李宏毅机器学习课程笔记——回归_李宏毅机器学习中回归课堂笔记-程序员宅基地
1、回归是什么
回归(Regression) 就是找到一个函数 function,通过输入特征 x,输出一个数值 Scalar。比较像我们常见的函数拟合。
2、回归的步骤
- step1:模型假设,选择模型框架
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降)
下面以李宏毅老师的课程中的宝可梦能力值的例子来对每个步骤进行分析。
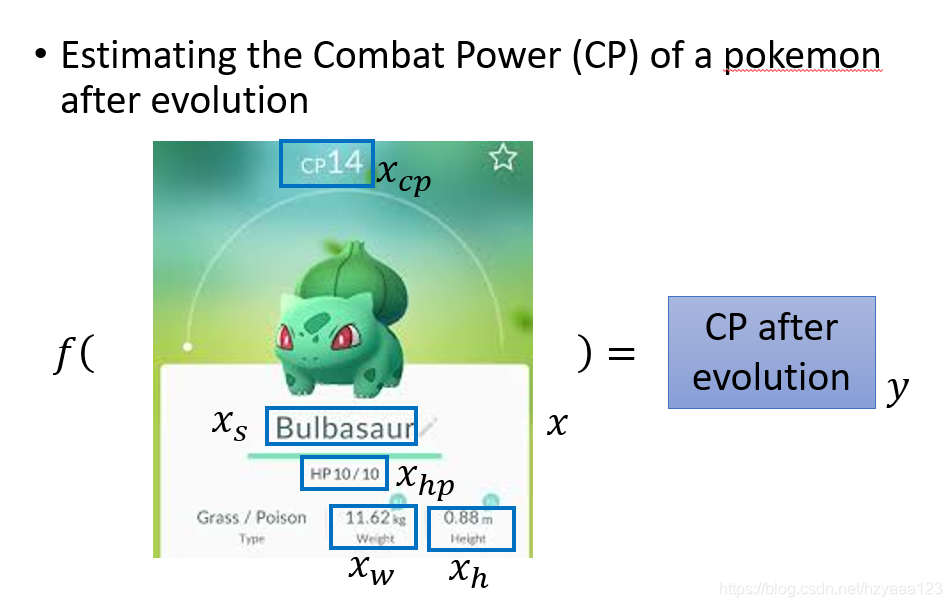
2.1 模型选择
这里我们都选择线性模型进行分析。
2.1.1 单个特征
当选取单个特征时,以特征 x c p x_{cp} xcp为例,假设线性模型 y = b + w x c p y=b+wx_{cp} y=b+wxcp,随着w和b的变化,也就可以得到不同的模型。
2.1.2 多个特征
在实际应用中,输入特征肯定不止 x c p x_{cp} xcp这一个。例如,进化前的CP值、物种(Bulbasaur)、血量(HP)、重量(Weight)、高度(Height)等,特征会有很多。
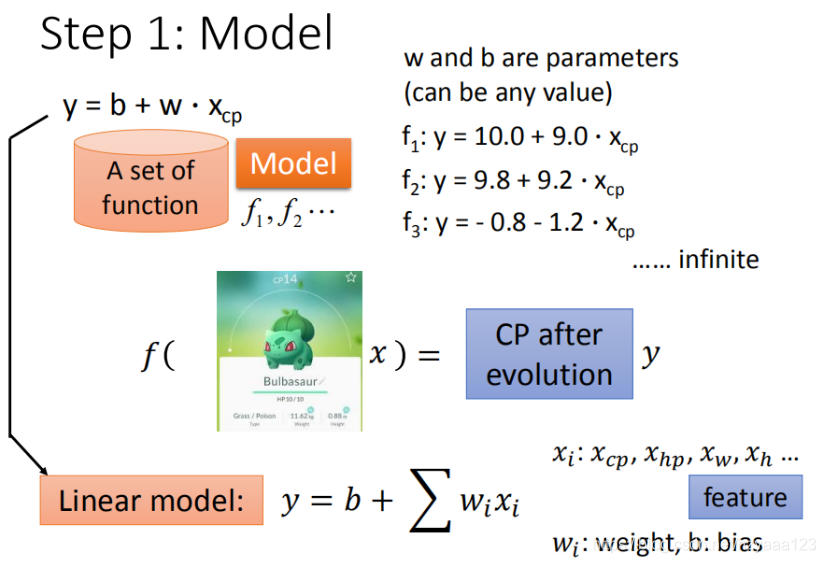
所以假设的线性模型应该是: y = b + ∑ w i x i y=b+\sum w_ix_i y=b+∑wixi
- x i x_i xi:就是各种特征
- w i w_i wi:就是各个特征的权重
- b b b:是偏移量
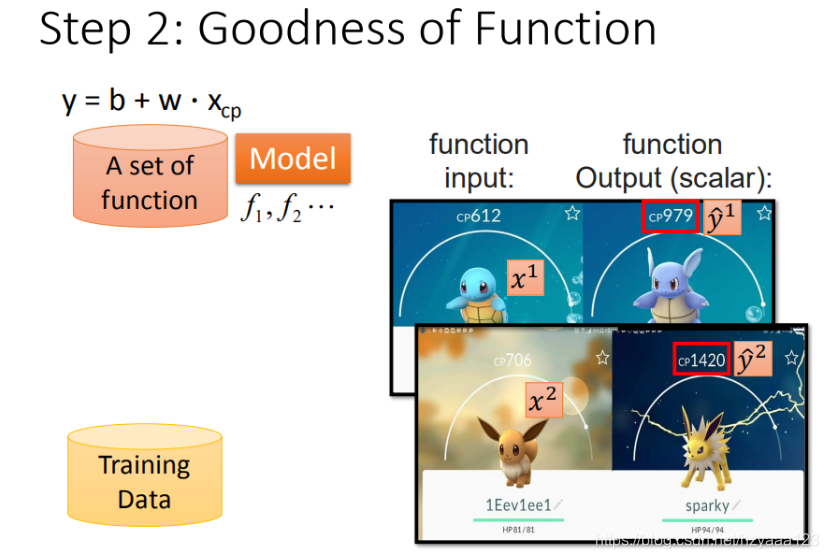
2.2 模型评估
我们使用单个特征进行分析。
这里定义 x 1 x^1 x1 是进化前的CP值, y ^ 1 \hat{y}^1 y^1 进化后的CP值, ^ \hat{} ^ 所代表的是真实值
将10组原始数据在二维图中展示,图中的每一个点 ( x c p n , y ^ n ) (x_{cp}^n,\hat{y}^n) (xcpn,y^n) 对应着 进化前的CP值 和 进化后的CP值。
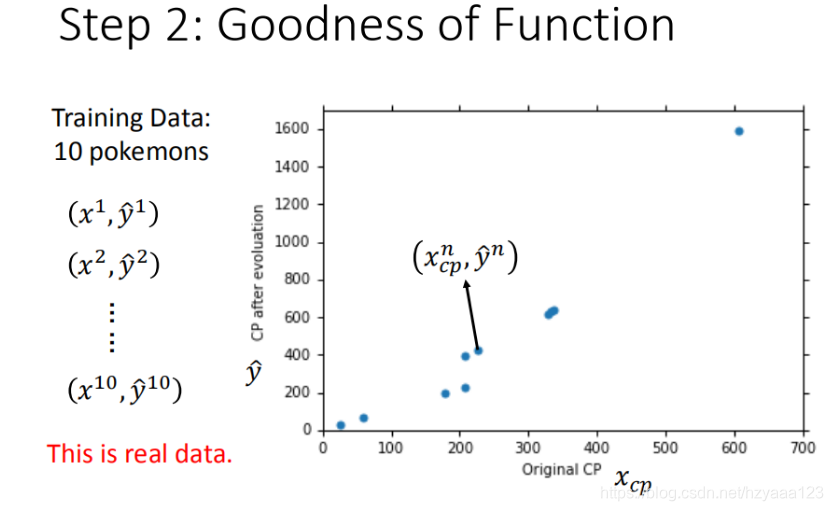
有了这些真实的数据,那我们怎么衡量模型的好坏呢?从数学的角度来讲,我们使用距离。求【进化后的CP值】与【模型预测的CP值】差,来判定模型的好坏。也就是使用损失函数(Loss function) 来衡量模型的好坏,统计10组原始数据 ( y ^ n − f ( x c p n ) ) 2 \left ( \hat{y}^n - f(x_{cp}^n) \right )^2 (y^n−f(xcpn))2 的和,和越小模型越好。如下图所示:
