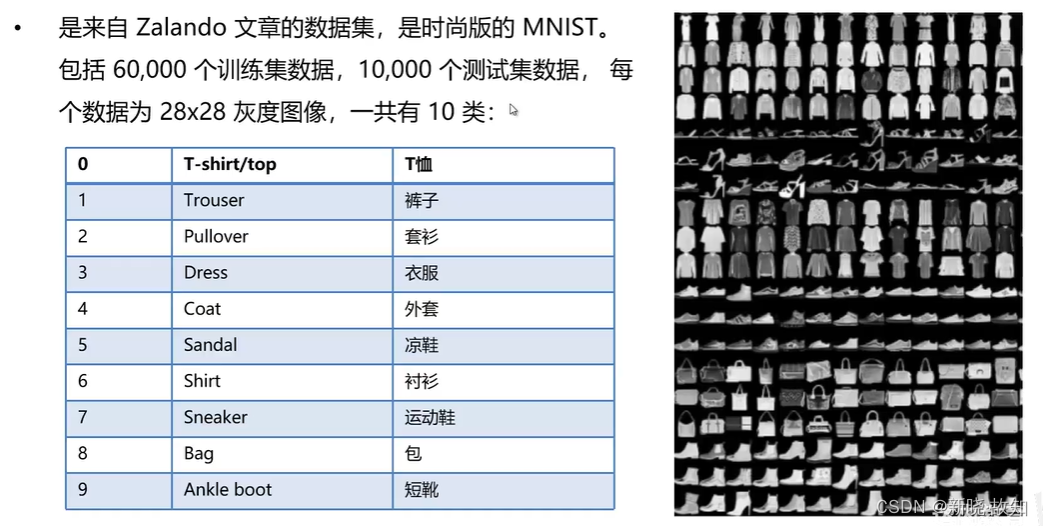
任务目标:

2.网络结构
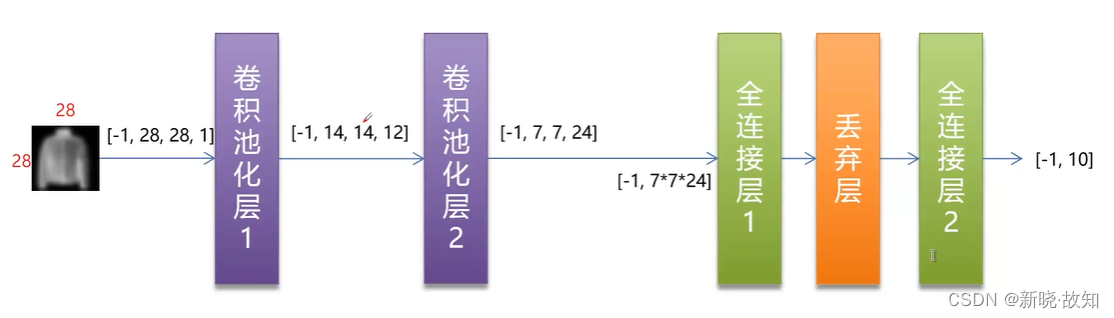
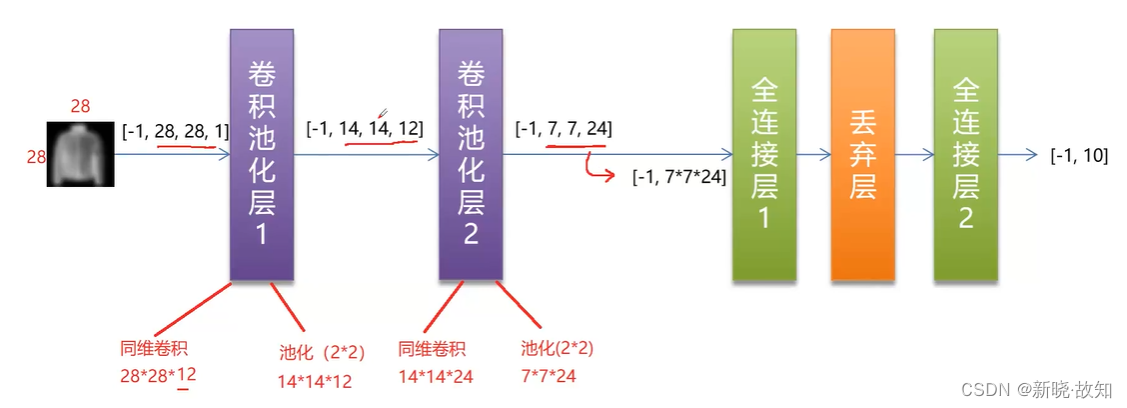
3.具体实现
这里采用面向对象的方式实现:

一些bug说明:
代码的逻辑一般是正确的,运行失败是TensorFlow2.x版本不再支持contrib,
解决尝试:
1.降低TensorFlow版本(这个不可行,目前已无法直接pip install 1.x版本)
2.使用contrib迁移到2.x的版本的APl:keras 重新编写代码,(这种方式需要重新编写代码,使用新的API编写方式。)
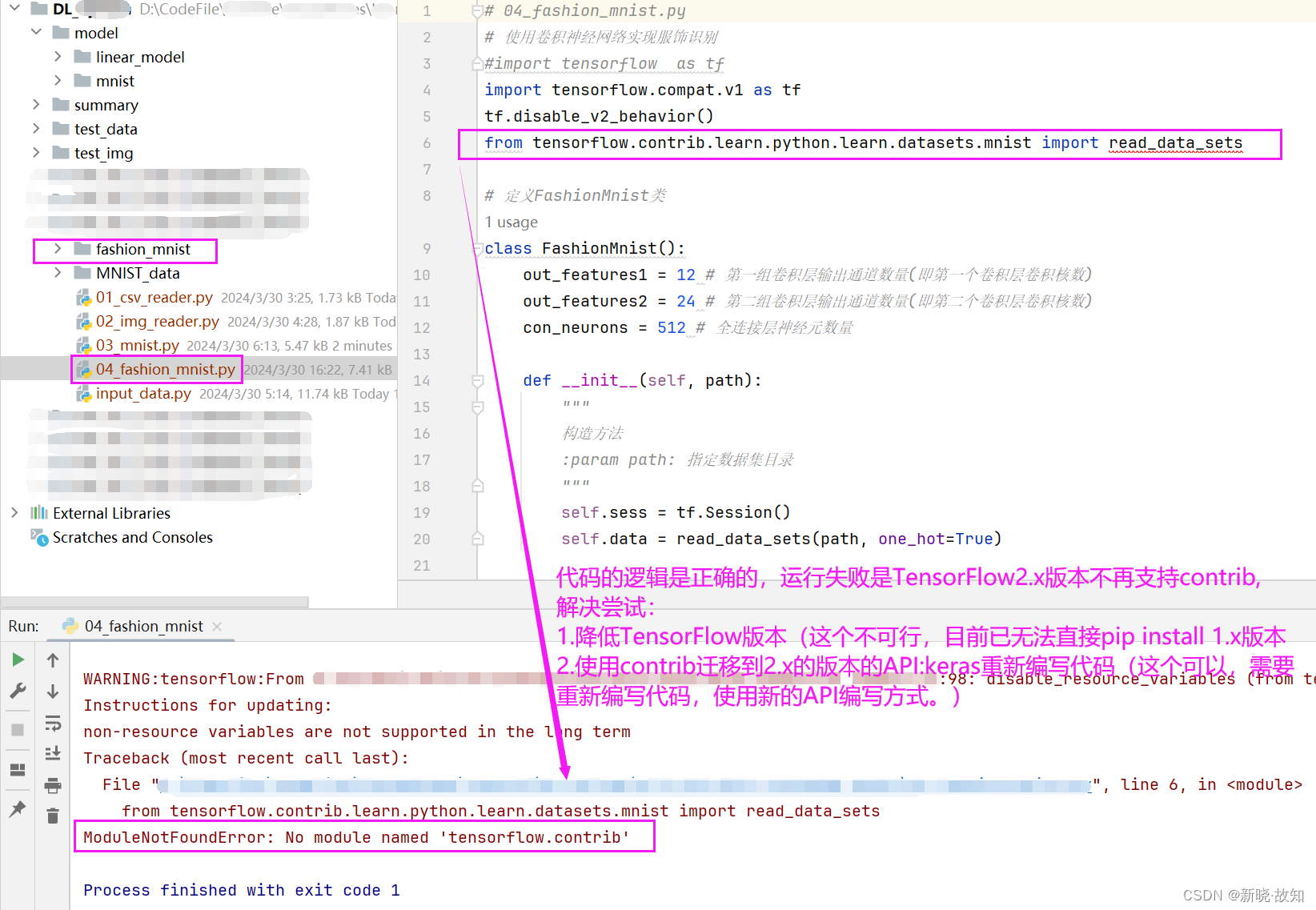

# 04_fashion_mnist.py
# 使用卷积神经网络实现服饰识别
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
# 定义FashionMnist类
class FashionMnist():
out_features1 = 12 # 第一组卷积层输出通道数量(即第一个卷积层卷积核数)
out_features2 = 24 # 第二组卷积层输出通道数量(即第二个卷积层卷积核数)
con_neurons = 512 # 全连接层神经元数量
def __init__(self, path):
"""
构造方法
:param path: 指定数据集目录
"""
self.sess = tf.Session()
self.data = read_data_sets(path, one_hot=True)
def init_weight_variable(self, shape):
"""
根据指定形状初始化权重
:param shape: 指定要初始化的变量的形状
:return: 返回经过初始化的变量
"""
inital = tf.truncated_normal(shape, stddev=0.1) # 截尾正态分布
return tf.Variable(inital)
def init_bias_variable(self, shape):
"""
初始化偏置
:param shape: 指定要初始化的变量的形状
:return: 返回经过初始化的变量
"""
inital = tf.constant(1.0, shape=shape)
return tf.Variable(inital)
def conv2d(self, x, w):
"""
二维卷积方法
:param x: 原始数据
:param w: 卷积核
:return: 返回卷积运算的结果
"""
# 卷积核: [高度, 宽度, 输入通道数, 输出通道数]
return tf.nn.conv2d(x, # 原始数据
w, # 卷积核
strides=[1, 1, 1, 1], # 各维度上的步长值
