【数据结构与算法】-哈夫曼树(Huffman Tree)与哈夫曼编码_哈夫曼编码树-程序员宅基地
技术标签: 算法 c语言 霍夫曼树 数据结构与算法 数据结构
超详细讲解哈夫曼树(Huffman Tree)以及哈夫曼编码的构造原理、方法,并用代码实现。
1哈夫曼树基本概念
路径:从树中一个结点到另一个结点之间的分支构成这两个结点间的路径。
结点的路径长度:两结点间路径上的分支数。

树的路径长度:从树根到每一个结点的路径长度之和。记作: TL 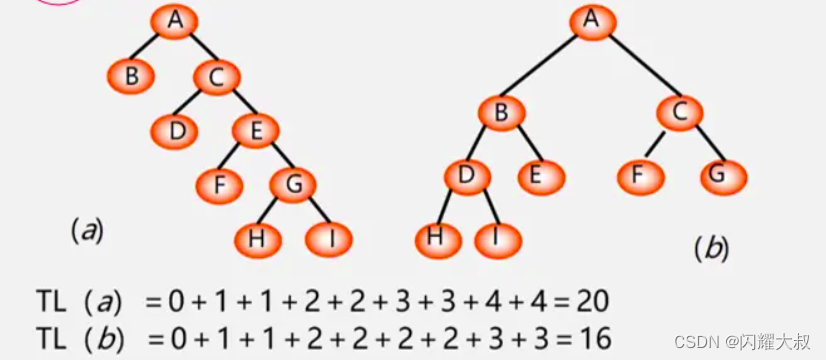
权(weight)又称权重:将树中结点赋给一个有着某种含义的数值,(具体的意义根据树使用的场合确定)则这个数值称为该结点的权。比如之前提到的判断树中5%表示对应分数段人在总人数中的比例
结点的带权路径长度:从根结点到该结点之间的路径长度与结点上权的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和。
树的路径长度:从树根到每一个结点的路径长度之和。
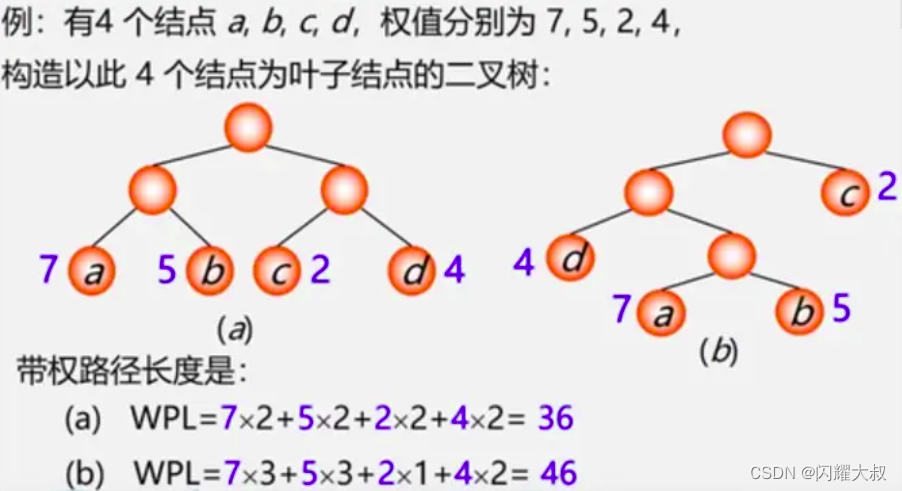
哈夫曼树:最优树,带权路径长度(WPL)最短的树
“带权路径长度最短”是在“度相同”的树中比较而得的结果,因此有最优二叉树、最优三叉树之称。
哈夫曼树:最优二叉树,带权路径长度(WPL)最短的二叉树,因为构造这种树的算法是由哈夫曼教授于1952年提出的,所以被称为哈夫曼树,相应的算法称为哈夫曼算法。
2.哈夫曼树构造算法
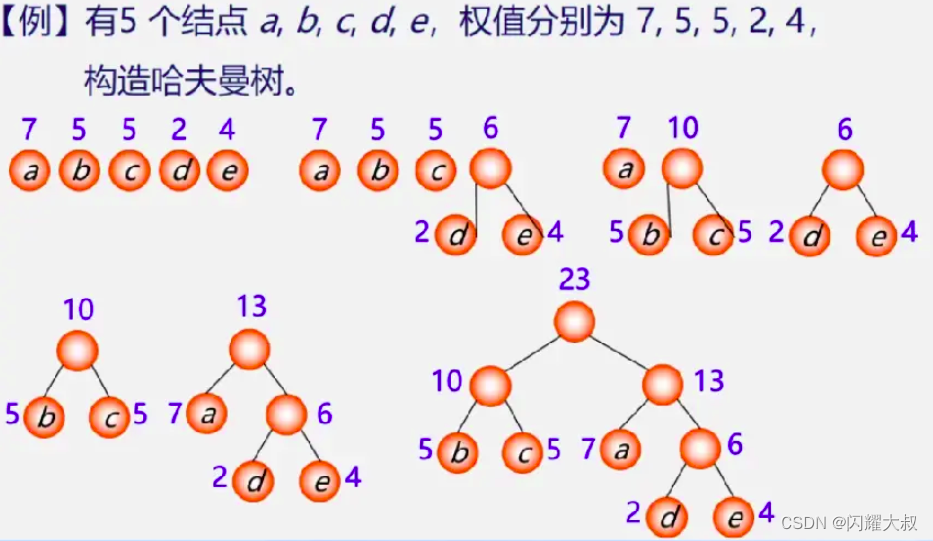
哈夫曼算法(构造哈夫曼树的方法)
(1)根据n个给定的权值(W1,W2,..., Wn)构成n棵二叉树的森林F=(T1, T2,.., Tn),其中Ti只有一个带权为Wi;的根结点。
构造森林全是根
(2)在F中选取两棵根结点的权值最小的树作为左右子树,构造一棵新的二叉树,且设置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
选用两小造新树
(3)在F中删除这两棵树,同时将新得到的二叉树加入森林中。
删除两小添新人
(4)重复(2)和(3),直到森林中只有一棵树为止,这棵树即为哈夫曼树。
重复2、3剩单根

总结
1、在哈夫曼算法中,初始时有n棵二叉树,要经过n-1次合并最终形成哈夫曼树。
2、经过n-1次合并产生n-1个新结点,且这n-1个新结点都是具有两个孩子的分支结点。
可见:哈夫曼树中共有n+n-1 =2n-1个结点,且其所有的分支结点的度均不为1。
3.构建哈夫曼树代码实现
3.1哈弗曼树中结点结构
构建哈夫曼树时,首先需要确定树中结点的构成。
由于哈夫曼树的构建是从叶子结点开始,不断地构建新的父结点,直至树根,所以结点中应包含指向父结点的指针。但是在使用哈夫曼树时是从树根开始,根据需求遍历树中的结点,因此每个结点需要有指向其左孩子和右孩子的指针。