 L ( f ) = ∑ n = 1 10 ( y ^ n − f ( x c p n ) ) 2 , 将 【 f ( x ) = y 】 , 【 y = b + w ⋅ x c p 】 代 入 = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p ) ) 2 \begin{aligned} L(f) & = \sum_{n=1}^{10}\left ( \hat{y}^n - f(x_{cp}^n) \right )^2,将【f(x) = y】, 【y= b + w·x_{cp}】代入 \ & = \sum_{n=1}^{10}\left ( \hat{y}^n - (b + w·x_{cp}) \right )^2\ \end{aligned} L(f)=n=1∑10(y^n−f(xcpn))2,将【f(x)=y】,【y=b+w⋅xcp】代入 =n=1∑10(y^n−(b+w⋅xcp))2
L ( f ) = ∑ n = 1 10 ( y ^ n − f ( x c p n ) ) 2 , 将 【 f ( x ) = y 】 , 【 y = b + w ⋅ x c p 】 代 入 = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p ) ) 2 \begin{aligned} L(f) & = \sum_{n=1}^{10}\left ( \hat{y}^n - f(x_{cp}^n) \right )^2,将【f(x) = y】, 【y= b + w·x_{cp}】代入 \ & = \sum_{n=1}^{10}\left ( \hat{y}^n - (b + w·x_{cp}) \right )^2\ \end{aligned} L(f)=n=1∑10(y^n−f(xcpn))2,将【f(x)=y】,【y=b+w⋅xcp】代入 =n=1∑10(y^n−(b+w⋅xcp))2
最终定义 损失函数 Loss function: L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p ) ) 2 L(w,b)= \sum_{n=1}^{10}\left ( \hat{y}^n - (b + w·x_{cp}) \right )^2 L(w,b)=∑n=110(y^n−(b+w⋅xcp))2
我们将 w w w, b b b 在二维坐标图中展示,如图所示:
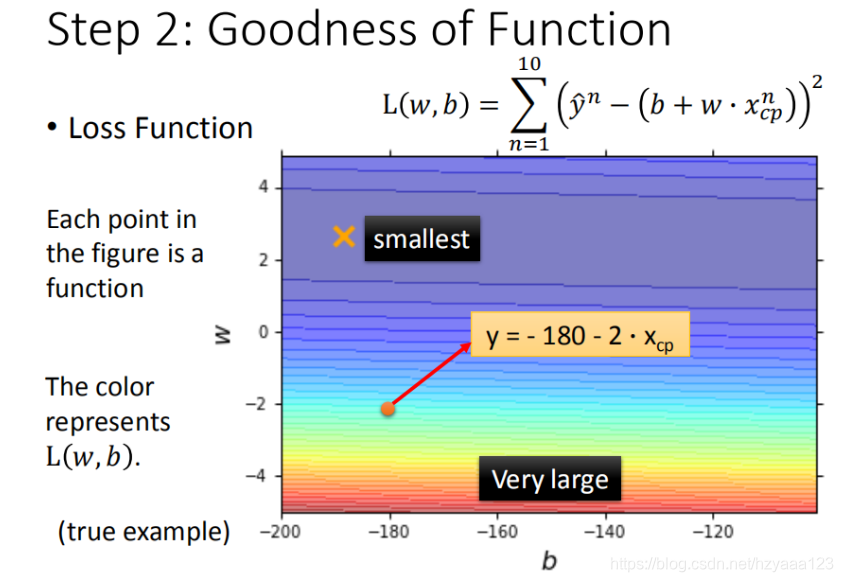
- 图中每一个点代表着一个模型对应的 w w w 和 b b b
- 颜色越深代表模型更优
可以与后面的等高线进行对比。
2.3 模型优化
2.3.1 梯度下降算法
对于单个特征: x c p x_{cp} xcp
如何筛选最优的模型(参数w,b),也就是模型优化需要解决的问题。
已知损失函数是 L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p ) ) 2 L(w,b)= \sum_{n=1}^{10}\left ( \hat{y}^n - (b + w·x_{cp}) \right )^2 L(w,b)=∑n=110(y^n−(b+w⋅xcp))2 ,需要找到一个令结果最小的 f ∗ f^* f∗,在实际的场景中,我们遇到的参数肯定不止 w w w, b b b。
