【数据结构】——二叉树详解-程序员宅基地
目录
一、二叉树的定义
二叉树(Binary Tree) 是由n个结点构成的有限集(n≥0),n=0时为空树,n>0时为非空树。对于非空树 T T T:
- 有且仅有一个根结点;
- 除根结点外的其余结点又可分为两个不相交的子集 T L T_L TL和 T R T_R TR,分别称为 T T T的左子树和右子树,且 T L T_L TL和 T R T_R TR本身又都是二叉树。
很明显该定义属于递归定义,所以有关二叉树的操作使用递归往往更容易理解和实现。
从定义也可以看出二叉树与一般树的区别主要是两点,一是每个结点的度最多为2;二是结点的子树有左右之分,不能随意调换,调换后又是一棵新的二叉树。
二、二叉树的形态
五种基本形态
从上面二叉树的递归定义可以看出,二叉树或为空,或为一个根结点加上两棵左右子树,因为两棵左右子树也是二叉树也可以为空,所以二叉树有5种基本形态:
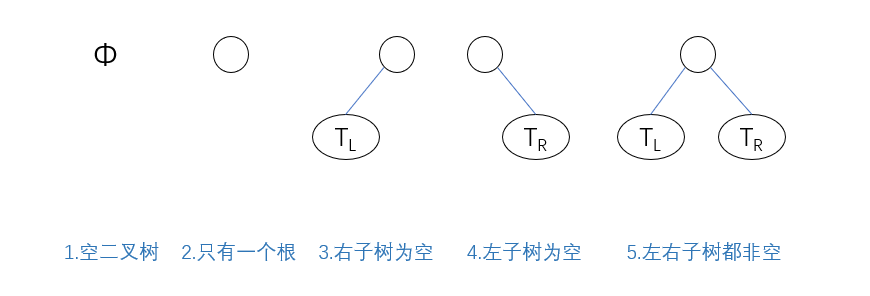
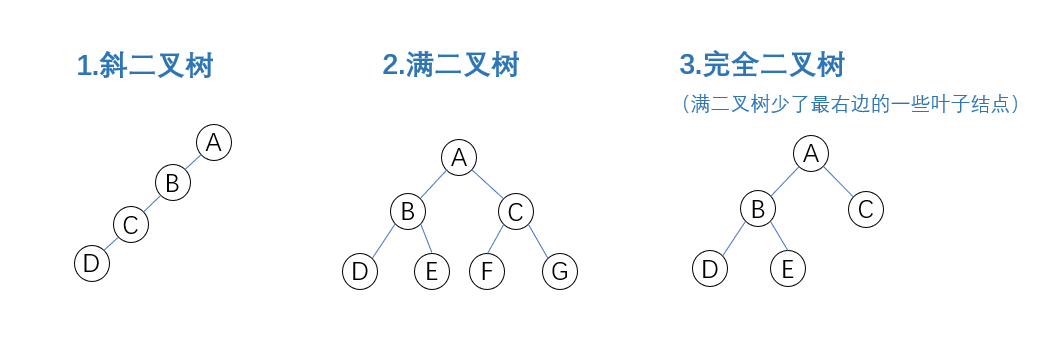
三种特殊形态
三、二叉树的性质
-
任意二叉树第 i i i 层最大结点数为 2 i − 1 。 ( i ≥ 1 ) 2^{i-1}。(i≥1) 2i−1。(i≥1)
归纳法证明。 -
深度为 k k k 的二叉树最大结点总数为 2 k − 1 。 ( k ≥ 1 ) 2^k-1。(k≥1) 2k−1。(k≥1)
证明: ∑ i = 1 k 2 i − 1 = 2 k − 1 \sum_{i=1}^k 2^{i-1} =2^k-1 ∑i=1k2i−1=2k−1 -
对于任意二叉树,用 n 0 , n 1 , n 2 n_0,n_1,n_2 n0,n1,n2分别表示叶子结点,度为1的结点,度为2的结点的个数,则有关系式 n 0 = n 2 + 1 n_0=n_2+1 n0=n2+1。
证明:总结点个数 n = n 0 + n 1 + n 2 n=n_0+n_1+n_2 n=n0+n1+n2;总结点中除根结点外,其余各结点都有一个分支进入,设 m m m为分支总数,则有 n = m + 1 n=m+1 n=m+1,又因为这些分支都是由度为1或2的结点射出的,所以有 m = n 1 + 2 n 2 m=n_1+2n_2 m=n1+2n2,于是有 n = n 1 + 2 n 2 + 1 n=n_1+2n_2+1 n=n1+2n2+1;最后将关于 n n n的两个关系式化简得证。 -
n n n个结点完全二叉树深度为 ⌊ l o g 2 n ⌋ + 1 \lfloor log_2 n \rfloor+1 ⌊log2n⌋+1。
证明:设深度 k k k,则有 2 k − 1 ≤ n < 2 k ⇒ k − 1 ≤ l o g 2 n < k ⇒ k = ⌊ l o g 2 n ⌋ + 1 2^{k-1}≤n<2^k⇒k-1≤log_ 2n<k⇒k=\lfloor log_2 n \rfloor+1 2k−1≤n<2k⇒k−1≤log2n<k⇒k=⌊log2n⌋+1 -
性质5其实描述的是完全二叉树中父子结点间的逻辑对应关系。 假如对一棵完全二叉树的所有结点按层序遍历的顺序从1开始编号,对于编号后的结点 i i i:
(1) i = 1 i=1 i=1时表示 i i i是根结点;
(2) i > 1 i>1 i>1时:① i i i的父结点为 ⌊ i 2 ⌋ \lfloor \frac i2 \rfloor ⌊2i⌋。②若 2 i > n 2i>n 2i>n,结点 i i i无左孩子,且为叶子结点。③若 2 i + 1 > n 2i+1>n 2i+1>n,结点 i i i无右孩子,可能为叶子结点。
