Text2SQL_DB-GPT-HUB微调-程序员宅基地
DB-GPT-Hub 是一个利用 LLMs 实现 Text-to-SQL 解析的实验项目,主要包含数据集收集、数据预处理、模型选择与构建和微调权重等步骤,通过这一系列的处理可以在提高 Text-to-SQL 能力的同时降低模型训练成本,让更多的开发者参与到 Text-to-SQL 的准确度提升工作当中,最终实现基于数据库的自动问答能力,让用户可以通过自然语言描述完成复杂数据库的查询操作等工作。(非简单搬运,自己实际部署有坑,填坑ing,是DB-GPT的用户)
##Spider 数据集
本项目案例数据主要以 Spider 数据集为示例 :
Spider: 一个跨域的复杂 text2sql 数据集,包含了 10,181 条自然语言问句、分布在200 个独立数据库中的 5,693 条 SQL,内容覆盖了 138 个不同的领域。(联系我,可以私发)。
其他数据集:
WikiSQL: 一个大型的语义解析数据集,由 80,654 个自然语句表述和 24,241 张表格的 sql 标注构成。WikiSQL 中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。
CHASE: 一个跨领域多轮交互 text2sql 中文数据集,包含 5459 个多轮问题组成的列表,一共 17,940 个 <query, SQL> 二元组,涉及 280 个不同领域的数据库。
BIRD-SQL:数据集是一个英文的大规模跨领域文本到 SQL 基准测试,特别关注大型数据库内容。该数据集包含 12,751 对文本到SQL数据对和 95 个数据库,总大小为 33.4GB,跨越 37 个职业领域。BIRD-SQL 数据集通过探索三个额外的挑战,即处理大规模和混乱的数据库值、外部知识推理和优化 SQL 执行效率,缩小了文本到 SQL 研究与实际应用之间的差距。
CoSQL: 一个用于构建跨域对话文本到 sql 系统的语料库。它是 Spider 和 SParC 任务的对话版本。CoSQL 由 30k+ 回合和 10k+ 带注释的 SQL 查询组成,这些查询来自 Wizard-of-Oz 的 3k 个对话集合,查询了跨越 138 个领域的 200 个复杂数据库。每个对话都模拟了一个真实的 DB 查询场景,其中一个工作人员作为用户探索数据库,一个 SQL 专家使用 SQL 检索答案,澄清模棱两可的问题,或者以其他方式通知。
按照 NSQL 的处理模板,对数据集做简单处理,共得到约 20w 条训练数据,链接详见附录 Healthy13/Text2SQL。
02基座模型
DB-GPT-HUB 目前已经支持的 base 模型有:
CodeLlama Baichuan2 LLaMa/LLaMa2 Falcon Qwen XVERSE ChatGLM2 internlm Falcon
模型可以基于 quantization_bit 为 4 的量化微调 (QLoRA) 所需的最低硬件资源,可以参考如下:
其中相关参数均设置为最小,batch_size 为 1 ,max_length 为 512。根据经验,如果计算资源足够,为了效果更好,建议相关长度值设置为 1024 或者 2048。

PART 3使用方法
01环境准备
下载项目,有镜像加速,任选其一就可。
git clone https://github.com/eosphoros-ai/DB-GPT-Hub.git
/ git clone https://gitclone.com/github.com/eosphoros-ai/DB-GPT-Hub.git
/ git clone https://hub.fgit.cf/eosphoros-ai/DB-GPT-Hub.git
/ git clone https://github.moeyy.xyz/https://github.com/eosphoros-ai/DB-GPT-Hub.git