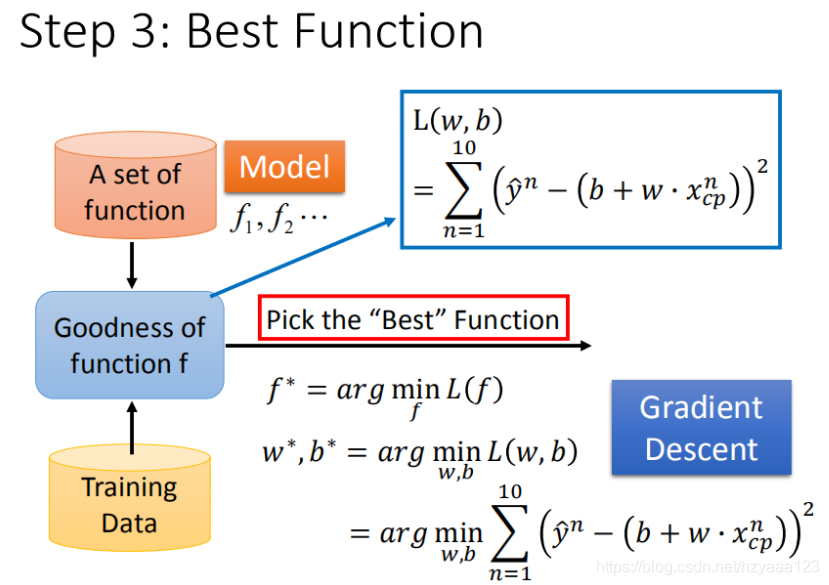 先从最简单的只有一个参数 w w w入手,定义 w ∗ = a r g min x L ( w ) w^* = arg\ \underset{x}{\operatorname{\min}} L(w) w∗=arg xminL(w)
先从最简单的只有一个参数 w w w入手,定义 w ∗ = a r g min x L ( w ) w^* = arg\ \underset{x}{\operatorname{\min}} L(w) w∗=arg xminL(w)
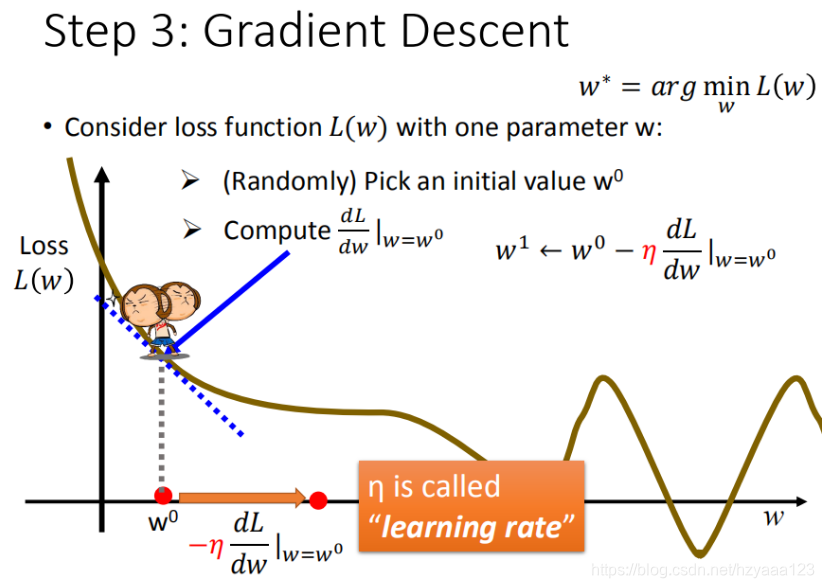
首先在这里引入一个概念 学习率 :移动的步长,如图中 η \eta η
- 步骤1:随机选取一个 w 0 w^0 w0
- 步骤2:计算微分,也就是当前的斜率,根据斜率来判定移动的方向
- 大于0向右移动(增加 w w w)
- 小于0向左移动(减少 w w w)
- 步骤3:根据学习率移动
- 重复步骤2和步骤3,直到找到最低点
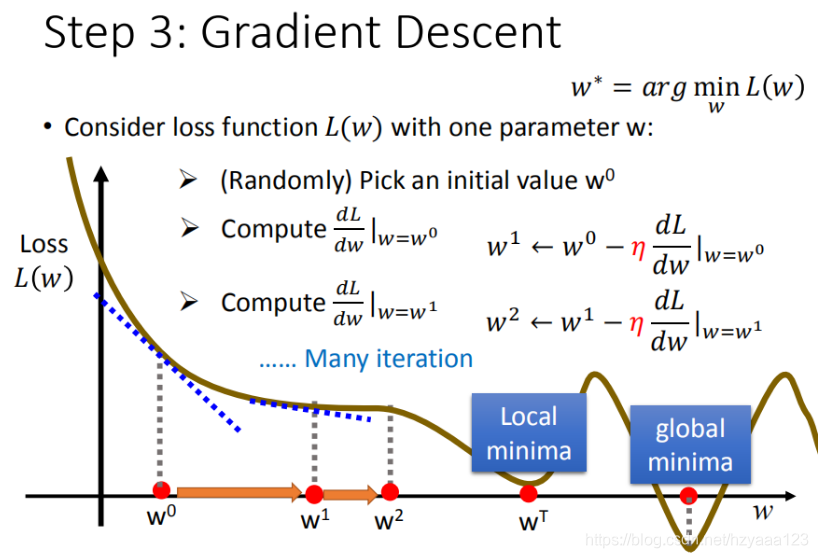 步骤1中,我们随机选取一个 w 0 w^0 w0,如图8所示,我们有可能会找到当前的最小值,并不是全局的最小值,这里我们保留这个疑问,后面解决。
步骤1中,我们随机选取一个 w 0 w^0 w0,如图8所示,我们有可能会找到当前的最小值,并不是全局的最小值,这里我们保留这个疑问,后面解决。
解释完单个模型参数 w w w,引入2个模型参数 w w w 和 b b b , 其实过程是类似的,需要做的是偏微分
 整理成一个更简洁的公式:
整理成一个更简洁的公式:
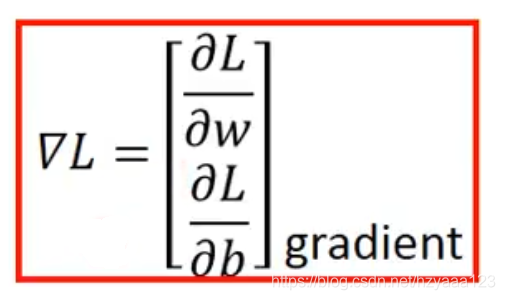 如果把 w w w 和 b b b 在图形中展示:
如果把 w w w 和 b b b 在图形中展示:
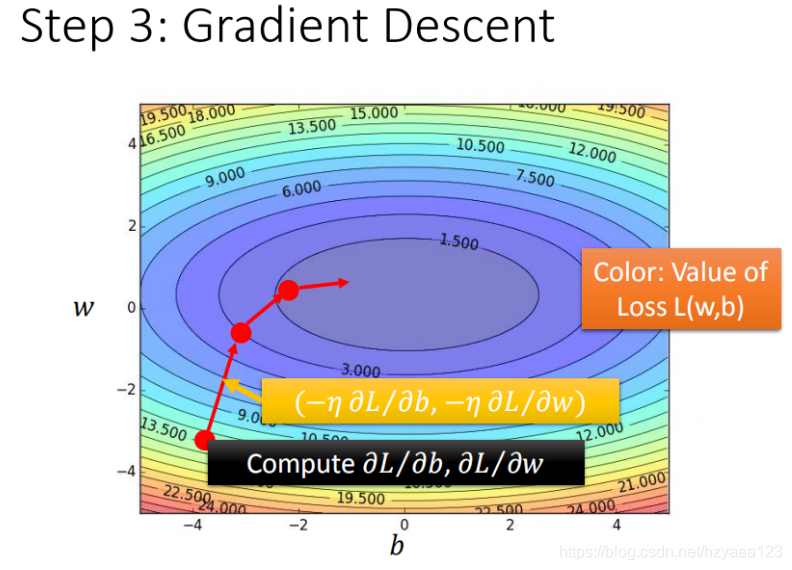
- 每一条线围成的圈就是等高线,代表损失函数的值,颜色约深的区域代表的损失函数越小
- 红色的箭头代表等高线的法线方向
2.3.2 梯度下降算法存在的问题
- 问题1:当前最优(Stuck at local minima)
- 问题2:等于0(Stuck at saddle point)
- 问题3:趋近于0(Very slow at the plateau)
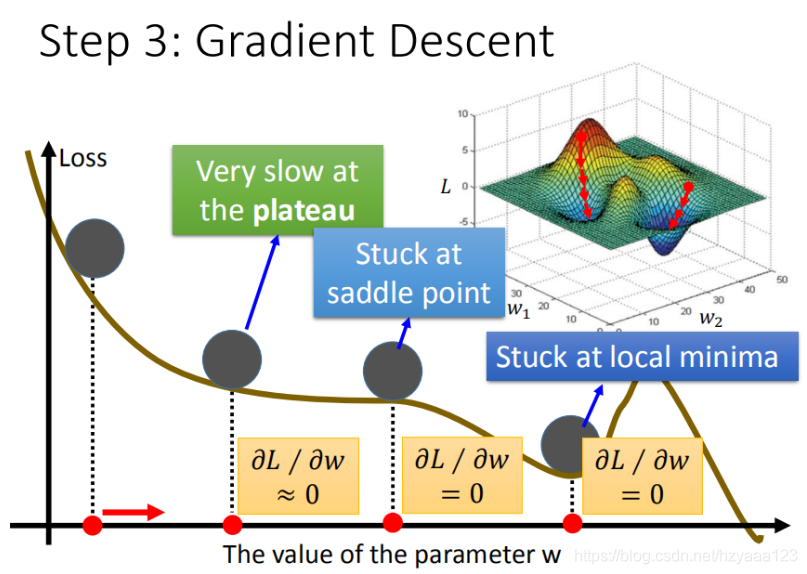
注意:其实在线性模型里面都是一个碗的形状(也就是上一节的那个w和b变化的等高线图),梯度下降基本上都能找到最优点,因此对于我们这次讨论的线性模型不存在上述问题。但是再其他更复杂的模型里面,就会遇到 问题2 和 问题3 了。
3、如何验证训练好的模型的好坏
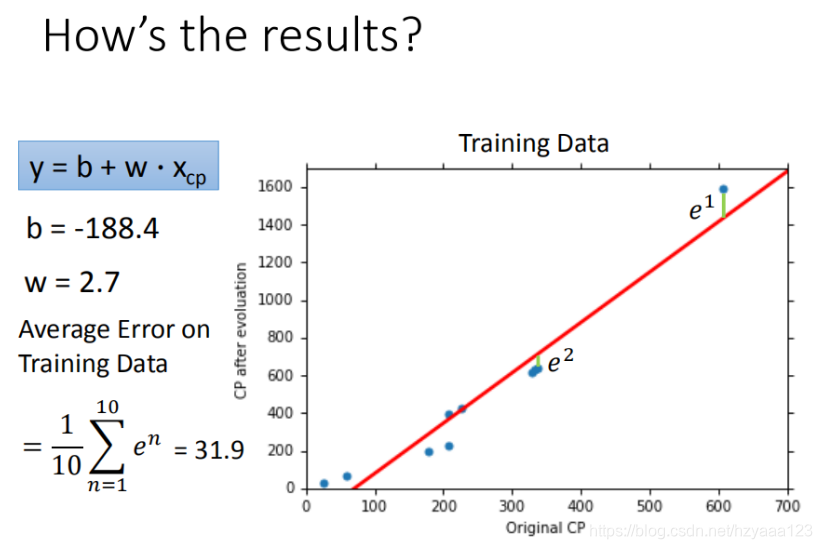
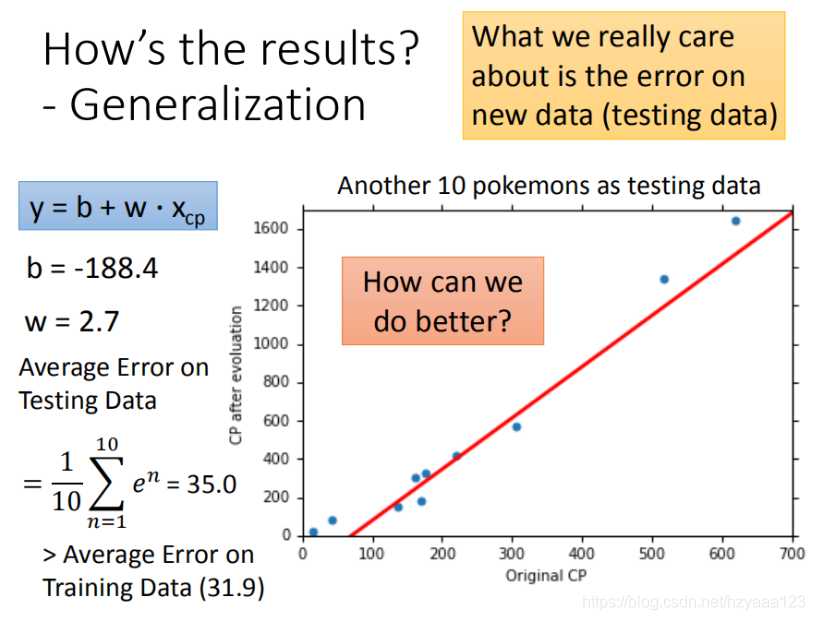
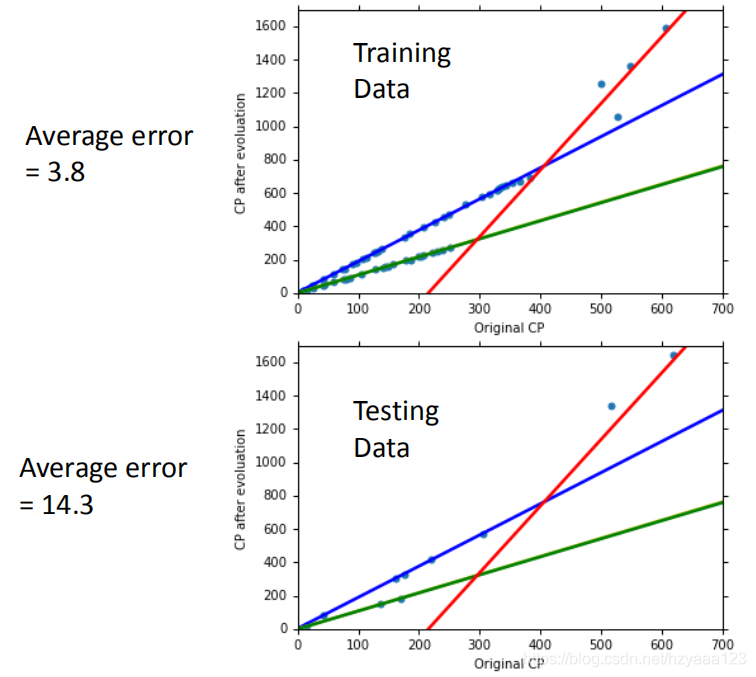
使用训练集和测试集的平均误差来验证模型的好坏 我们使用将10组原始数据,训练集求得平均误差为31.9,如图所示:
然后再使用10组Pokemons测试模型,测试集求得平均误差为35.0 如图所示:
4、对于模型选择方面的改进
4.1 选择高阶的线性模型
在模型选择上,我们可以选取更复杂的模型。使用1元2次方程举例,如图,发现训练集求得平均误差为15.4,测试集的平均误差为18.4。
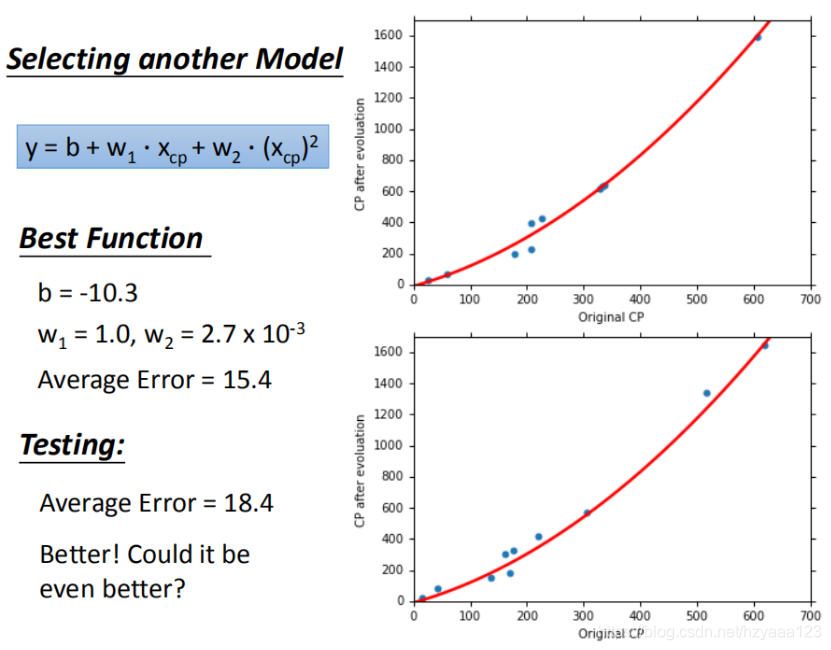
注意:是不是能画出直线就是线性模型,各种复杂的曲线就是非线性模型? 其实还是线性模型,因为把 x c p 1 x_{cp}^1 xcp1 = ( x c p ) 2 (x_{cp})^2 (xcp)2 看作一个特征,那么 y = b + w 1 ⋅ x c p + w 2 ⋅ x c p 1 y = b + w_1·x_{cp} + w_2·x_{cp}^1 y=b+w1⋅xcp+w2⋅xcp1 其实就是线性模型。
4.2 当阶数更高可能出现过拟合问题
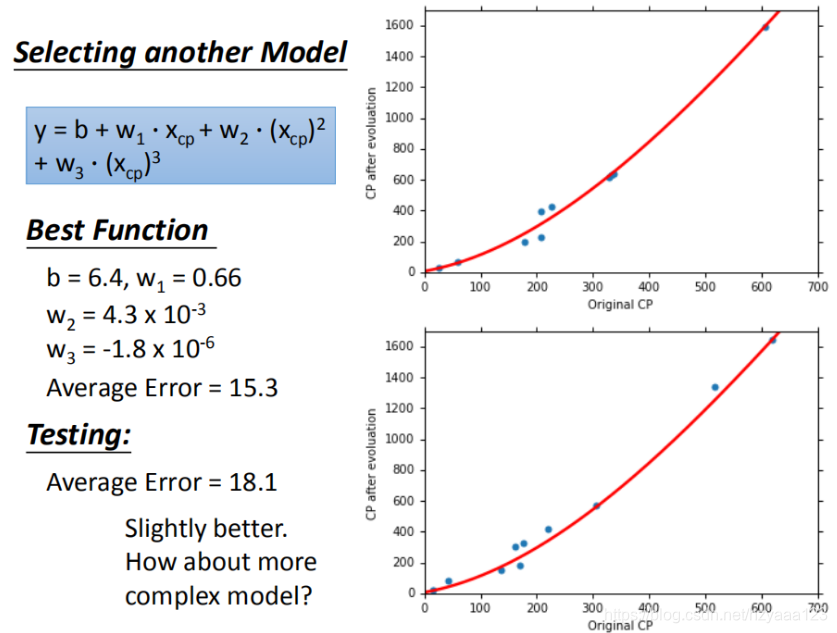
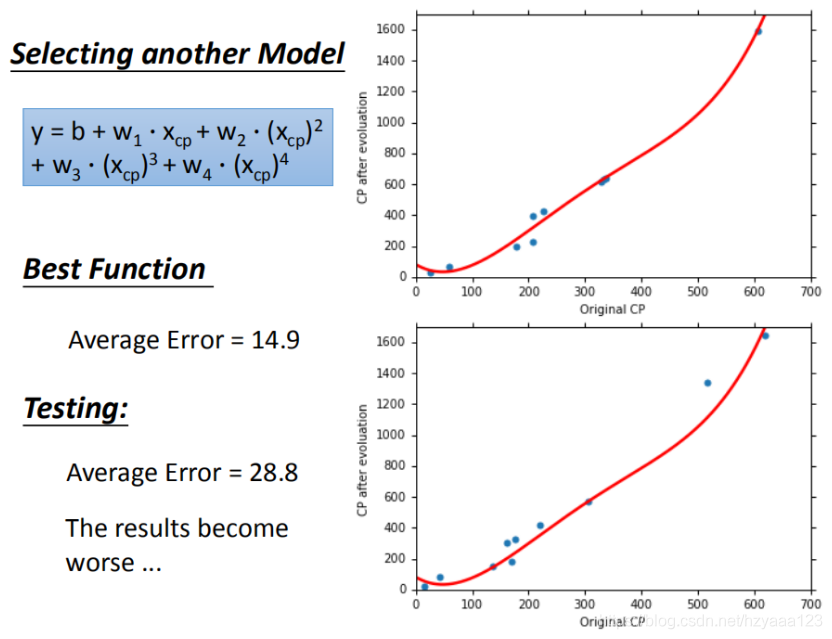
在模型上,我们再可以进一部优化,使用更高次方的模型,如图所示
训练集平均误差【15.4】【15.3】【14.9】【12.8】
测试集平均误差【18.4】【18.1】【28.8】【232.1】
三次模型:
 四次模型:
四次模型:
 五次模型:
五次模型:
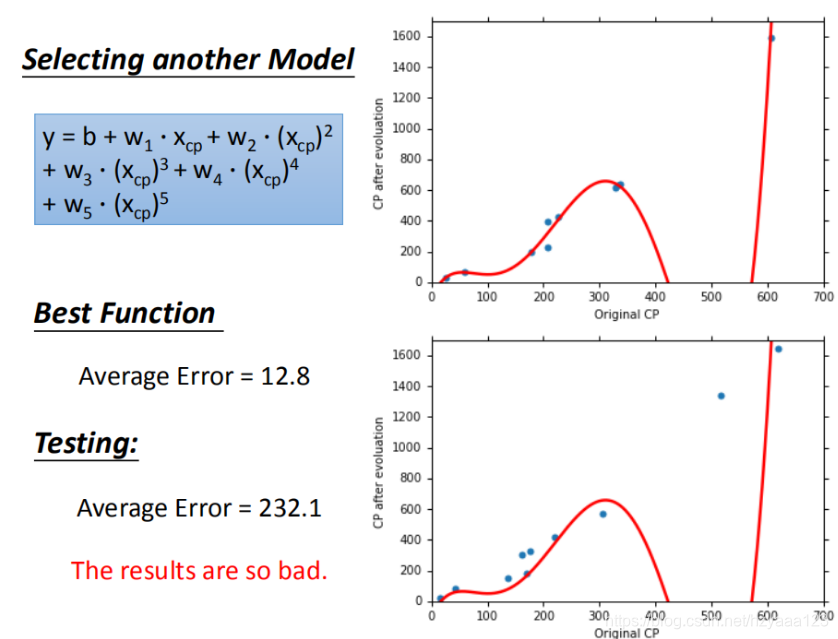
在训练集上面表现更为优秀的模型,为什么在测试集上效果反而变差了?这就是模型在训练集上过拟合的问题。
如图所示,每一个模型结果都是一个集合, 5 次 模 型 包 ⊇ 4 次 模 型 ⊇ 3 次 模 型 5次模型包 \supseteq 4次模型 \supseteq 3次模型 5次模型包⊇4次模型⊇3次模型 所以在4次模型里面找到的最佳模型,肯定不会比5次模型里面找到更差。
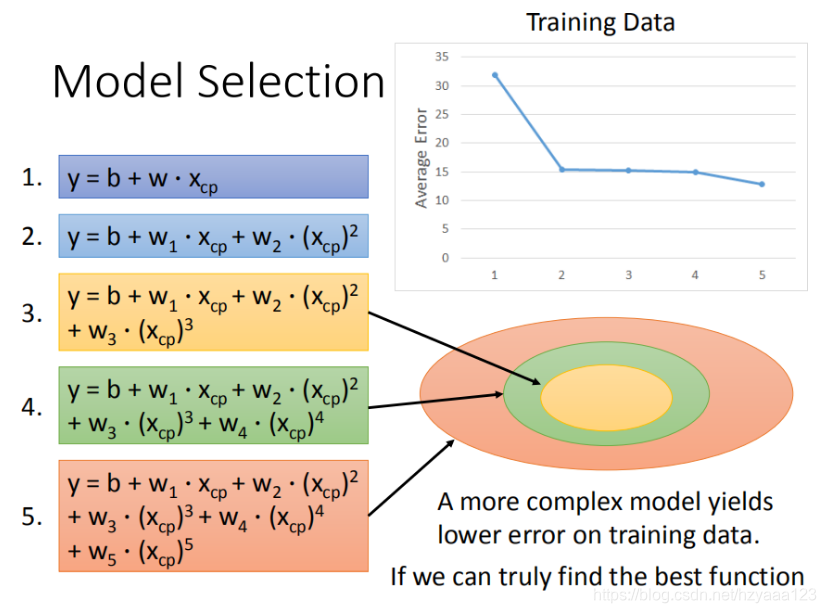
将错误率结果图形化展示,发现3次方以上的模型,已经出现了过拟合的现象:

4.3 模型优化的进一步尝试
因为单纯的增加次方数可能出现过拟合问题,因此我们进行其他方面的尝试:
4.3.1 尝试1:2个input的四个线性模型是合并到一个线性模型中
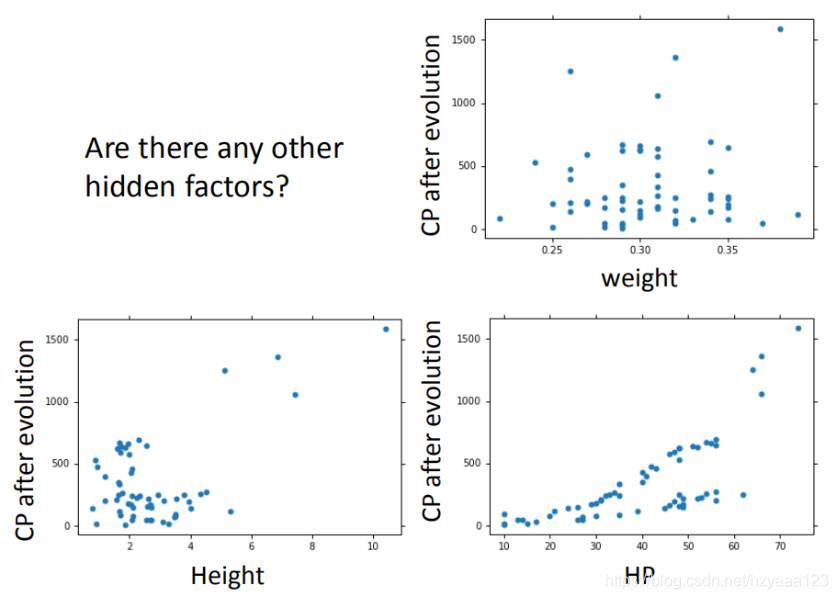
输入更多Pokemons数据,相同的起始CP值,但进化后的CP差距竟然是2倍。如图,其实将Pokemons种类通过颜色区分,就会发现Pokemons种类是隐藏得比较深得特征,不同Pokemons种类影响了进化后的CP值的结果。

通过对 Pokemons种类 判断,将 4个线性模型 合并到一个线性模型中
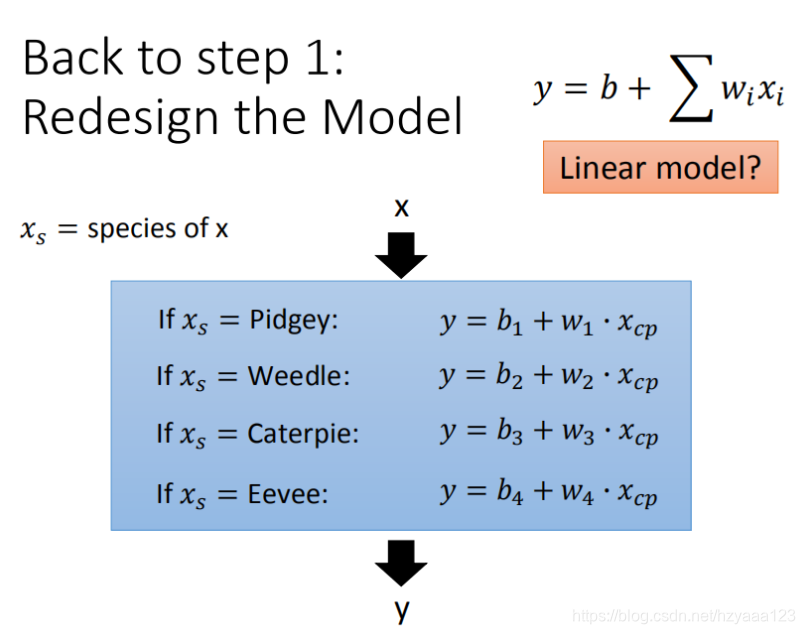
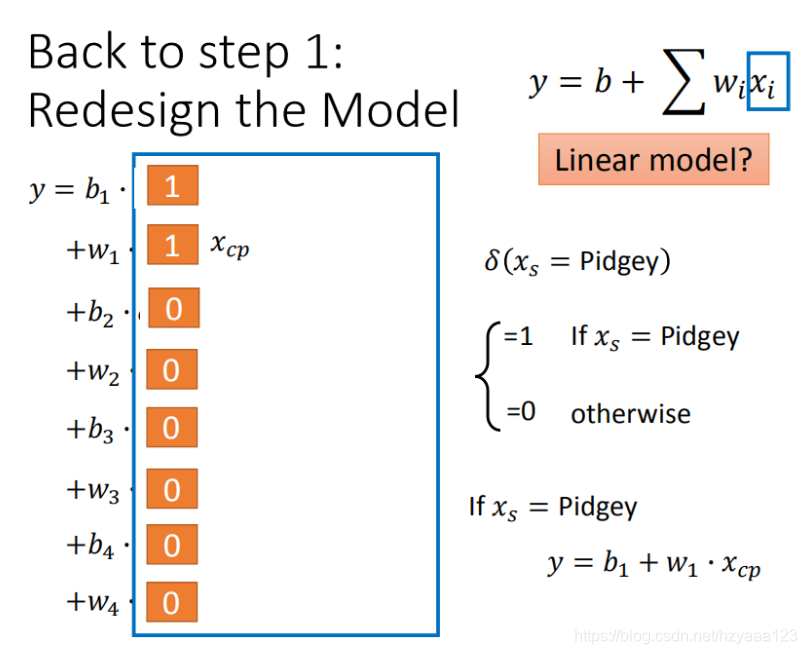
4.3.2 尝试2:希望模型更强大表现更好(更多参数,更多input)
在最开始我们有很多特征,图形化分析特征,将血量(HP)、重量(Weight)、高度(Height)也加入到模型中