当然如果完全二叉树的根结点从0开始编号,那么上述关系就要相应修改一下。
四、二叉树的存储
存的目的是为了取,而取的关键在于如何通过父结点拿到它的左右子结点,不同存储方式围绕的核心也就是这。
顺序存储
使用一组地址连续的存储单元存储,例如数组。为了在存储结构中能得到父子结点之间的映射关系,二叉树中的结点必须按层次遍历的顺序存放。具体是:
- 对于完全二叉树,只需要自根结点起从上往下、从左往右依次存储。
- 对于非完全二叉树,首先将它变换为完全二叉树,空缺位置用某个特殊字符代替(比如#),然后仍按完全二叉树的存储方式存储。
假设将一棵二叉树按此方式存储到数组后,左子结点下标=2倍的父结点下标+1,右子节点下标=2倍的父结点下标+2(这里父子结点间的关系是基于根结点从0开始计算的)。若数组某个位置处值为#,代表此处对应的结点为空。
可以看出顺序存储非常适合存储接近完全二叉树类型的二叉树,对于一般二叉树有很大的空间浪费,所以对于一般二叉树,一般用下面这种链式存储。
链式存储
对每个结点,除数据域外再多增加左右两个指针域,分别指向该结点的左孩子和右孩子结点,再用一个头指针指向根结点。对应的存储结构:
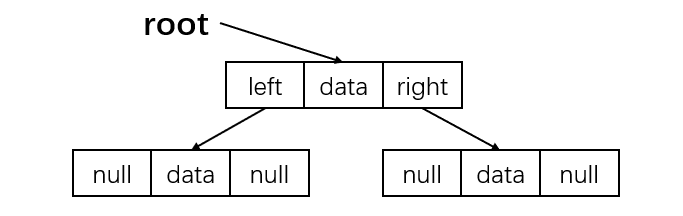
五、二叉树的创建与遍历(递归)
二叉树由三个基本单元组成:根结点,左子树,右子树,因此存在6种遍历顺序,若规定先左后右,则只有以下3种:
1.先序遍历
若二叉树为空,则空操作;否则:
(1)访问根结点
(2)先序遍历左子树
(3)先序遍历右子树
2.中序遍历
若二叉树为空,则空操作;否则:
(1)中序遍历左子树
(2)访问根结点
(3)中序遍历右子树
3.后序遍历
若二叉树为空,则空操作;否则:
(1)后序遍历左子树
(2)后序遍历右子树
(3)访问根结点
从上可以看出先中后其实是相对根结点来说。
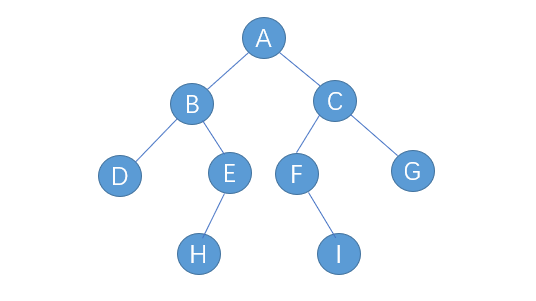
对于下面这棵二叉树,其遍历顺序:
先序:ABDEHCFIG
中序:DBHEAFICG
后序:DHEBIFGCA
下面是将以下二叉树的顺序存储[A,B,C,D,E,F,G,#,#,H,#,#,I]转换为链式存储的代码,结点不存在用字符#表示,并分别遍历。
java代码
class TreeNode {
char data;
TreeNode lchild; // 左子结点指针
TreeNode rchild; // 右子结点指针
public TreeNode(char data) {
this.data = data;
}
}
public class BinaryTree {
// 将二叉树的顺序存储变为链式存储
public static TreeNode buildTree(char[] arr, int index) {
TreeNode root = null;
if (index < arr.length) {
if (arr[index] == '#') {
return null;
}
root = new TreeNode(arr[index]);
root.lchild = buildTree(arr, 2 * index + 1);
root.rchild = buildTree(arr, 2 * index + 2);
}
return root;
}
// 先序遍历
