大数据技术学习,深度挖掘大数据的现状分析_大数据挖掘算法全景图-程序员宅基地
技术标签: 程序员 大数据学习 数据分析 Linux spark 大数据开发 人工智能 编程语言 hadoop 大数据
技术型的高科技创业公司都喜欢闪闪发光的新东西,而“大数据”跟3年前火热程度相比反而有些凄惨。虽然Hadoop创建于2006年,在“大数据”的概念兴起到达白热化是在2011年至2014年期间,当时在媒体和行业面前,大数据就是“黑金石油”。2015年数据世界中时尚年轻人喜欢转移到AI的相关概念,他们口味变成:机器智能,深度学习等。

在这里还是要推荐下我自己建的大数据学习交流群:199427210,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
企业级技术 = 艰苦的工作
其实大数据有趣的是它不是直接可以炒作的东西。
能够获得广泛兴趣的产品和服务往往是那些人们可以触摸和感受到的,比如:移动应用,社交网络,可穿戴设备,虚拟现实等。
但大数据,从根本上说是“管道”。当然,大数据支持许多消费者或企业用户体验,但其核心是企业的技术:数据库,分析等:而这后面几乎没人能看到东西运行。
而且如果大家真正工作过的都知道,在企业中改造新技术并不大可能在一夜之间发生。
早年的大数据是在大型互联网公司中(特别是谷歌,雅虎,Facebook,Twitter,LinkedIn等),它们重度使用和推动大数据技术。这些公司突然面临着前所未有的数据量,没有以前的基础设施,并能招到一些最好的工程师,所以他们基本上是从零开始搭建他们所需要的技术。开源的风气迅速蔓延,大量的新技术与更广阔的世界共享。随着时间推移,其中一些工程师离开了大型网络公司,开始自己的大数据初创公司。其他的“数字原生”的公司,其中包括许多独角兽,开始面临跟大型互联网公司同样需求,无论有没有基础设施,它们都是这些大数据技术的早期采用者。而早期的成功导致更多的创业和风险投资。
现在一晃几年了,我们现在是有大得多而棘手的机会:数据技术通过更广泛从中型企业到非常大的跨国公司。不同的是“数字原生”的公司,不必从头开始做。他们也有很多损失:在绝大多数的公司,现有的技术基础设施“够用”。这些组织也明白,宜早不宜迟需要进化,但他们不会一夜之间淘汰并更换关键任务的系统。任何发展都需要过程,预算,项目管理,导航,部门部署,全面的安全审计等。大型企业会小心谨慎地让年轻的创业公司处理他们的基础设施的关键部分。而且,一些(大多数?)企业家压根不想把他们的数据迁移到云中,至少不是公有云。
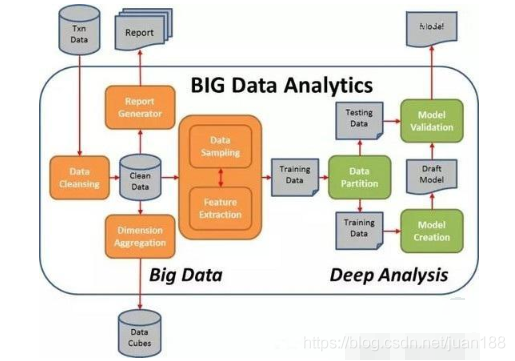
从另一个关键点大家就明白了:大数据的成功是不是实现一小片技术(如Hadoop的或其他任何东西),而是需要放在一起的技术,人员,流程的流水线。你需要采集数据,存储数据,清理数据,查询数据,分析数据,可视化数据。这将由产品来完成,有些由人力来完成。一切都需要无缝集成。归根结底,对于这一切工作,整个公司,从高级管理人员开始,需要致力于建立一个数据驱动的文化,大数据不是小事,而是全局的事。
换句话说:这是大量艰苦的工作。
部署阶段
以上解释了为什么几年后,虽然很多高调的创业公司上线也拿到引人注目的风险投资,但只是到达大数据部署和早期成熟阶段。
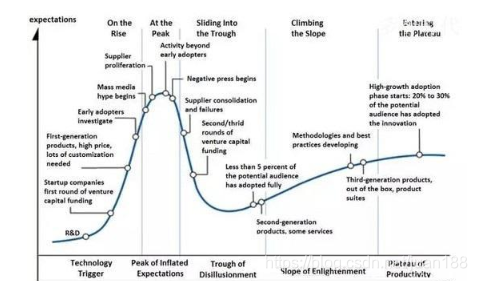