//哈夫曼树结点结构
typedef struct {
int weight;//结点权重
int parent, left, right;//父结点、左孩子、右孩子在数组中的位置下标
}HTNode, *HuffmanTree;

3.2哈弗曼树中的查找算法
构建哈夫曼树时,需要每次根据各个结点的权重值,筛选出其中值最小的两个结点,然后构建二叉树。
查找权重值最小的两个结点的思想是:从树组起始位置开始,首先找到两个无父结点的结点(说明还未使用其构建成树),然后和后续无父结点的结点依次做比较,有两种情况需要考虑:
- 如果比两个结点中较小的那个还小,就保留这个结点,删除原来较大的结点;
- 如果介于两个结点权重值之间,替换原来较大的结点;
//HT数组中存放的哈夫曼树,end表示HT数组中存放结点的最终位置,s1和s2传递的是HT数组中权重值最小的两个结点在数组中的位置
void Select(HuffmanTree HT, int end, int *s1, int *s2)
{
int min1, min2;
//遍历数组初始下标为 1
int i = 1;
//找到还没构建树的结点
while(HT[i].parent != 0 && i <= end){
i++;
}
min1 = HT[i].weight;
*s1 = i;
i++;
while(HT[i].parent != 0 && i <= end){
i++;
}
//对找到的两个结点比较大小,min2为大的,min1为小的
if(HT[i].weight < min1){
min2 = min1;
*s2 = *s1;
min1 = HT[i].weight;
*s1 = i;
}else{
min2 = HT[i].weight;
*s2 = i;
}
//两个结点和后续的所有未构建成树的结点做比较
for(int j=i+1; j <= end; j++)
{
//如果有父结点,直接跳过,进行下一个
if(HT[j].parent != 0){
continue;
}
//如果比最小的还小,将min2=min1,min1赋值新的结点的下标
if(HT[j].weight < min1){
min2 = min1;
min1 = HT[j].weight;
*s2 = *s1;
*s1 = j;
}
//如果介于两者之间,min2赋值为新的结点的位置下标
else if(HT[j].weight >= min1 && HT[j].weight < min2){
min2 = HT[j].weight;
*s2 = j;
}
}
}3.3 构建算法实现
//HT为地址传递的存储哈夫曼树的数组,w为存储结点权重值的数组,n为结点个数