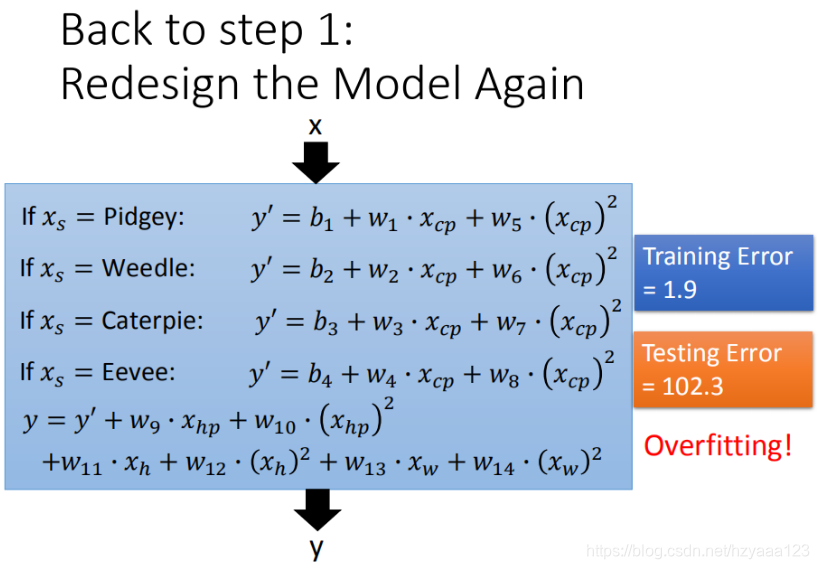
更多特征,更多input,数据量没有明显增加,仍旧导致overfitting
4.3.3 尝试3:加入正则化
更多特征,但是权重 w w w 可能会使某些特征权值过高,仍旧导致overfitting,所以加入正则化。正则化的本质就是让w变化尽量小一点,让曲线更”平滑“,这样输入中的干扰就会对曲线的影响更小一点。

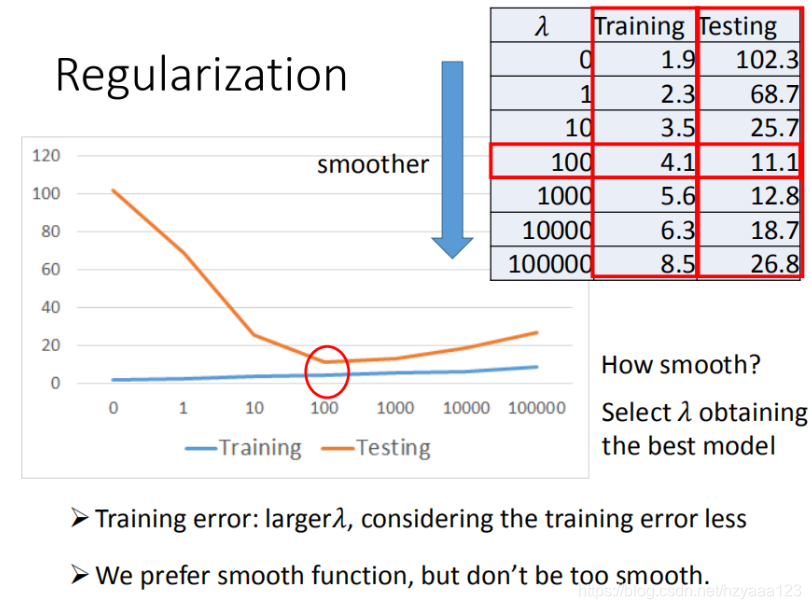
- w w w 越小,表示 f u n c t i o n function function 较平滑的, f u n c t i o n function function输出值与输入值相差不大
- 在很多应用场景中,并不是 w w w 越小模型越平滑越好,但是经验值告诉我们 w w w 越小大部分情况下都是好的。
- b b b 的值接近于0 ,对曲线平滑是没有影响
5、代码实现
现在假设有10个x_data和y_data,x和y之间的关系是y_data=b+w*x_data。b,w都是参数,是需要学习出来的。现在我们来练习用梯度下降找到b和w。
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
# matplotlib没有中文字体,动态解决
plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
x_d = np.asarray(x_data)
y_d = np.asarray(y_data)
x = np.arange(-200, -100, 1)
y = np.arange(-5, 5, 0.1)
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
# loss
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0 # meshgrid吐出结果:y为行,x为列
for n in range(len(x_data)):
Z[j][i] += (y_data[n] - b - w * x_data[n]) ** 2
Z[j][i] /= len(x_data)
# linear regression
#b = -120
#w = -4
b=-2
w=0.01
lr = 0.000005
iteration = 1400000
b_history = [b]
w_history = [w]
loss_history = []
import time
start = time.time()
for i in range(iteration):
m = float(len(x_d))
y_hat = w * x_d +b
loss = np.dot(y_d - y_hat, y_d - y_hat) / m
grad_b = -2.0 * np.sum(y_d - y_hat) / m
grad_w = -2.0 * np.dot(y_d - y_hat, x_d) / m
