2022春季《人工智能》EOJ代码个人汇总(A.八数码问题 到 J.迷宫寻找)_人工智能eoj-程序员宅基地
温馨提示:不要光顾着抄代码,想一想原理怎么来的
文章目录
A.八数码问题

#include<iostream>
#include<bits/stdc++.h>
using namespace std;
char direction[] = {
'u', 'd', 'l', 'r'};
int flag = 0;
string ROAD = "unsolvable";
struct A
{
string road = "";
int mark = 0;
};
int bfs(string& aim, queue<string>& q, map<string,A>& visit)
{
while(!q.empty())
{
string last_now = q.front();
if(aim == last_now)//满足aim的地图了
{
ROAD = visit[last_now].road;
return 1;
//表明已经完成探路
}
// cout << last_now << endl;
// cout << visit[last_now].road << endl << endl;
q.pop();
int x_location = last_now.find('x');
int x_row = x_location / 3;
int x_col = x_location % 3;
string last_road = visit[last_now].road;
for(int i = 0; i < 4; i++)
{
//每次往不同的方向都要重新初始化
string now = last_now;//初始化现在的地图
string road = last_road;//初始化现在的路径
//cout << x_row << " " << x_col << endl;
if(direction[i] == 'u')
{
if(x_row == 0)
continue;
else
{
int temp = now.find('x');
now[temp] = now[temp - 3];
now[temp - 3] = 'x';
road += 'u';
}
}
else if(direction[i] == 'd')
{
if(x_row == 2)
continue;
else
{
int temp = now.find('x');
now[temp] = now[temp + 3];
now[temp + 3] = 'x';
road += 'd';
}
}
else if(direction[i] == 'l')
{
if(x_col == 0)
continue;
else
{
int temp = now.find('x');
now[temp] = now[temp - 1];
now[temp - 1] = 'x';
road += 'l';
}
}
else if(direction[i] == 'r')
{
if(x_col == 2)
continue;
else
{
int temp = now.find('x');
now[temp] = now[temp + 1];
now[temp + 1] = 'x';
road +='r';
}
}
if(visit[now].mark == 1)
{
continue;
}
else
{
visit[now].road = road;
visit[now].mark = 1;
q.push(now);
}
}
}
return 0;
}
int main()
{
string aim = "12345678x";
string now;
cin >> now;
string road = "";
queue<string>q;
map<string, A> visit;//用于记录是否访问过这个状态
//第一个string放记录的地图 第二个放对应的路径road
visit[now].road = road;
visit[now].mark = 1;
q.push(now);
bfs(aim, q, visit);
cout << ROAD << endl;
return 0;
}
B.路径导航

double h(int point)//离终点的预计最小状态
{
return distance(t, point);
}
// double g(int point)//离起点的确切距离
// {
// return gi[point];
// }
#include<climits>
priority_queue<pair<double,int>, vector<pair<double, int>>, greater_equal<pair<double, int>> > pq;
double A_star(int s,int t)
{
//初始化部分
for(int i = 0; i < n; i++)
gi[i] = INT_MAX;
gi[s] = 0;
f[s] = gi[s] + h(s);
pq.push(make_pair(f[s], s));
while(!pq.empty())
{
int point = pq.top().second;
pq.pop();
if(point == t)//找到对应的点
return f[t];
for(int i = 0; i < n; i++)//遍历相邻点
{
if(edge[point][i])
{
double g_new = gi[point] + distance(point, i);
if(g_new < gi[i])
{
gi[i] = g_new;
f[i] = gi[i] + h(i);
pos[i] = point; //i的前一个点为point
pq.push(make_pair(f[i], i));
}
}
}
}
return f[t];
}
C.TSP问题