void CreateHuffmanTree(HuffmanTree *HT, int *w, int n)
{
if(n<=1) return; // 如果只有一个编码就相当于0
int m = 2*n-1; // 哈夫曼树总节点数,n就是叶子结点
*HT = (HuffmanTree) malloc((m+1) * sizeof(HTNode)); // 0号位置不用
HuffmanTree p = *HT;
// 初始化哈夫曼树中的所有结点
for(int i = 1; i <= n; i++)
{
(p+i)->weight = *(w+i-1);
(p+i)->parent = 0;
(p+i)->left = 0;
(p+i)->right = 0;
}
//从树组的下标 n+1 开始初始化哈夫曼树中除叶子结点外的结点
for(int i = n+1; i <= m; i++)
{
(p+i)->weight = 0;
(p+i)->parent = 0;
(p+i)->left = 0;
(p+i)->right = 0;
}
//构建哈夫曼树
for(int i = n+1; i <= m; i++)
{
int s1, s2;
Select(*HT, i-1, &s1, &s2);
(*HT)[s1].parent = (*HT)[s2].parent = i;
(*HT)[i].left = s1;
(*HT)[i].right = s2;
(*HT)[i].weight = (*HT)[s1].weight + (*HT)[s2].weight;
}
}4.哈夫曼编码
4.1哈夫曼编码基本概念
在远程通讯中,要将待传字符转换成由二进制的字符串
若将编码设计为长度不等的二进制编码,即让待传字符串中出现次数较多的字符采用尽可能短的编码,则转换的二进制字符串便可能减少。
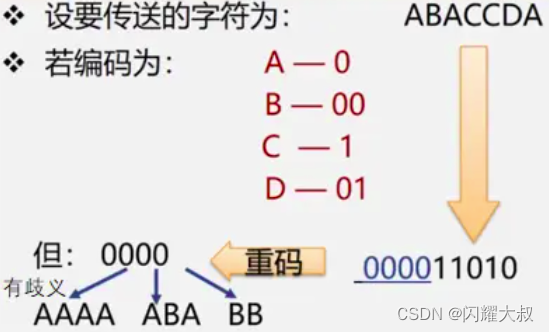
关键:要设计长度不等的编码,则必须使任一字符的编码都不是另一个字符的编码的前缀,这种编码称做前缀编码。
问题:什么样的前缀码能使得电文总长最短?
哈夫曼编码方法:
1、统计字符集中每个字符在电文中出现的平均概率(概率越大,要求编码越短)
2、利用哈夫曼树的特点:权越大的叶子离根越近;将每个字符的概率值作为权值,构造哈夫曼树。则概率越大的结点,路径越短。
3、在哈夫曼树的每个分支上标上0或1:
结点的左分支标0,右分支标1
把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码。

两个问题:
1.为什么哈夫曼编码能够保证是前缀编码?
因为没有一片树叶是另一片树叶的祖先,所以每个叶结点的编码就不可能是其它叶结点编码的前缀。(字符都是叶子结点,根到一个字符不会路过另一个字符T)
2.为什么哈夫曼编码能够保证字符编码总长最短?