/ git clone https://ghproxy.com/https://github.com/eosphoros-ai/DB-GPT-Hub.git
项目文件中,
cd DB-GPT-Hub
创建虚拟环境名为dbgpt_hub基于python=3.10,选择yes。
conda create -n dbgpt_hub python=3.10
进去虚拟环境,
conda activate dbgpt_hub
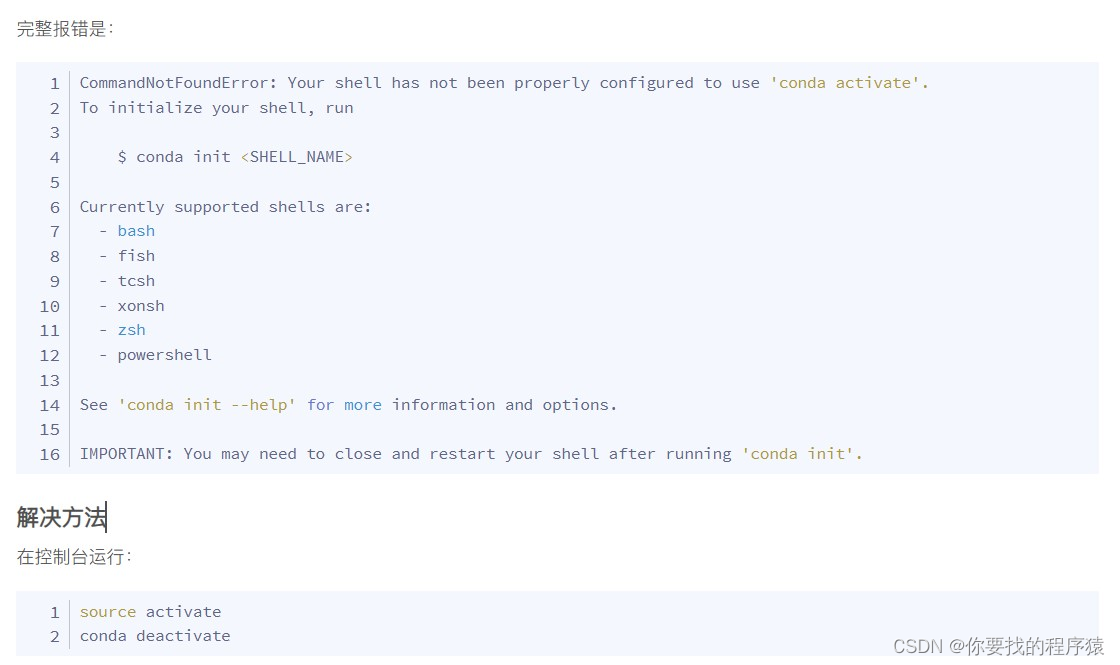
其中可能会有IMPORTANT:You may need to close and restart your shell after running'conda init'.的错误。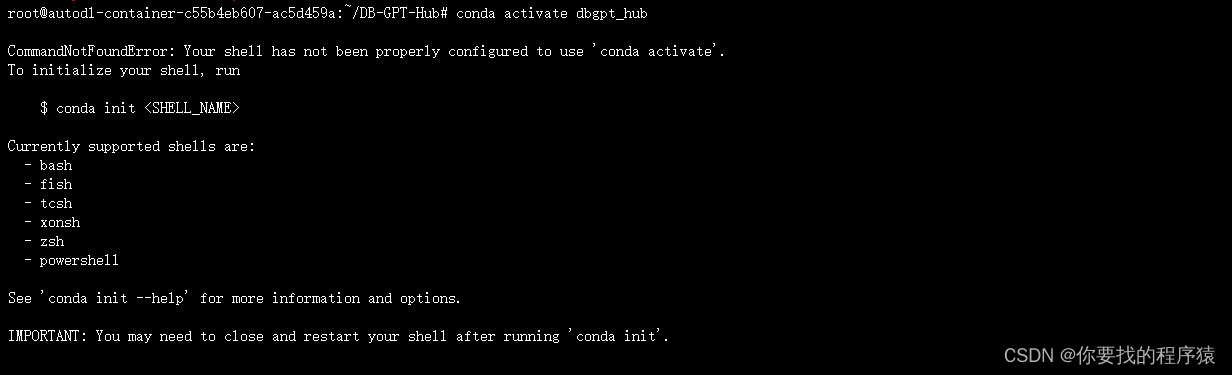
附解决方法:source activate conda activate
安装依赖
pip install -r requirements.txt
其中安装torch最后killed,它说你的空闲内存不足以安装软件包,但有一种方法你仍然可以使用它。
pip install torch --no-cache-dir
02数据准备
DB-GPT-Hub使用的是信息匹配生成法进行数据准备,即结合表信息的 SQL + Repository 生成方式,这种方式结合了数据表信息,能够更好地理解数据表的结构和关系,适用于生成符合需求的 SQL 语句。从 spider数据集链接下载 spider 数据集,默认将数据下载解压后,放在目录 dbgpt_hub/data下面,即路径为 dbgpt_hub/data/spider。
数据预处理部分,只需运行如下脚本即可:sh dbgpt_hub/scripts/gen_train_eval_data.sh
#生成train数据 和dev(eval)数据,
sh dbgpt_hub/scripts/
在 dbgpt_hub/data/ 目录你会得到新生成的训练文件 example_text2sql_train.json 和测试文件 example_text2sql_dev.json ,数据量分别为 8659 和 1034 条。
生成的json中的数据形如:
{
"db_id": "department_management",
"instruction": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n\n",
"input": "###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:",
"output": "SELECT count(*) FROM head WHERE age > 56",
"history": []
},
03模型微调
本项目微调不仅能支持 QLoRA 和 LoRA 法,还支持 deepseed。可以运行以下命令来微调模型,默认带着参数 --quantization_bit 为 QLoRA 的微调方式,如果想要转换为 lora的微调,只需在脚本中去掉 quantization_bit 参数即可。默认 QLoRA 微调,运行命令:
sh dbgpt_hub/scripts/train_sft.sh
微调后的模型权重会默认保存到 adapter 文件夹下面,即 dbgpt_hub/output/adapter 目录中。
如果使用多卡训练,想要用 deepseed,则将 train_sft.sh 中如下的默认的内容:
CUDA_VISIBLE_DEVICES=0 python dbgpt_hub/train/sft_train.py \
--quantization_bit 4 \
...
更改为:
deepspeed --num_gpus 2 dbgpt_hub/train/sft_train.py \