padding="SAME") # 输入矩阵和输出矩阵大小一样
def max_pool_2x2(self, x):
"""
定义池化方法
:param x: 原始数据
:return: 池化计算结果
"""
return tf.nn.max_pool(x,
ksize=[1, 2, 2, 1], # 池化区域大小
strides=[1, 2, 2, 1], # 各个维度上的步长值
padding="SAME")
def create_conv_pool_layer(self, input, input_features, out_features):
"""
定义卷积、激活、池化层
:param input: 原始数据
:param input_features:输入特征数量
:param out_features: 输出特征数量
:return: 卷积、激活、池化层运算结果
"""
filter = self.init_weight_variable([5, 5, input_features, out_features]) # 卷积核
b_conv = self.init_bias_variable([out_features]) # 偏置,卷积有多少输出就有多少个偏置
h_conv = tf.nn.relu(self.conv2d(input, filter) + b_conv) # 卷积,激活运算
h_pool = self.max_pool_2x2(h_conv) # 对卷积激活运算结果做池化
return h_pool
def create_fc_layer(self, h_pool_flat, input_features, con_neurons):
"""
创建全连接层
:param h_pool_flat: 输入数据,经过拉伸后的一维张量
:param input_features: 输入特征数量
:param con_neurons: 神经元数量(输出特征数量)
:return: 经过全连接计算后的结果
"""
w_fc = self.init_weight_variable([input_features, con_neurons]) # 权重
b_fc = self.init_bias_variable([con_neurons]) # 偏置
h_fc1 = tf.nn.relu(tf.matmul(h_pool_flat, w_fc) + b_fc) # 计算wx+b并做激活
return h_fc1
def build(self):
"""
组建CNN
:return:
"""
# 定义输入数据、标签数据的占位符
self.x = tf.placeholder(tf.float32, shape=[None, 784])
x_image = tf.reshape(self.x, [-1, 28, 28, 1]) # 变维成28*28单通道图像数据
self.y_ = tf.placeholder(tf.float32, shape=[None, 10]) # 标签, N个样本,每个样本10个类别对应的概率