# update param
b -= lr * grad_b
w -= lr * grad_w
b_history.append(b)
w_history.append(w)
loss_history.append(loss)
if i % 10000 == 0:
print("Step %i, w: %0.4f, b: %.4f, Loss: %.4f" % (i, w, b, loss))
end = time.time()
print("大约需要时间:",end-start)
# plot the figure
plt.subplot(1, 2, 1)
C = plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet')) # 填充等高线
# plt.clabel(C, inline=True, fontsize=5)
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("线性回归")
plt.subplot(1, 2, 2)
loss = np.asarray(loss_history[2:iteration])
plt.plot(np.arange(2, iteration), loss)
plt.title("损失")
plt.xlabel('step')
plt.ylabel('loss')
plt.show()
输出结果如图:
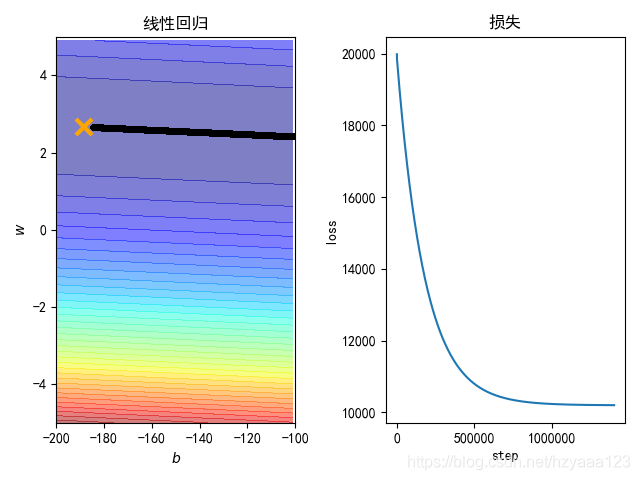
按照正常来说,不应该能够达到最优点,因此这里的结果可能有一些问题,会在后面的博客中重新修正。
智能推荐
程序员考试补课笔记-第十八天_[说明] 设一个环上有编号为0~n-1的n粒颜色不尽相同的珠子(每粒珠子颜色用字母表-程序员宅基地
文章浏览阅读3.1k次。 什么都不用说了,马上入正题(免得给人说我口水多了,哈哈)。那么今天学了些什么呢?知识当然每天都要吸收,但在乎吸收得多少。有时候一个看起来的小问题,其实足可以引发另一些问题,这一切都是靠自己,看自己怎么对待这些问题。 我们现在来做一道初程的题目,大家也不要看少初程的题喔,其实这题我在中程的试题来看到过,不过不同的地方只是把它改为用指针了。所以这里也想说说,其实中程里绝大部份的题都是_[说明] 设一个环上有编号为0~n-1的n粒颜色不尽相同的珠子(每粒珠子颜色用字母表
markdown插入图片_markdom 插图-程序员宅基地
文章浏览阅读83次。markdown插入图片注意事项在markdown插入图片,光标要放在最前面,要不插入的图片不显示_markdom 插图
[WinError 127] 找不到指定的程序。 Error loading “D:\A\lib\site-packages\torch\lib\c10_cuda.dill_error loading "d:\anaconda\lib\site-packages\torch-程序员宅基地