更有远见的大公司(称他们为“尝鲜者”在传统的技术采用周期),在2011 - 2013年开始早期实验大数据技术,推出Hadoop系统,或尝试单点解决方案。他们招聘了形形色色的人,可能工作头衔以前不存在(如“数据科学家”或“首席数据官”)。他们通过各种努力,包括在一个中央储存库或“数据湖”倾倒所有的数据,有时希望魔术随之而来(通常没有)。他们逐步建立内部竞争力,与不同厂商尝试,部署到线上,讨论在企业范围内实施推广。在许多情况下,他们不知道下一个重要的拐点在哪里,经过几年建设大数据基础架构,从他们公司业务用户的角度来看,也没有那么多东西去显示它。但很多吃力不讨好的工作已经完成,而部署在核心架构之上的应用程序又要开始做了。
下一组的大公司(称他们为“早期大众”在传统的技术采用周期)一直呆在场边,还在迷惑的望着这整个大数据这玩意。直到最近,他们希望大供应商(例如IBM)提供一个一站式的解决方案,但它们知道不会很快出现。他们看大数据全局图很恐怖,就真的想知道是否要跟那些经常发音相同,也就凑齐解决方案的创业公司一起做。他们试图弄清楚他们是否应该按顺序并逐步工作,首先构建基础设施,然后再分析应用层,或在同一时间做所有的,还是等到更容易做的东西出现。
生态系统正在走向成熟
同时,创业公司/供应商方面,大数据公司整体第一波(那些成立于2009年至2013)现在已经融资多轮,扩大他们的规模,积累了早期部署的成功与失败教训,也提供更成熟,久经考验的产品。现在有少数是上市公司(包括HortonWorks和New Relic 它们的IPO在2014年12月),而其他(Cloudera,MongoDB的,等等)都融了数亿美元。
VC投资仍然充满活力,2016年前几个星期看到一些巨额融资的晚期大数据初创公司:DataDog(9400万),BloomReach(5600万),Qubole(3000万), PlaceIQ( 2500万)这些大数据初创公司在2015年收到的$ 66.4亿创业投资,占高科技投资总额的11%。
并购活动仍然不高(35次)。
随创业活动和资金的持续涌入,有些不错的资本退出,日益活跃的高科技巨头(亚马逊,谷歌和IBM),公司数量不断增加,这里就是2016年和2017年大数据全景图:
很显然这里密密麻麻很多公司,从基本走势方面,动态的(创新,推出新的产品和公司)已逐渐从左向右移动,从基础设施层(开发人员/工程师)到分析层(数据科学家和分析师的世界)到应用层(商业用户和消费者),其中“大数据的本地应用程序”已经迅速崛起- 这是我们预计的格局。
大数据基础架构:创新仍然有很多
正是因为谷歌十年前的MapReduce和BigTable的论文,Doug Cutting, Mike Cafarella开发 创建Hadoop的,所以大数据的基础架构层成熟了,也解决了一些关键问题。
而基础设施领域的不断创新蓬勃发展还是通过大量的开源活动。
Spark带着Hadoop飞
2015年毫无疑问是Apache Spark最火的一年,这是一个开源框架,利用内存中做处理。这开始得到了不少争论,从我们发布了前一版本以来,Spark被各个对手采纳,从IBM到Cloudera都给它相当的支持。 Spark的意义在于它有效地解决了一些使用Hadoop很慢的关键问题:它的速度要快得多(基准测试表明:Spark比Hadoop的MapReduce的快10到100倍),更容易编写,并非常适用于机器学习。
其他令人兴奋的框架的不断涌现,并获得新的动力,如Flink,Ignite,Samza,Kudu等。一些思想领袖认为Mesos的出现(一个框架以“对你的数据中心编程就像是单一的资源池”),不需要完全的Hadoop。即使是在数据库的世界,这似乎已经看到了更多的新兴的玩家让市场持续,大量令人兴奋的事情正在发生,从图形数据库的成熟(Neo4j),此次推出的专业数据库(时间序列数据库InfluxDB),CockroachDB,(受到谷歌Spanner启发出现,号称提供二者最好的SQL和NoSQL),数据仓库演变(Snowflake)。