# 第一组卷积池化
h_pool1 = self.create_conv_pool_layer(x_image, 1, self.out_features1)
# 第二层卷积池化
h_pool2 = self.create_conv_pool_layer(h_pool1, # 以上一个卷积池化层的输出作为输入
self.out_features1, # 输入特征数量,为上一层输出特征数量
self.out_features2) # 输出特征数量
# 全连接
h_pool2_flat_features = 7 * 7 * self.out_features2 # 计算特征点数量
h_pool2_flat = tf.reshape(h_pool2, [-1, h_pool2_flat_features]) # 拉伸成一维
h_fc = self.create_fc_layer(h_pool2_flat, # 输入
h_pool2_flat_features, # 输入特征数量
self.con_neurons) # 输出特征数量
# dropout(通过随机丢弃一定比例神经元参数更新,防止过拟合)
self.keep_prob = tf.placeholder("float") # 保存率
h_fc1_drop = tf.nn.dropout(h_fc, self.keep_prob)
# 输出层
w_fc = self.init_weight_variable([self.con_neurons, 10]) # 512行10列
b_fc = self.init_bias_variable([10]) # 10个偏置
y_conv = tf.matmul(h_fc1_drop, w_fc) + b_fc # 计算wx+b
# 计算准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1),
tf.argmax(self.y_, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 损失函数
loss_func = tf.nn.softmax_cross_entropy_with_logits(labels=self.y_, # 真实值
logits=y_conv) # 预测值
cross_entropy = tf.reduce_mean(loss_func)
# 优化器
optimizer = tf.train.AdamOptimizer(0.001)
self.train_step = optimizer.minimize(cross_entropy)
def train(self):
self.sess.run(tf.global_variables_initializer())
batch_size = 100 # 批次大小
print("begin training...")