文章浏览阅读7k次,点赞5次,收藏9次。可以参考一下几种解决方法:1、可能由于缺少VC++ Redistributable,在错误中会提示你下载并且提供了下载地址,只需要下载并默认安装即可;2、方法1如果不行,可以更新numpy;参考这个连接3、或者使用pip install intel-openmp,试试,参考这个连接。..._error loading "d:\anaconda\lib\site-packages\torch\lib\c10_cuda.dll" or one
BIOS的基本概念和理解_bios硬件的软件抽象-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏11次。1.基本概念BIOS(Basic Input/Output System)基本输入输出系统。是一种业界标准的固件接口;BIOS是个人电脑启动时候加载的第一个软件;BIOS用于电脑开机时,运行系统各部分的自我检测,并加载引导程序或存储在主存上的作业系统;BIOS向作业系统提供一些系统参数;系统硬件的变化是由BIOS隐藏,程序使用BIOS功能而不是直接控制硬件。现代作业系统会忽_bios硬件的软件抽象
Rockchip之RK3288HDMI接口插拔检测_hpd脚-程序员宅基地
文章浏览阅读5.3k次,点赞11次,收藏29次。Rockchip之RK3288HDMI接口插拔检测任务背景:最近机器的一块屏出现不显示或者白屏现象,这块屏是一块MIPI屏,但它是由3288上的HDMI接口通过一块LPC转接板转成MIPI接口的,所以根源还是HDMI接口,猜想可能是HDMI转MIPI的HDMI插拔检测脚导致的,因此,试着把这个插入检测去掉让HDMI信号直接输出看看结果,首先查看原理图检测脚为HDMI_HPD这个脚,首先介绍..._hpd脚
使用PyQt的QTableWidget来创建表格,并通过设置委托实现选中某个单元格时的背景颜色变化是一种常见的需求。在本文中,我将为您提供详细的代码示例和解释。_pyqt5 tablewidget 设置单元格颜色-程序员宅基地
文章浏览阅读203次。使用PyQt的QTableWidget来创建表格,并通过设置委托实现选中某个单元格时的背景颜色变化是一种常见的需求。在本文中,我将为您提供详细的代码示例和解释。接下来,我们使用双重循环创建了一些示例数据,并将其设置为表格的单元格项。最后,我们将表格设置为主窗口的中央部件,并显示主窗口。接下来,我们将创建一个简单的PyQt应用程序,并在其中添加一个QTableWidget。在上述代码中,我们首先导入了所需的类和模块。方法中,我们检查选中状态,并根据需要设置单元格的背景颜色。实例,并设置了行数和列数。_pyqt5 tablewidget 设置单元格颜色
随便推点
文献检索与应用_试述常用的二种医学专业搜索引擎的特色与检索方法?-程序员宅基地
文章浏览阅读3.8k次。信息检索的方法有多种,分别使用于不同的检索目的和检索要求。归纳起来,常用的信息检索方法有常规检索法、回溯检索法、循环检索法。1.常规检索法。又称常用检索法、工具检索法。它以主题、分类、作者等为检索点,利用检索工具获的信息资源的方法。根据检索方式,常规检索法又分为直接检索法和间接检索法;根据检索需求,常规检索法又分为顺查法、倒查法和抽查法。_试述常用的二种医学专业搜索引擎的特色与检索方法?