public static void preOrderTraverse(TreeNode T) {
if (T != null) {
System.out.print(T.data);
preOrderTraverse(T.lchild);
preOrderTraverse(T.rchild);
}
}
// 中序遍历
public static void inOrderTraverse(TreeNode T) {
if (T != null) {
inOrderTraverse(T.lchild);
System.out.print(T.data);
inOrderTraverse(T.rchild);
}
}
// 后序遍历
public static void postOrderTraverse(TreeNode T) {
if (T != null) {
postOrderTraverse(T.lchild);
postOrderTraverse(T.rchild);
System.out.print(T.data);
}
}
public static void main(String[] args) {
char[] arr = {
'A', 'B', 'C', 'D', 'E', 'F', 'G', '#', '#', 'H', '#', '#', 'I' };
TreeNode T = buildTree(arr, 0);
System.out.print("先序遍历-->");
preOrderTraverse(T);
System.out.println();
System.out.print("中序遍历-->");
inOrderTraverse(T);
System.out.println();
System.out.print("后序遍历-->");
postOrderTraverse(T);
System.out.println();
}
}
仔细观察先序、中序、后序的结点访问顺序可以发现:
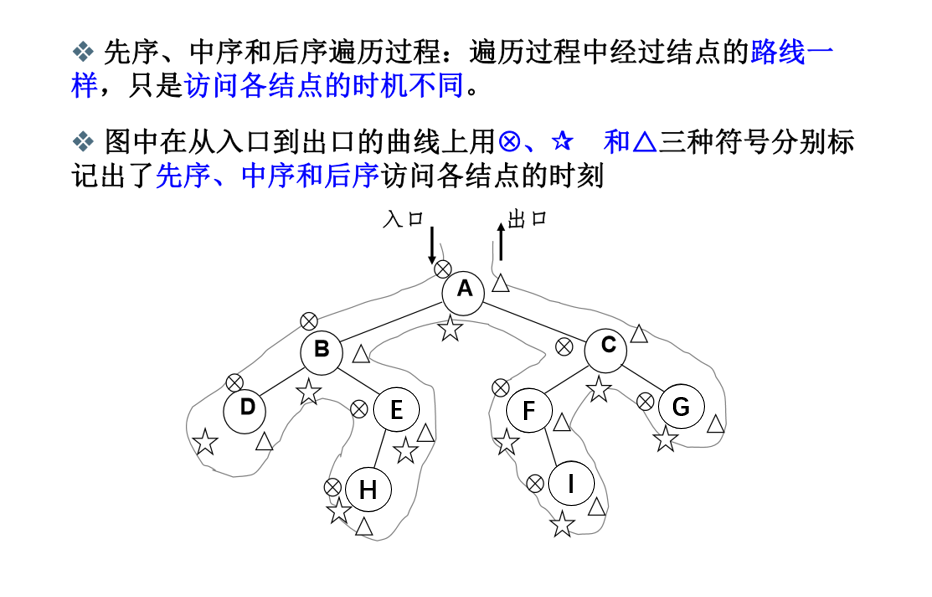
六、二叉树的非递归遍历
以上二叉树的创建及遍历都是通过递归实现,由三(三)、利用栈将递归转换为非递归可以将二叉树的递归遍历转换为非递归。
非递归的先序遍历
public static void preOrderWithoutRecursion(TreeNode T) {
Stack<TreeNode> s = new Stack<>();
while (T != null || !s.empty()) {
if (T != null) {
System.out.print(T.data);
s.push(T);
T = T.lchild;
} else {
T = s.pop();
T = T.rchild;
}
}
}
非递归的中序遍历
public static void inOrderWithoutRecursion(TreeNode T) {
Stack<TreeNode> s = new Stack<>();
while (T != null || !s.empty()) {
if (T != null) {
s.push(T);
T = T.lchild;
} else {
T = s.pop();
System.out.print(T.data);
T = T.rchild;
}
}
}
非递归的后序遍历
/*
* 后序遍历要比先序中序遍历复杂一些,原因是需要判断上次访问的结点是位于左子树还是位于右子树。