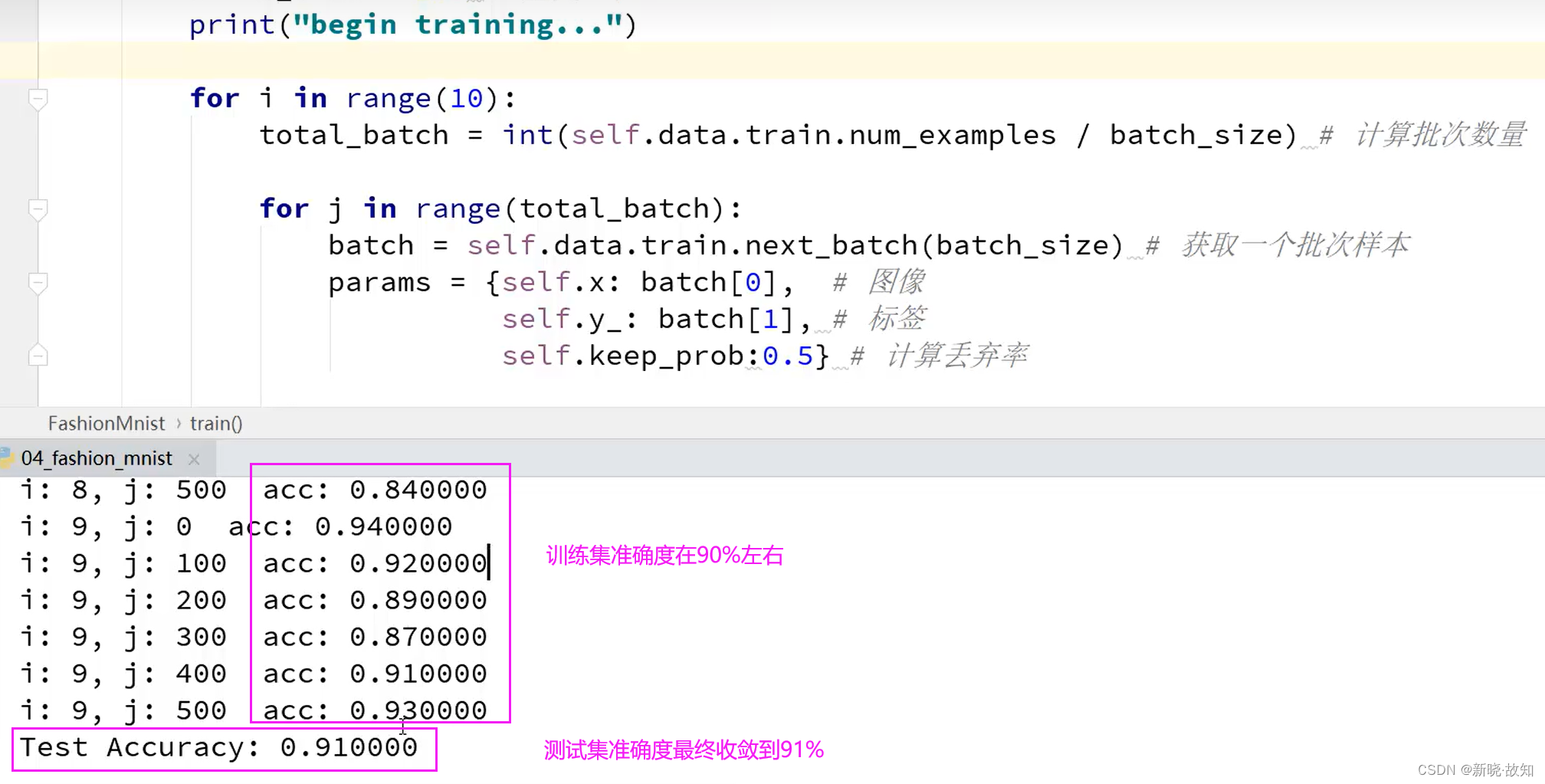
for i in range(10):
total_batch = int(self.data.train.num_examples / batch_size) # 计算批次数量
for j in range(total_batch):
batch = self.data.train.next_batch(batch_size) # 获取一个批次样本
params = {
self.x: batch[0], # 图像
self.y_: batch[1], # 标签
self.keep_prob:0.5} # 计算丢弃率
t, acc = self.sess.run([self.train_step, self.accuracy], # 执行的op
params)
if j % 100 == 0:
print("i: %d, j: %d acc: %f" % (i, j, acc))
def eval(self, x, y, keep_prob):
params = {
self.x:x, self.y_:y, self.keep_prob:0.5}
test_acc = self.sess.run(self.accuracy, params) # 计算准确率
print("Test Accuracy: %f" % test_acc)
return test_acc
def close(self):
self.sess.close()
if __name__ == "__main__":
mnist = FashionMnist("fashion_mnist/")
mnist.build() # 组件网络
mnist.train() # 训练
# 评估
xs, ys = mnist.data.test.next_batch(100)
mnist.eval(xs, ys, 0.5)
mnist.close()
后记:
●本博客基于B站开源学习资源,是作者学习的笔记记录,仅用于学习交流,不做任何商业用途!
智能推荐
神操作!一行Python代码搞定一款游戏?给力!-程序员宅基地
文章浏览阅读475次。点击上方“Python大本营”,选择“置顶公众号”Python大本营 IT人的职业提升平台来源:pypl编程榜一直以来Python长期霸占编程语言排行榜前三位,其简洁,功能强大的特性..._python好游戏代码
ubuntu 1604 random: crng init done 后无反应_random: fast init done-程序员宅基地
文章浏览阅读2.4k次。服务器安装Ubuntu1604报错报错内容:kernel panic - not syncing attempted to kill the idle taskrandom: fast init donerandom: crng init done错误原因:使用了错误的安装镜像,CPU位宽64位使用了i386的安装镜像,切换amd64安装镜像后无报错..._random: fast init done