大数据分析:现在的AI
在过去几个月的大趋势上,大数据分析已经越来越注重人工智能(各种形式和接口),去帮助分析海量数据,得出预测的见解。
最近AI的复活就好比大数据生的一个孩子。深度学习(获取了最多的人工智能关注的领域)背后的算法大部分在几十年前,但直到他们可以应用于代价便宜而速度够快的大量数据来充分发挥其潜力(Yann LeCun, Facebook深度学习研究员主管)。 AI和大数据之间的关系是如此密切,一些业内专家现在认为,AI已经遗憾地“爱上了大数据”(Geometric Intelligence)。
反过来,AI现在正在帮助大数据实现承诺。AI /机器学习的分析重点变成大数据进化逻辑的下一步:现在我有这些数据,我该怎么从中提取哪些洞察?当然,这其中的数据科学家们 - 从一开始他们的作用就是实现机器学习和做出有意义的数据模型。但渐渐地机器智能正在通过获得数据去协助数据科学家。新兴产品可以提取数学公式(Context Relevant)或自动构建和建议数据的科学模式,有可能产生最好的结果(DataRobot)。新的AI公司提供自动完成复杂的实体的标识(MetaMind,Clarifai,Dextro),或者提供强大预测分析(HyperScience)。
由于无监督学习的产品传播和提升,我们有趣的想知道AI与数据科学家的关系如何演变 - 朋友还是敌人? AI是肯定不会在短期内很快取代数据科学家,而是希望看到数据科学家通常执行的简单任务日益自动化,最后生产率大幅提高。
通过一切手段,AI /机器学习不是大数据分析的唯一趋势。令人兴奋的趋势是大数据BI平台的成熟及其日益增强的实时能力(SiSense,Arcadia)。
大数据应用:一个真正的加速度
由于一些核心基础架构难题都已解决,大数据的应用层迅速建立。
在企业内部,各种工具已经出现,以帮助企业用户操作核心功能。例如,大数据通过大量的内部和外部的数据,实时更新数据,可以帮助销售和市场营销弄清楚哪些客户最有可能购买。客户服务应用可以帮助个性化服务; HR应用程序可帮助找出如何吸引和留住最优秀的员工;等
专业大数据应用已经在几乎任何垂直领域都很出色,从医疗保健(特别是在基因组学和药物研究),到财经到时尚到司法(Mark43)。
两个趋势值得关注。
首先,很多这些应用都是“大数据同乡”,因为他们本身就是建立在最新的大数据技术,并代表客户能够充分利用大数据的有效方式,无需部署底层的大数据技术,因为这些已“在一个盒子“,至少是对于那些特定功能 - 例如,ActionIQ是建立在Spark上,因此它的客户可以充分利用他们的营销部门Spark的权力,而无需实际部署Spark自己 - 在这种情况下,没有“流水线”。
第二,人工智能同样在应用程序级别有强大吸引力。例如,在猫捉老鼠的游戏,安全上,AI被广泛利用,它可以识别黑客和打击网络攻击。 “人工智能”对冲基金也开始出现。全部由AI驱动数字助理行业已经去年出现,从自动安排会议(x.ai)任务,到购物为您带来一切。这些解决方案依赖人工智能的程度差别很大,从接近100%的自动化,到个人的能力被AI增强 - 但是,趋势是明确的。
在许多方面,我们仍处于大数据的早期。尽管它发展了几年,建设存储和数据的过程只是第一阶段的基础设施。 AI /机器学习出现在大数据的应用层的趋势。大数据和AI的结合将推动几乎每一个行业的创新,这令人难以置信。从这个角度来看,大数据机会甚至可能比人们认为的还大。
随着大数据的不断成熟,这个词本身可能会消失或者变得过时,没有人会使用它了。它是成功通过技术,变得很普遍,无处不在,并最终无形化。
智能推荐