* 若位于左子树,需要跳过根结点并进入右子树,回头再访问根结点。
* 若位于右子树,则直接访问根结点。
*/
public static void postOrderWithoutRecursion(TreeNode T) {
Stack<TreeNode> s = new Stack<>();
// 保存上次访问的结点
TreeNode lastVisit = null;
// 首先一路压栈进入到左子树最左下端
while (T != null) {
s.push(T);
T = T.lchild;
}
while (!s.empty()) {
T = s.pop();
// 一个根结点被访问的前提是:无右子树或右子树已被访问过
if (T.rchild == null || T.rchild == lastVisit) {
System.out.print(T.data);
// 修改最近访问的结点
lastVisit = T;
} else {
// 否则根结点再次入栈并直接进入到右子树
s.push(T);
T = T.rchild;
// 并一路压栈进入到右子树的最左下端
while (T != null) {
s.push(T);
T = T.lchild;
}
}
}
}
总结这种改写其实就是代码跟着思维走,模拟递归过程,用的仍然是递归的思想。
这里推荐一篇博客,作者将二叉树的非递归遍历讲解的透彻易懂,博客地址
七、二叉树的层序遍历(递归与非递归)
层次遍历是指从二叉树的根结点开始,按从上到下,从左到右的顺序遍历,也就是按从左往右的顺序先遍历第一层即根结点,再遍历第二层,…,直至最后一层。
还是上面的那棵二叉树,层序遍历顺序为:ABCDEFGHI。
递归
/*
* 递归相比非递归优点就是思路清晰,代码易读,缺点是系统开销大。
* 但是层序遍历的递归实现反而使算法更复杂。
* 下面代码只提供层序遍历的一种递归思路,并不能算是真正意义上的递归。
*/
public static void levelOrderWithRecursion(TreeNode T) {
if (T == null) {
return;
}
// 获取树的深度
int depth = depth(T);
// 对每层循环遍历
for (int i = 1; i <= depth; i++) {
levelOrder(T, i);
}
}
private static void levelOrder(TreeNode T, int level) {
// if语句中去掉条件level<1不影响遍历结果,但对指定层遍历完成后仍然会继续递归调用,直到最下面结点的左右子结点为空结束递归
if (T == null || level < 1) {
return;
}
if (level == 1) {
System.out.print(T.data);
}
levelOrder(T.lchild, level - 1);
levelOrder(T.rchild, level - 1);
}
private static int depth(TreeNode T) {
if (T == null) {
return 0;
}
int l = depth(T.lchild);
int r = depth(T.rchild);
if (l > r) {
return l + 1;
} else {
return r + 1;
}
}
非递归
/*
* 非递归遍历需要借助队列完成。