Git学习系列(一)初识Git-程序员宅基地
文章浏览阅读718次。Git作为一个版本控制工具,在工作中我们常常会用到它,尤其是在移动开发中,Git可谓是版本管理神器。下面让我们来认识一下Git:Git是一个分布式版本控制软件,它是由Linux的作者Linus用C写的一个分布式版本控制系统。如果大家对Git的历史比较感兴趣,可以点击链接进入官网了解:A Short History of GitGit主要特点有如下:1、速度:Git在本地上保存着所有
餐饮行业怎么才能玩转大数据?-程序员宅基地
文章浏览阅读154次。编者按:用数据将传统餐饮门店信息搬到线上,大众点评兴起;以数据化为基础,餐饮门店经营实现移动化,点单、叫号、排队模式火了。目前,餐饮行业的数据应用更多在供应链管理和餐饮门店运营状况实时监控分析,每个餐饮商家各自为战,实际数据的应用比大数据的应用更多,而大数据更多用于用户画像和少数大企业的经营管理。不过,基于大数据在电商的应用和餐饮的发展趋势,大数据的应..._如何获得每个城市的餐饮大数据
Dialog异常 Unable to add window, token not valid_token not valid-程序员宅基地
文章浏览阅读584次。好记性不如烂笔头问题描述 Activity 延时显示 Dialog ,在显示之前, Activity 已经销毁 报错 Unable to add window -- token android.os.BinderProxy@e6ee7d8 is not valid; is your activity running?问题分析 错误信息很明确,是没有 token 导致的. 而 toke_token not valid
基于SSH框架的电影订票系统网站的设计与实现-程序员宅基地
文章浏览阅读3.9k次。源码及论文:源码及论文下载:http://www.byamd.xyz/tag/java/开发计划1. 甘特图2. 开发计划简述如图所示在项目初期阶段,首先开始需求调研。需求调研阶段,我们将首先根据初期的会议内容考虑市场需求以及基本的市场现状,并根据以上的内容设计问卷来寻找痛点。我们准备使用第三方问卷工具,以电子问卷的方式来进行调查。初步预计会收到200份问卷。在需求调查阶段,同时开展对同类型的网站的评估工作。进入初步的需求分析阶段。目标是取得现有电影购票网站的基本购票流程,并对其交互等
随便推点
配置NGINX同时运行 https 和 http_nginx 和 http无法同时启动-程序员宅基地
文章浏览阅读406次。SSL 是需要申请证书的,key和PEM文件要放到服务器路径。然后NGINX下要进行443端口和80端口的绑定。server { listen 80; server_name ietaiji.com www.ietaiji.com; root "D:/aaa/WWW/ietaiji"; index index.html_nginx 和 http无法同时启动