分布式光纤传感器的全球与中国市场2022-2028年:技术、参与者、趋势、市场规模及占有率研究报告_预计2026年中国分布式传感器市场规模有多大-程序员宅基地
文章浏览阅读3.2k次。本文研究全球与中国市场分布式光纤传感器的发展现状及未来发展趋势,分别从生产和消费的角度分析分布式光纤传感器的主要生产地区、主要消费地区以及主要的生产商。重点分析全球与中国市场的主要厂商产品特点、产品规格、不同规格产品的价格、产量、产值及全球和中国市场主要生产商的市场份额。主要生产商包括:FISO TechnologiesBrugg KabelSensor HighwayOmnisensAFL GlobalQinetiQ GroupLockheed MartinOSENSA Innovati_预计2026年中国分布式传感器市场规模有多大
07_08 常用组合逻辑电路结构——为IC设计的延时估计铺垫_基4布斯算法代码-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏12次。常用组合逻辑电路结构——为IC设计的延时估计铺垫学习目的:估计模块间的delay,确保写的代码的timing 综合能给到多少HZ,以满足需求!_基4布斯算法代码
OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏5次。OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版
关于美国计算机奥赛USACO,你想知道的都在这_usaco可以多次提交吗-程序员宅基地
文章浏览阅读2.2k次。USACO自1992年举办,到目前为止已经举办了27届,目的是为了帮助美国信息学国家队选拔IOI的队员,目前逐渐发展为全球热门的线上赛事,成为美国大学申请条件下,含金量相当高的官方竞赛。USACO的比赛成绩可以助力计算机专业留学,越来越多的学生进入了康奈尔,麻省理工,普林斯顿,哈佛和耶鲁等大学,这些同学的共同点是他们都参加了美国计算机科学竞赛(USACO),并且取得过非常好的成绩。适合参赛人群USACO适合国内在读学生有意向申请美国大学的或者想锻炼自己编程能力的同学,高三学生也可以参加12月的第_usaco可以多次提交吗
MySQL存储过程和自定义函数_mysql自定义函数和存储过程-程序员宅基地
文章浏览阅读394次。1.1 存储程序1.2 创建存储过程1.3 创建自定义函数1.3.1 示例1.4 自定义函数和存储过程的区别1.5 变量的使用1.6 定义条件和处理程序1.6.1 定义条件1.6.1.1 示例1.6.2 定义处理程序1.6.2.1 示例1.7 光标的使用1.7.1 声明光标1.7.2 打开光标1.7.3 使用光标1.7.4 关闭光标1.8 流程控制的使用1.8.1 IF语句1.8.2 CASE语句1.8.3 LOOP语句1.8.4 LEAVE语句1.8.5 ITERATE语句1.8.6 REPEAT语句。_mysql自定义函数和存储过程
半导体基础知识与PN结_本征半导体电流为0-程序员宅基地
文章浏览阅读188次。半导体二极管——集成电路最小组成单元。_本征半导体电流为0
随便推点
【Unity3d Shader】水面和岩浆效果_unity 岩浆shader-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏18次。游戏水面特效实现方式太多。咱们这边介绍的是一最简单的UV动画(无顶点位移),整个mesh由4个顶点构成。实现了水面效果(左图),不动代码稍微修改下参数和贴图可以实现岩浆效果(右图)。有要思路是1,uv按时间去做正弦波移动2,在1的基础上加个凹凸图混合uv3,在1、2的基础上加个水流方向4,加上对雾效的支持,如没必要请自行删除雾效代码(把包含fog的几行代码删除)S..._unity 岩浆shader