* 因为对同一层的结点A和结点B,如果A在B的左边先被遍历,那么下一层中A的孩子也一定在B的孩子左边先被遍历。
*/
public static void levelOrderTraverse(TreeNode T) {
if (T == null)
return;
Queue<TreeNode> q = new LinkedList<>();
TreeNode node = null;
// 首先根结点入队
q.add(T);
while (!q.isEmpty()) {
// 队头出队
node = q.remove();
System.out.print(node.data);
// 左右子结点入队
if (node.lchild != null) {
q.add(node.lchild);
}
if (node.rchild != null) {
q.add(node.rchild);
}
}
}
八、四种遍历方式的时间和空间复杂度
四种遍历方式中,无论是递归还是非递归,二叉树的每个结点都只被访问一次,所以对于 n n n个结点的二叉树,时间复杂度均为 O ( n ) Ο(n) O(n)。
除层序遍历外的其它三种遍历方式,所需辅助空间为遍历过程中栈的最大容量,也就是二叉树的深度,所以空间复杂度与二叉树的形状有关。对于 n n n个结点的二叉树,最好情况下是完全二叉树,空间复杂度 O ( l o g 2 n ) Ο(log_2 n) O(log2n);最坏情况下对应斜二叉树,空间复杂度 O ( n ) Ο(n) O(n)。层序遍历所需辅助空间为遍历过程中队列的最大长度,也就是二叉树的最大宽度 k k k,所以空间复杂度 O ( k ) Ο(k) O(k)。
九、根据遍历序列确定二叉树
(一)、根据先序、中序、后序遍历序列重建二叉树
从上面二叉树的遍历可以看出:如果二叉树中各结点值不同,那么先序、中序、以及后序遍历所得到的序列也是唯一。反过来,如果知道任意两种遍历序列,能否唯一确定这棵二叉树?
首先明确:只有先序中序,后序中序这两种组合可以唯一确定,先序后序不能。
如果知道的是先序中序,那么根据先序遍历先访问根结点的特点在中序序列中找到这个结点,该结点将中序序列分成两部分,左边是这个根结点的左子树中序序列,右边是这个根结点的右子树中序序列。根据这个序列,在先序序列中找到对应的左子序列和右子序列,根据先序遍历先访问根的特点又可以确定两个子序列的根结点,并根据这两个根结点可以将上次划分的两个中序子序列继续划分,如此下去,直到取尽先序序列中的结点时,便可得到对应的二叉树。
后序中序同理,区别是先序序列中第一个结点是根结点,而后序序列中最后一个结点是根结点。
先序和后序不能确定的原因在于不能确定根结点的左右子树。 比如先序序列AB,后序序列BA,根结点是A可以确定,但B是A的左子结点还是右子结点就确定不了了。
具体代码实现参考牛客网上《剑指Offer》中的一道题。查看
题目描述:输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
解题代码:
/*
*下面代码来源原题下面的解答,思路很强!
*用的是递归思想,每次将左右两棵子树当成新的子树进行处理,中序的左右子树开始结束索引很好找。
*前序的左右子树的开始结束索引通过根结点与中序中左右子树的大小来计算。
*然后递归求解,直到startPre>endPre||startIn>endIn说明子树整理完到。方法每次返回左子树和右子树的根结点。
*事实上startPre>endPre||startIn>endIn两条件任选其一即可。为什么?仔细想想!