--deepspeed dbgpt_hub/configs/ds_config.json \
--quantization_bit 4 \
...
其他省略 (…) 的部分均保持一致即可。如果想要更改默认的 deepseed 配置,进入 dbgpt_hub/configs 目录,在 ds_config.json 更改即可。
脚本中微调时不同模型对应的关键参数 lora_target 和 template.
train_sft.sh 中其他关键参数含义:
quantization_bit:是否量化,取值为[ 4 或者 8 ]。
model_name_or_path:LLM模型的路径。
dataset:取值为训练数据集的配置名字,对应在 dbgpt_hub/data/dataset_info.json 中外层 key 值,如 example_text2sql。
max_source_length:输入模型的文本长度,如果计算资源支持,可以尽能设大,如 1024 或者 2048。
max_target_length:输出模型的 sql 内容长度,设置为 512 一般足够。
output_dir :SFT 微调时 Peft 模块输出的路径,默认设置在 dbgpt_hub/output/adapter/路径下 。
per_device_train_batch_size :batch 的大小,如果计算资源支持,可以设置为更大,默认为 1 。
gradient_accumulation_steps :梯度更新的累计 steps 值。
save_steps :模型保存的 ckpt 的 steps 大小值,默认可以设置为 100。
num_train_epochs :训练数据的 epoch 数。
04模型预测
项目目录下 ./dbgpt_hub/ 下的 output/pred/,此文件路径为关于模型预测结果默认输出的位置(如果没有则需要创建上)。
预测运行命令:
sh ./dbgpt_hub/scripts/predict_sft.sh
脚本中默认带着参数 --quantization_bit 为 QLoRA 的预测,去掉即为 LoRA 的预测方式。
其中参数 --predicted_out_filename 的值为模型预测的结果文件名,结果在dbgpt_hub/output/pred 目录下可以找到。
#05模型权重
可以从 Huggingface 查看我们之前8月份上传的对应的 Peft 模块的权重 ,huggingface 地址参见附录 。新的更好的在 spider 的评估集上执行准确率超越 GPT-4 的权重我们将尽快释放出。
如果你需要将训练的基础模型和微调的Peft模块的权重合并,导出一个完整的模型。则运行如下模型导出脚本:
sh ./dbgpt_hub/scripts/export_merge.sh
注意将脚本中的相关参数路径值替换为你项目所对应的路径。
#06模型评估
对于模型在数据集上的效果评估,默认为在 spider 数据集上。运行以下命令来:
python dbgpt_hub/eval/evaluation.py --plug_value --input Your_model_pred_file
你可以在项目的 docs/eval_llm_result.md 找到我们最新的评估结果。
#附录
DB-GPT 框架: https://github.com/eosphoros-ai
Text2SQL 微调:https://github.com/eosphoros-ai/DB-GPT-Hub
Awesome-Text2SQL:https://github.com/eosphoros-ai/Awesome-Text2SQL
DB-GPT-WEB: https://github.com/eosphoros-ai/DB-GPT-Web