广义线性模型——Logistic回归模型(1)_广义线性回归模型-程序员宅基地
文章浏览阅读5k次。广义线性模型是线性模型的扩展,它通过连接函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。广义线性模型拟合的形式为:其中g(μY)是条件均值的函数(称为连接函数)。另外,你可放松Y为正态分布的假设,改为Y 服从指数分布族中的一种分布即可。设定好连接函数和概率分布后,便可以通过最大似然估计的多次迭代推导出各参数值。在大部分情况下,线性模型就可以通过一系列连续型或类别型预测变量来预测正态分布的响应变量的工作。但是,有时候我们要进行非正态因变量的分析,例如:(1)类别型.._广义线性回归模型
HTML+CSS大作业 环境网页设计与实现(垃圾分类) web前端开发技术 web课程设计 网页规划与设计_垃圾分类网页设计目标怎么写-程序员宅基地
文章浏览阅读69次。环境保护、 保护地球、 校园环保、垃圾分类、绿色家园、等网站的设计与制作。 总结了一些学生网页制作的经验:一般的网页需要融入以下知识点:div+css布局、浮动、定位、高级css、表格、表单及验证、js轮播图、音频 视频 Flash的应用、ul li、下拉导航栏、鼠标划过效果等知识点,网页的风格主题也很全面:如爱好、风景、校园、美食、动漫、游戏、咖啡、音乐、家乡、电影、名人、商城以及个人主页等主题,学生、新手可参考下方页面的布局和设计和HTML源码(有用点赞△) 一套A+的网_垃圾分类网页设计目标怎么写
C# .Net 发布后,把dll全部放在一个文件夹中,让软件目录更整洁_.net dll 全局目录-程序员宅基地
文章浏览阅读614次,点赞7次,收藏11次。之前找到一个修改 exe 中 DLL地址 的方法, 不太好使,虽然能正确启动, 但无法改变 exe 的工作目录,这就影响了.Net 中很多获取 exe 执行目录来拼接的地址 ( 相对路径 ),比如 wwwroot 和 代码中相对目录还有一些复制到目录的普通文件 等等,它们的地址都会指向原来 exe 的目录, 而不是自定义的 “lib” 目录,根本原因就是没有修改 exe 的工作目录这次来搞一个启动程序,把 .net 的所有东西都放在一个文件夹,在文件夹同级的目录制作一个 exe._.net dll 全局目录
BRIEF特征点描述算法_breif description calculation 特征点-程序员宅基地
文章浏览阅读1.5k次。本文为转载,原博客地址:http://blog.csdn.net/hujingshuang/article/details/46910259简介 BRIEF是2010年的一篇名为《BRIEF:Binary Robust Independent Elementary Features》的文章中提出,BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述子,摈弃了利用区域灰度..._breif description calculation 特征点
房屋租赁管理系统的设计和实现,SpringBoot计算机毕业设计论文_基于spring boot的房屋租赁系统论文-程序员宅基地
文章浏览阅读4.1k次,点赞21次,收藏79次。本文是《基于SpringBoot的房屋租赁管理系统》的配套原创说明文档,可以给应届毕业生提供格式撰写参考,也可以给开发类似系统的朋友们提供功能业务设计思路。_基于spring boot的房屋租赁系统论文