*/
public class ReBuildBinaryTree {
private static class TreeNode {
int data;
TreeNode lchild;
TreeNode rchild;
public TreeNode(int data) {
super();
this.data = data;
}
}
public static TreeNode reBuildBinaryTree(int[] pre, int[] in) {
TreeNode root = reBuildBinaryTree(pre, 0, pre.length - 1, in, 0, in.length - 1);
return root;
}
private static TreeNode reBuildBinaryTree(int[] pre, int startPre, int endPre, int[] in, int startIn, int endIn) {
// 两条件也可任选其一
if (startPre > endPre || startIn > endIn)
return null;
TreeNode root = new TreeNode(pre[startPre]);
for (int i = startIn; i <= endIn; i++) {
if (in[i] == pre[startPre]) {
// startPre+i-startIn=startPre+(i-startIn),表示的意义是根结点索引+根结点的左子树结点总数,对应前序的左子树的结束索引。
root.lchild = reBuildBinaryTree(pre, startPre + 1, startPre + i - startIn, in, startIn, i - 1);
// i-startIn+startPre+1即在上面的基础上加1,前序左子树的结束索引+1=前序右子树的开始索引。
root.rchild = reBuildBinaryTree(pre, i - startIn + startPre + 1, endPre, in, i + 1, endIn);
break;
}
}
return root;
}
}
(二)、根据层序遍历序列重建二叉树(2023.11.5补)
刷题遇到(https://leetcode.cn/problems/binary-tree-right-side-view/description/),简单记录下,具体看代码,这里用python实现:
# 节点定义
class TreeNode:
def __init__(self, val=None, left=None, right=None):
self.val = val
self.left = left
self.right = right
# 层序遍历 -> 二叉树
def create_tree(arr: list, idx=0) -> TreeNode:
# 这里如果不限制 arr[idx] is not None,则可构建一棵完全二叉树,对其层序遍历时可将输入参数arr原样输出而不忽略掉其中的None值
if len(arr) - 1 >= idx and arr[idx] is not None:
node = TreeNode(arr[idx])
# 左右子节点位置与父节点位置下标关系分别为 2n+1 2n+2
node.left = create_tree(arr, 2 * idx + 1)
node.right = create_tree(arr, 2 * idx + 2)
return node
# 二叉树 -> 层序遍历
def level_search(root):
if root is None:
return
res = []
from collections import deque
q = deque(maxlen=100)
q.append(root)
while len(q) > 0:
node = q.popleft()
res.append(node.val)
if node.left is not None:
q.append(node.left)
if node.right is not None:
q.append(node.right)
return res
if __name__ == '__main__':
# 这里要求输入序列是按完全二叉树层序遍历顺序得到的,空缺位置用None代替
arr = [1, 2, 3, None, 5, None, 4]
root = create_tree(arr)
res = level_search(root)
print(res) # [1, 2, 3, 5, 4]
十、二叉树遍历算法的应用
在上面二叉树递归遍历的基础上,将具体的访问结点操作换成其它的某些操作就可以实现另外的一些功能。
1.按先序遍历的顺序建立二叉树
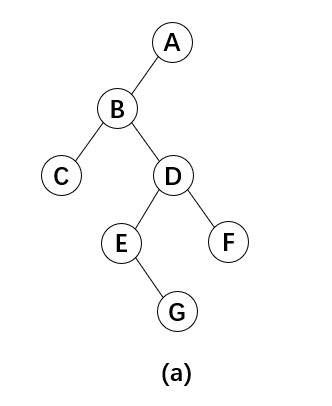
比如图(a)中的这棵二叉树,左子树或右子树不存在用字符#表示,对应的先序序列[ABC##DE#G##F###],那么根据这个先序序列,也可以还原这棵二叉树。
要注意的是下面代码看似没有递归出口,其实不是,当输入的先序序列已经可以唯一确定二叉树的时候程序也会随之停止调用并结束。(写这块的时候花了一个晚上,原因是方法里的参数开始传的是先序数组和数组下标,然后递归的时候数组下标+1,忽视了逐层往里递归的时候虽然数组下标也逐层+1正确但最内部递归结束返回次内部往另一个方向递归的时候传入的数组下标还是该层数组下标没有+1时的值)