Huggingface :https://huggingface.co/eosphoros
Healthy13/Text2SQL:https://huggingface.co/datasets/Healthy13/Text2SQL/tree/main
智能推荐
hive使用适用场景_大数据入门:Hive应用场景-程序员宅基地
文章浏览阅读5.8k次。在大数据的发展当中,大数据技术生态的组件,也在不断地拓展开来,而其中的Hive组件,作为Hadoop的数据仓库工具,可以实现对Hadoop集群当中的大规模数据进行相应的数据处理。今天我们的大数据入门分享,就主要来讲讲,Hive应用场景。关于Hive,首先需要明确的一点就是,Hive并非数据库,Hive所提供的数据存储、查询和分析功能,本质上来说,并非传统数据库所提供的存储、查询、分析功能。Hive..._hive应用场景
zblog采集-织梦全自动采集插件-织梦免费采集插件_zblog 网页采集插件-程序员宅基地
文章浏览阅读496次。Zblog是由Zblog开发团队开发的一款小巧而强大的基于Asp和PHP平台的开源程序,但是插件市场上的Zblog采集插件,没有一款能打的,要么就是没有SEO文章内容处理,要么就是功能单一。很少有适合SEO站长的Zblog采集。人们都知道Zblog采集接口都是对Zblog采集不熟悉的人做的,很多人采取模拟登陆的方法进行发布文章,也有很多人直接操作数据库发布文章,然而这些都或多或少的产生各种问题,发布速度慢、文章内容未经严格过滤,导致安全性问题、不能发Tag、不能自动创建分类等。但是使用Zblog采._zblog 网页采集插件
Flink学习四:提交Flink运行job_flink定时运行job-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏2次。restUI页面提交1.1 添加上传jar包1.2 提交任务job1.3 查看提交的任务2. 命令行提交./flink-1.9.3/bin/flink run -c com.qu.wc.StreamWordCount -p 2 FlinkTutorial-1.0-SNAPSHOT.jar3. 命令行查看正在运行的job./flink-1.9.3/bin/flink list4. 命令行查看所有job./flink-1.9.3/bin/flink list --all._flink定时运行job
STM32-LED闪烁项目总结_嵌入式stm32闪烁led实验总结-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。这个项目是基于STM32的LED闪烁项目,主要目的是让学习者熟悉STM32的基本操作和编程方法。在这个项目中,我们将使用STM32作为控制器,通过对GPIO口的控制实现LED灯的闪烁。这个STM32 LED闪烁的项目是一个非常简单的入门项目,但它可以帮助学习者熟悉STM32的编程方法和GPIO口的使用。在这个项目中,我们通过对GPIO口的控制实现了LED灯的闪烁。LED闪烁是STM32入门课程的基础操作之一,它旨在教学生如何使用STM32开发板控制LED灯的闪烁。_嵌入式stm32闪烁led实验总结
Debezium安装部署和将服务托管到systemctl-程序员宅基地
文章浏览阅读63次。本文介绍了安装和部署Debezium的详细步骤,并演示了如何将Debezium服务托管到systemctl以进行方便的管理。本文将详细介绍如何安装和部署Debezium,并将其服务托管到systemctl。解压缩后,将得到一个名为"debezium"的目录,其中包含Debezium的二进制文件和其他必要的资源。注意替换"ExecStart"中的"/path/to/debezium"为实际的Debezium目录路径。接下来,需要下载Debezium的压缩包,并将其解压到所需的目录。