知识图谱基本概念&工程落地常见问题-程序员宅基地
文章浏览阅读1.1k次。作者:cavities来源:https://zhuanlan.zhihu.com/p/62824358编辑:happyGirl简要说明一下,搞了知识图谱架构一年半,快两年的一些小心得,后..._图谱能做到哪些知关系据库做不到的
关于unity中的update、Lateupdate和FixedUpdate。_unitylateupdate-程序员宅基地
文章浏览阅读1k次。MonoBehaviour.Update 更新 当MonoBehaviour启用时,其Update在每一帧被调用。 MonoBehaviour.FixedUpdate固定更新 当MonoBehaviour启用时,其 FixedUpdate在每一帧被调用。 处理Rigidbody时,需要用FixedUpdate代替Upd_unitylateupdate
PL/SQL Developer连接本地Oracle 11g 64位数据库_oracle11gr2 plsql dev-程序员宅基地
文章浏览阅读283次。登陆PL/SQL假定本地电脑中已经安装了Oracle 11gR2数据库和PL/SQL developer。如果没有安装可以在一下地址下载安装:Oracle 11gR2数据库:https://www.oracle.com/technetwork/database/enterprise-edition/downloads/112010-win64soft-094461.htmlPL/SQL developer(含注册机):https://pan.baidu.com/s/1kUfY8GB 密码: 1ky8_oracle11gr2 plsql dev
HDOJ1015-Safecracker优化版_safecracker hdoj-程序员宅基地
文章浏览阅读125次。纯暴力搜索是可以过的。但要求答案是最大的字典序,显然先排序后搜索可以一遍求出答案后就返回。但新手写回溯会出种种bug,最经典莫过于不知道如何返回而陷入死循环。这里给出一个参考代码:#include<iostream>#include<stdio.h>#include<string.h>#include<algorithm>#include<map>#include<queue>#include<string>_safecracker hdoj
蓝桥试题 算法提高 书院主持人 JAVA_蓝桥杯试题 算法提高 书院主持人java-程序员宅基地
文章浏览阅读4.5k次。问题描述 北大附中书院有m个同学,他们每次都很民主地决策很多事情。按罗伯特议事规则,需要一个主持人。同学们民主意识强,积极性高,都想做主持人,当然主持人只有一人。为了选出主持人,他们想到了一个办法并认为很民主。方法是: 大家围成一圈,从1到m为每个同学编号。然后从1开始报数, 数到n的出局。剩下的同学从下位开始再从1开始报数。最后剩下来的就是主持人了。现在已经把同学从1到m编号,并约定报数..._蓝桥杯试题 算法提高 书院主持人java