public static TreeNode build(Scanner sc) {
char ch = (sc.nextLine().charAt(0));
if (ch == '#') {
return null;
}
TreeNode root = null;
root = new TreeNode(ch);
root.lchild = build(sc);
root.rchild = build(sc);
return root;
}
2.按先序遍历的顺序复制二叉树
public static TreeNode copy(TreeNode T) {
if (T == null) {
return null;
}
TreeNode newT = new TreeNode(T.data);
newT.lchild = copy(T.lchild);
newT.rchild = copy(T.rchild);
return newT;
}
3.按后序遍历的顺序计算二叉树深度
二叉树深度为左右子树深度中的最大值+1,代码在二叉树递归的层序遍历中含有。
4.按先序遍历的顺序统计二叉树中结点个数
(1)统计所有结点个数
①当树为空时,结点个数为0;
②否则为根结点+根的左子树中结点个数+根的右子树中结点的个数。
public static int count(TreeNode T) {
if (T == null)
return 0;
return count(T.lchild) + count(T.rchild) + 1;
}
(2)统计所有度为0也就是叶子结点的个数
①当树为空时,叶子结点个数为0;
②当某个结点的左右子树均为空时,说明该结点为叶子结点,返回1。
③否则表明该结点有左子树,或者有右子树,或者既有左子树又有右子树时,说明该结点不是叶子结点,因此叶结点个数等于左子树中叶子结点个数+右子树中叶子结点的个数。
public static int count(TreeNode T) {
if (T == null)
return 0;
if (T.lchild == null && T.rchild == null)
return 1;
return count(T.lchild) + count(T.rchild);
}
(3)统计所有度为1的结点个数
①当树为空时,度为1的结点个数为0;
②当某个结点只有左子树或者只有右子树时,说明该结点是度为1的结点,返回1;
③否则表明该结点左右子树都存在,因此度为1的结点个数=左子树中度为1的结点个数+右子树中度为1的结点个数。
public static int count(TreeNode T) {
if (T == null)
return 0;
// 条件中可以不用括号,短路与“&&”的优先级高于短路或“||”。
if ((T.lchild == null && T.rchild != null) || (T.lchild != null && T.rchild == null))
return 1;
return count(T.lchild) + count(T.rchild);
}
(4)统计所有度为2也就是满结点的个数
①当树为空时,度为2的结点个数为0;
②当某个结点左子树和右子树都存在时,说明该结点是度为2的结点,返回1;
③否则表明该结点存在且不是满结点,因此满结点个数=该结点左子树中的满结点个数+该结点右子树中的满结点个数(必有一子树不存在,但会返回0不影响结果)。
public static int count(TreeNode T) {
if (T == null)
return 0;
if (T.lchild != null && T.rchild != null)
return count(T.lchild) + count(T.rchild) + 1;
return count(T.lchild) + count(T.rchild);
}
智能推荐
基于Kepler.gl 和 Google Earth Engine 卫星数据创建拉伸多边形地图-程序员宅基地
文章浏览阅读965次,点赞18次,收藏21次。现在我们有了 2021 年和 2023 年的 NDVI 数据帧,我们需要从 2021 年的值中减去 2023 年的值以捕获 NDVI 的差异。该数据集包括像素级别的植被值,我们将编写一个自定义函数来根据红色和绿色波段的表面反射率计算 NDVI。在我的上一篇文章中,我演示了如何将单个多边形分割/镶嵌为一组大小均匀的六边形。现在我们有了植被损失数据,让我们使用 Kepler.gl 可视化每个六边形的植被损失。将地图保存为 HTML 文件,在浏览器中打开 HTML 以获得更好的视图。现在我们将调用该函数并使用、
Echarts绘制任意数据的正态分布图_echarts正态分布图-程序员宅基地
文章浏览阅读3.3k次,点赞6次,收藏5次。正态分布,又称高斯分布或钟形曲线,是统计学中最为重要和常用的分布之一。_echarts正态分布图
Android中发送短信等普通方法_android bundle.get("pdus");-程序员宅基地
文章浏览阅读217次。首先要在Mainfest.xml中加入所需要的权限:[html] view plain copyprint?uses-permission android:name="android.permission.SEND_SMS"/> uses-permission android:name="android.permission.READ_SMS"/> _android bundle.get("pdus");