因为哈夫曼树的带权路径长度最短,故字符编码的总长最短。
性质1哈夫曼编码是前缀码
性质2哈夫曼编码是最优前缀码
4.2哈夫曼编码代码实现
使用程序求哈夫曼编码有两种方法:
- 从叶子结点一直找到根结点,逆向记录途中经过的标记。例如,图 3 中字符 c 的哈夫曼编码从结点 c 开始一直找到根结点,结果为:0 1 1 ,所以字符 c 的哈夫曼编码为:1 1 0(逆序输出)。
- 从根结点出发,一直到叶子结点,记录途中经过的标记。例如,求图 3 中字符 c 的哈夫曼编码,就从根结点开始,依次为:1 1 0。
采用方法 1 的实现代码为:
//HT为哈夫曼树,HC为存储结点哈夫曼编码的二维动态数组,n为结点的个数
void HuffmanCoding(HuffmanTree HT, HuffmanCode *HC,int n){
*HC = (HuffmanCode) malloc((n+1) * sizeof(char *));
char *cd = (char *)malloc(n*sizeof(char)); //存放结点哈夫曼编码的字符串数组
cd[n-1] = '\0';//字符串结束符
for(int i=1; i<=n; i++){
//从叶子结点出发,得到的哈夫曼编码是逆序的,需要在字符串数组中逆序存放
int start = n-1;
//当前结点在数组中的位置
int c = i;
//当前结点的父结点在数组中的位置
int j = HT[i].parent;
// 一直寻找到根结点
while(j != 0){
// 如果该结点是父结点的左孩子则对应路径编码为0,否则为右孩子编码为1
if(HT[j].left == c)
cd[--start] = '0';
else
cd[--start] = '1';
//以父结点为孩子结点,继续朝树根的方向遍历
c = j;
j = HT[j].parent;
}
//跳出循环后,cd数组中从下标 start 开始,存放的就是该结点的哈夫曼编码
(*HC)[i] = (char *)malloc((n-start)*sizeof(char));
strcpy((*HC)[i], &cd[start]);
}
//使用malloc申请的cd动态数组需要手动释放
free(cd);
}采用第二种算法的实现代码为:
//HT为哈夫曼树,HC为存储结点哈夫曼编码的二维动态数组,n为结点的个数
void HuffmanCoding(HuffmanTree HT, HuffmanCode *HC,int n){
*HC = (HuffmanCode) malloc((n+1) * sizeof(char *));
int m=2*n-1;
int p=m;
int cdlen=0;
char *cd = (char *)malloc(n*sizeof(char));
//将各个结点的权重用于记录访问结点的次数,首先初始化为0
for (int i=1; i<=m; i++) {
HT[i].weight=0;
}
//一开始 p 初始化为 m,也就是从树根开始。一直到p为0
while (p) {
//如果当前结点一次没有访问,进入这个if语句
if (HT[p].weight==0) {
HT[p].weight=1;//重置访问次数为1
//如果有左孩子,则访问左孩子,并且存储走过的标记为0
if (HT[p].left!=0) {
p=HT[p].left;
cd[cdlen++]='0';
}
//当前结点没有左孩子,也没有右孩子,说明为叶子结点,直接记录哈夫曼编码
else if(HT[p].right==0){
(*HC)[p]=(char*)malloc((cdlen+1)*sizeof(char));
cd[cdlen]='\0';
strcpy((*HC)[p], cd);
}
}
//如果weight为1,说明访问过一次,即是从其左孩子返回的
else if(HT[p].weight==1){
HT[p].weight=2;//设置访问次数为2
//如果有右孩子,遍历右孩子,记录标记值 1
if (HT[p].right!=0) {
p=HT[p].right;
cd[cdlen++]='1';
}
}
//如果访问次数为 2,说明左右孩子都遍历完了,返回父结点
else{
HT[p].weight=0;
p=HT[p].parent;
--cdlen;
}
}
}智能推荐
联想笔记本Fn+Q性能调节模式失效_联想fn+q三种模式没反应-程序员宅基地
文章浏览阅读2.2k次。在微软应用商店里,搜索:Lenovo Hotkeys、Lenovo Vantage (无前台界面)安装。系统重装后,联想笔记本Fn+Q性能调节模式会失效。_联想fn+q三种模式没反应
Cisco Packet Tracer 实验_for packet tracer skills based assessment(ptsba) t-程序员宅基地
文章浏览阅读392次。Cisco Packet Tracer 实验1. CPT 软件使用简介1.1 Packet Tracer介绍Packet Tracer是Cisco公司针对CCNA认证开发的一个用来设计、配置和故障排除网络的模拟软件。Packer Tracer模拟器软件比Boson功能强大,比Dynamips操作简单,非常适合网络设备初学者使用。Packet Tracer模拟器是考CCNA必须掌握的软件。1.2 路由器2. 直接连接两台 PC 构建 LAN 将两台 PC 直接连接构成一个网络。 _for packet tracer skills based assessment(ptsba) to use this version of pack
GH600光通信综合测试仪-程序员宅基地