Android 控制屏幕唤醒常亮或熄灭_android实现拿起手机亮屏-程序员宅基地
文章浏览阅读4.4k次。需求:在诗词曲文项目中,诗词整篇朗读的时候,文章没有读完会因为屏幕熄灭停止朗读。要求:在文章没有朗读完毕之前屏幕常亮,读完以后屏幕常亮关闭;1.权限配置:设置电源管理的权限。
随便推点
目标检测简介-程序员宅基地
文章浏览阅读2.3k次。目标检测简介、评估标准、经典算法_目标检测
记SQL server安装后无法连接127.0.0.1解决方法_sqlserver 127 0 01 无法连接-程序员宅基地
文章浏览阅读6.3k次,点赞4次,收藏9次。实训时需要安装SQL server2008 R所以我上网上找了一个.exe 的安装包链接:https://pan.baidu.com/s/1_FkhB8XJy3Js_rFADhdtmA提取码:ztki注:解压后1.04G安装时Microsoft需下载.NET,更新安装后会自动安装如下:点击第一个傻瓜式安装,唯一注意的是在修改路径的时候如下不可修改:到安装实例的时候就可以修改啦数据..._sqlserver 127 0 01 无法连接
js 获取对象的所有key值,用来遍历_js 遍历对象的key-程序员宅基地
文章浏览阅读7.4k次。1. Object.keys(item); 获取到了key之后就可以遍历的时候直接使用这个进行遍历所有的key跟valuevar infoItem={ name:'xiaowu', age:'18',}//的出来的keys就是[name,age]var keys=Object.keys(infoItem);2. 通常用于以下实力中 <div *ngFor="let item of keys"> <div>{{item}}.._js 遍历对象的key
粒子群算法(PSO)求解路径规划_粒子群算法路径规划-程序员宅基地
文章浏览阅读2.2w次,点赞51次,收藏310次。粒子群算法求解路径规划路径规划问题描述 给定环境信息,如果该环境内有障碍物,寻求起始点到目标点的最短路径, 并且路径不能与障碍物相交,如图 1.1.1 所示。1.2 粒子群算法求解1.2.1 求解思路 粒子群优化算法(PSO),粒子群中的每一个粒子都代表一个问题的可能解, 通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。 在路径规划中,我们将每一条路径规划为一个粒子,每个粒子群群有 n 个粒 子,即有 n 条路径,同时,每个粒子又有 m 个染色体,即中间过渡点的_粒子群算法路径规划
量化评价:稳健的业绩评价指标_rar 海龟-程序员宅基地
文章浏览阅读353次。所谓稳健的评估指标,是指在评估的过程中数据的轻微变化并不会显著的影响一个统计指标。而不稳健的评估指标则相反,在对交易系统进行回测时,参数值的轻微变化会带来不稳健指标的大幅变化。对于不稳健的评估指标,任何对数据有影响的因素都会对测试结果产生过大的影响,这很容易导致数据过拟合。_rar 海龟
IAP在ARM Cortex-M3微控制器实现原理_value line devices connectivity line devices-程序员宅基地
文章浏览阅读607次,点赞2次,收藏7次。–基于STM32F103ZET6的UART通讯实现一、什么是IAP,为什么要IAPIAP即为In Application Programming(在应用中编程),一般情况下,以STM32F10x系列芯片为主控制器的设备在出厂时就已经使用J-Link仿真器将应用代码烧录了,如果在设备使用过程中需要进行应用代码的更换、升级等操作的话,则可能需要将设备返回原厂并拆解出来再使用J-Link重新烧录代码,这就增加了很多不必要的麻烦。站在用户的角度来说,就是能让用户自己来更换设备里边的代码程序而厂家这边只需要提供给_value line devices connectivity line devices