2021-07-26 WSL2 的安装和联网_wsl2 联网-程序员宅基地
文章浏览阅读2.6k次。0、说明最近在学习 Data Assimilation Research Testbed (DART) 相关内容,其软件是在 Unix/Linux 操作系统下编译和运行的 ,由于我的电脑是 Windows 10 的,DART 推荐可以使用 Windows Subsystem For Linux (WSL) 来创建一个 Windows 下的 Linux 子系统。以下的内容主要介绍如何安装 WSL2,以及 WSL2 的联网。1、如何在 Windows 10 下安装WSL具体的安装流程可以在 microso_wsl2 联网
DATABASE_LINK 数据库连接_添加 database link重复的数据库链接命-程序员宅基地
文章浏览阅读1k次。DB_LINK 介绍在本机数据库orcl上创建了一个prod_link的publicdblink(使用远程主机的scott用户连接),则用sqlplus连接到本机数据库,执行select * from scott.emp@prod_link即可以将远程数据库上的scott用户下的emp表中的数据获取到。也可以在本地建一个同义词来指向scott.emp@prod_link,这样取值就方便多了..._添加 database link重复的数据库链接命
云-腾讯云-实时音视频:实时音视频(TRTC)-程序员宅基地
文章浏览阅读3.1k次。ylbtech-云-腾讯云-实时音视频:实时音视频(TRTC)支持跨终端、全平台之间互通,从零开始快速搭建实时音视频通信平台1.返回顶部 1、腾讯实时音视频(Tencent Real-Time Communication,TRTC)拥有QQ十几年来在音视频技术上的积累,致力于帮助企业快速搭建低成本、高品质音视频通讯能力的完整解决方案。..._腾讯实时音视频 分享链接
随便推点
用c语言写个日历表_农历库c语言-程序员宅基地
文章浏览阅读534次,点赞10次,收藏8次。编写一个完整的日历表需要处理许多细节,包括公历和农历之间的转换、节气、闰年等。运行程序后,会输出指定年份的日历表。注意,这个程序只是一个简单的示例,还有很多可以改进和扩展的地方,例如添加节气、节日等。_农历库c语言
FL Studio21.1.1.3750中文破解百度网盘下载地址含Crack补丁_fl studio 21 注册机-程序员宅基地
文章浏览阅读1w次,点赞28次,收藏27次。FL Studio21.1.1.3750中文破解版是最优秀、最繁荣的数字音频工作站 (DAW) 之一,日新月异。它是一款录音机和编辑器,可让您不惜一切代价制作精美的音乐作品并保存精彩的活动画廊。为方便用户,FL Studio 21提供三种不同的版本——Fruity 版、Producer 版和签名版。所有这些版本都是独一无二的,同样具有竞争力。用户可以根据自己的需要选择其中任何一种。FL Studio21.1.1.3750中文版可以说是一站式综合音乐制作单位,可以让您录制、作曲、混音和编辑音乐。_fl studio 21 注册机
冯.诺伊曼体系结构的计算机工作原理是,冯 诺依曼型计算机的工作原理是什么...-程序员宅基地
文章浏览阅读1.3k次。冯诺依曼计算机工作原理冯 诺依曼计算机工作原理的核心是 和 程序控制世界上不同型号的计算机,就其工作原理而言,一般都是认为冯 诺依曼提出了什么原理冯 诺依曼原理中,计算机硬件系统由那五大部分组成的 急急急急急急急急急急急急急急急急急急急急急急冯诺依曼结构计算机工作原理的核心冯诺依曼结构和现代计算机结构模型 转载重学计算机组成原理 一 冯 诺依曼体系结构从冯.诺依曼的存储程序工作原理及计算机的组成来..._简述冯诺依曼计算机结构及工作原理
四国军棋引擎开发(2)简单的事件驱动模型下棋-程序员宅基地
文章浏览阅读559次。这次在随机乱下的基础上加上了一些简单的处理,如进营、炸棋、吃子等功能,在和敌方棋子产生碰撞之后会获取敌方棋子大小的一些信息,目前采用的是事件驱动模型,当下完一步棋界面返回结果后会判断是否触发了相关事件,有事件发生则处理相关事件,没有事件发生则仍然是随机下棋。1.事件驱动模型首先定义一个各种事件的枚举变量,目前的事件有工兵吃子,摸暗棋,进营,明确吃子,炸棋。定义如下:enum MoveE..._军棋引擎
STL与泛型编程-第一周笔记-Geekband-程序员宅基地
文章浏览阅读85次。1, 模板观念与函数模板简单模板: template< typename T > T Function( T a, T b) {… }类模板: template struct Object{……….}; 函数模板 template< class T> inline T Function( T a, T b){……} 不可以使用不同型别的..._geekband 讲义
vb.net正则表达式html,VB.Net常用的正则表达式(实例)-程序员宅基地
文章浏览阅读158次。"^\d+$" //非负整数(正整数 + 0)"^[0-9]*[1-9][0-9]*$" //正整数"^((-\d+)|(0+))$" //非正整数(负整数 + 0)"^-[0-9]*[1-9][0-9]*$" //负整数"^-?\d+$" //整数"^\d+(\.\d+)?$" //非负浮点数(正浮点数 + 0)"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0..._vb.net 正则表达式 取html中的herf