总结:linux之Service_linux service-程序员宅基地
文章浏览阅读1.3w次,点赞9次,收藏60次。service与systemctl关系梳理开机启动梳理_linux service
揭开数据中心光模块利润之源-程序员宅基地
文章浏览阅读194次。在数据中心里,光模块毫不起眼,当我们在高谈阔论各种数据中心高大上技术时,很少提及到光模块。不过,光模块却是数据中心的必需品,哪个数据中心也离不开光模块,而且需要的数量还不少,一块48端口网络设备就需要48个光模块,而一台框式网络设备通常有数百个端口,这些端口如果都使用上就需要数百个光模块,这样算起来数据中心需要的光模块数量是惊人的。数据中心在进行网络投资..._光模块 占 数据中心 成本
Java NIO SocketChannel简述及示例_niosocketchannel-程序员宅基地
文章浏览阅读596次,点赞2次,收藏3次。SocketChannel简述及demoJAVA NIO之SocketChannel1. 简述2. 特点3. 解决问题4. demo功能5. 工作原理6. 代码示例7. 涉及知识扩充JAVA NIO之SocketChannel1. 简述NIO(Non-blocking I/O,在Java领域,也称为New I/O),是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来..._niosocketchannel
docker内的debian9使用ntpdate同步时间时报错step-systime: Operation not permitted-程序员宅基地
文章浏览阅读3.8k次。场景在docker下使用tzselect设置时间,最后提示编辑profile追加TZ='Asia/Shanghai'; export TZvim/etc/profilesource /etc/profile发现时区正确了,但时间和宿主机相差几分钟....使用 ntpdate cn.pool.ntp.org同步时间提示ntpdate[534]: step-systime: Operation not permitted使用 ntpdate ntp.s..._step-systime: operation not permitted
基于功能安全的车载计算平台开发:硬件层面_mcu 不同通道 共因-程序员宅基地
文章浏览阅读537次,点赞18次,收藏6次。如果不具备关于复杂元器件的安全故障比例的详细信息,可假定安全故障的保守比例为50%,并假定通过内部自检和外部看门狗(表中的安全机制SM4)达到对违背安全目标的总体覆盖率为90%。这里的意图不是一定需要全面的分析,比如要求对于微控制器内或者来自于一个复杂的PCB板上任何理论可能的信号组合的桥接故障进行详尽的分析。根据硬件故障对安全目标产生影响的不同,硬件故障可分为安全相关故障与非安全相关故障,其中安全相关故障又进一步分为单点故障、残余故障、多点可探测故障、多点可感知故障、多点潜伏故障与安全故障。