文章浏览阅读40次。能满足以上要求的光通信综合测试仪,肯定是可以很大的提高我们的工作效率和让我们去现场检测更加轻松 不需一上山就是一天。那能满足这些要求的机器有哪些呢我这边推荐TFN的GH600这款机器完全满足以上需求,参数各方面也都是业内较高的水平了。随着网络通信的快速发展 单一的网络检测设备 已经 不能满足现代通信的检测需求,那么现代网络通信的检测需求有哪些呢。
uniapp使用uview组件的Collapse 折叠面板,动态渲染之后计算面板的高度_collapse 折叠面板高度问题-程序员宅基地
文章浏览阅读1.2w次,点赞10次,收藏13次。uniapp使用uview组件的Collapse 折叠面板,动态渲染之后计算面板的高度在uniapp里会有使用uview的Collapse折叠面板的情况,但在动态渲染数据之后,面板的内容会显示不全,这时候可以使用ref来重新获取高度;<u-collapse ref="collapseView"> <u-collapse-item :title="item.head" v-for="(item, index) in itemList" :key="index"> {{it_collapse 折叠面板高度问题
前端(二十一)——WebSocket:实现实时双向数据传输的Web通信协议_前端websocket-程序员宅基地
文章浏览阅读6.8k次,点赞13次,收藏67次。在当今互联网时代,实时通信已成为很多应用的需求。为了满足这种需求,WebSocket协议被设计出来。WebSocket是一种基于TCP议的全双工通信协议,通过WebSocket,Web应用程序可以与服务器建立持久的连接,实现实时双向数据输,提供极低的延迟和高效的数据传输。_前端websocket
日常学习办公绘图PDDON使用操作手册-程序员宅基地
文章浏览阅读1k次,点赞24次,收藏17次。画图干货教程,零基础快速绘制线框图、流程图、架构图、思维导图、UML系列图、网络拓扑图、图文混排、日常ppt插图、ER图、数据库模型图、韦恩图、鱼骨图等等,一软搞定。 _pddon
随便推点
TCP与UDP~第二式_tcp urgent pointer-程序员宅基地
文章浏览阅读4.7k次。# TCP与UDP一,分析TCP与UDP报文TCP与UDP都是位于OSI模型传输层的两个协议(1)UDP的报文头:如上图:UDP基本组成包括16位的源端口号和目的端口号+数据通过源端口号和目的端口号来进行传输;数据部分为保存的具体内容UDP的特点: 1,沟通简单,不需要处理逻辑、和数据结构; 2,不会建立连接,但是会监听这个地方,谁的数据都接收,也会传输数据给别人; 3,二愣子,传输完数据..._tcp urgent pointer
进口跨境电商商城源码(海关179接口+支持多平台搭建+提供多终端支持)_跨境电商购物平台源码-程序员宅基地
文章浏览阅读134次。跨境报关商城的出现,为进口商提供了一站式的解决方案,有效降低了进口环节的成本和风险。进口跨境电商商城源码不仅提供了与海关179接口的集成,实现了便捷的报关操作,还支持跨境报关商城的搭建,为进口商提供一站式的解决方案。进口跨境电商商城源码提供了与海关179接口的集成,实现了便捷的报关操作。进口商可以通过商城源码直接与海关进行数据交互,减少了繁琐的人工操作,提高了报关的效率。无论是在电脑上还是在手机上,进口商都可以通过商城源码搭建自己的在线商城,满足不同用户群体的需求。_跨境电商购物平台源码
物联网理解_什么是物联网包括哪两层含义-程序员宅基地
文章浏览阅读6.7k次,点赞14次,收藏56次。物联网概念物联网就是物物相连的互联网。(英文名:Internet of things,简称:IoT)两层意思:物联网的核心和基础仍然是互联网,是在互联网基础上的延伸和扩展的网络其用户延伸和扩展到了任务物品与物品之间,进行信息交换和通信,也就是物物相息。物联网通过智能感知、识别技术与普适计算等通信感知技术,广泛应用于网络的融合中,也因此被称为计算机、互联网之后世界信息产业发展的第三次..._什么是物联网包括哪两层含义
搭建qt+opencv4.3.0环境时候,opencv4.3.0编译报错_vs2017 + qt vs tools +opencv4.3.0 编译出错-程序员宅基地
文章浏览阅读516次。下载好opencv4.3.0的源码之后,先不要急着编译,需要对源码进行修改:需要修改的地址为:文件存放位置\opencv\sources\photo\test\test_hdr.cpp加入包含文件:#include<ctime>#include<cstdlib>然后在cmake-gui将source code 选择到source文件夹,build binaries自行创建然后选择。选好之后点击configure,使用如下选项:然后next,编译器选择自己的编译器,_vs2017 + qt vs tools +opencv4.3.0 编译出错
lumen框架命令行执行脚本_"lumen command \"user-level-fate\" is not defined.-程序员宅基地
文章浏览阅读4.3k次。1.在app->Console->Commands中新增类 继承 Illuminate\Console\Command<?php namespace App\Console\Commands; use Illuminate\Console\Command; class TestCommand extends Command{ /** * 命令行执..._"lumen command \"user-level-fate\" is not defined."
低通滤波器截止频率,带宽_数据低通滤波 截至频率-程序员宅基地
文章浏览阅读4.8k次。http://m.elecfans.com/article/586773.html_数据低通滤波 截至频率