#include<ctime>
#include<algorithm>
using namespace std;
int times;
int k;
vector<int>last;
void init()
{
srand(time(NULL));
t = 11.2;
times = 0;
k = 110;
}
bool termi()
{
return t < 1.5;
}
vector<int> N(const vector<int> &p)
{
vector<int> ret(p);
int x1 = rand()%(n-1) + 1;
int x2 = rand()%(n-1) + 1;
if(x1 > x2) swap(x1,x2);
while(x1 < x2)
{
swap(ret[x1], ret[x2]);
x1++;x2--;
}
return ret;
}
double drop(double t)
{
//last = p_best;
if(times < k*n)
{
times++;
return t;
}
times = 0;
return 0.92*t;
}
double calc_p()
{
return pow(exp(1.0), (-f(p_new)+f(p_current))/t);
}
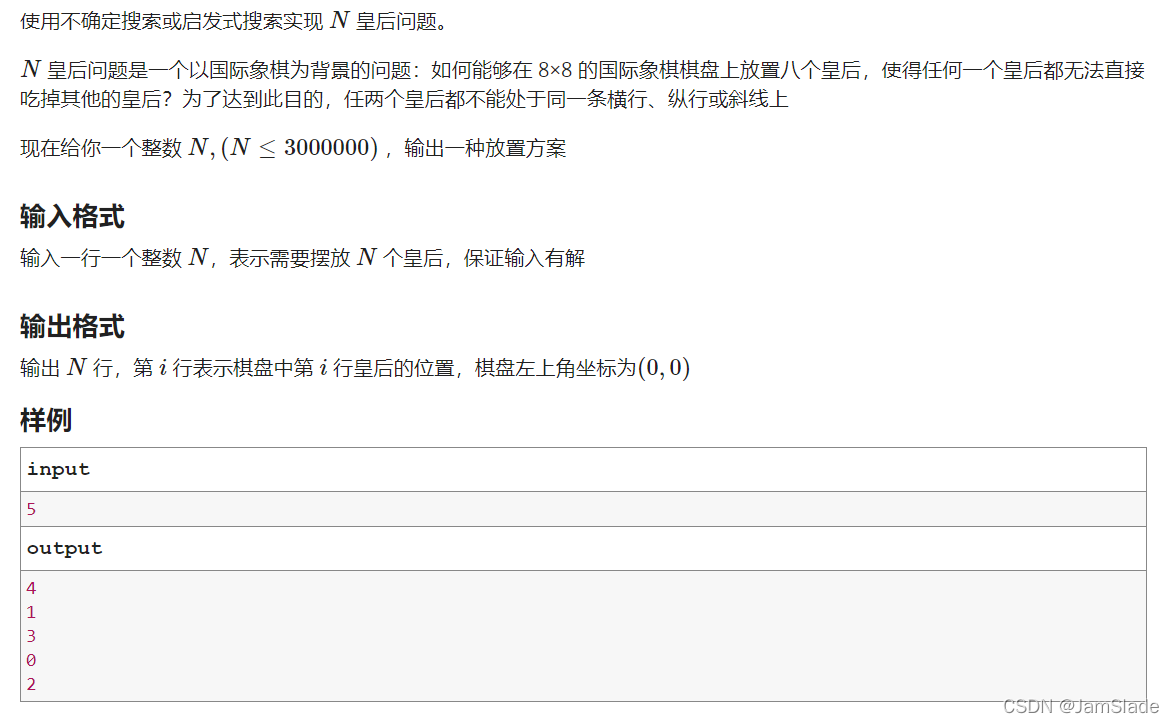
D. 百万皇后
#include<bits/stdc++.h>
using namespace std;
int N;
int dissa = 0;
int* y;
int* dia1;
int* dia2;//用于记录每一次交换y状态(棋盘)变化时候对角线的状态
int* dia3;
int* dia4;//用于记录每次固定下前n列时候的对角线状态
void init()
{
//srand(time(NULL));
for(int i = 0; i < 2*N-1; i++)
{
dia1[i] = dia2[i] = dia3[i] = dia4[i] = 0;
}
}
//
int my_random(int s, int e)
{
double ratio = double(rand())/RAND_MAX;
if(e > s)
return s + (unsigned ll)((e-s) * ratio);
else
return e;
}
void swap(int a, int b, int flag)
{
dia1[y[a] + a]--;
dia1[y[b] + b]--;
dia2[y[a] - a + N-1]--;
dia2[y[b] - b + N-1]--;
if(flag == 0)
{
dia3[y[a] + a]--;
dia4[y[a] - a + N-1]--;
//用处是flag1之后如果不满足要求再flag=0换回来
}
int temp = y[a];
y[a] = y[b];
y[b] = temp;
dia1[y[a] + a]++;
dia1[y[b] + b]++;
dia2[y[a] - a + N-1]++;
dia2[y[b] - b + N-1]++;
if(flag == 1)
{
//目的是让y(棋盘)从0到N-1遍历一遍
//每次就可以固定好一个位置
dia3[y[a] + a]++;
dia4[y[a] - a + N-1]++;
}
}
//first没问题
void first_test()
{
init();
for(int i = 0; i < N; i++)
{
y[i] = i;
dia1[y[i] + i]++;
dia2[y[i] - i + (N-1) ]++;//这里要N-1
}
int j = 0;
for(int test_time = 0; j < N && test_time < N * 4; test_time++)
{
int k = my_random(j, N);
swap(j, k, 1);
if(dia3[y[j]+j] > 1 || dia4[y[j]-j + N-1] > 1)
swap(j, k, 0);//换了还冲突就还回去
else
j++;//针对j 直到j不冲突
}
for (int i = j; i < N; i++)
{
int k = my_random(i, N);
swap(i, k, 2);
}
dissa = N - j;
}
// int totalCollisions(int k) {
// return dia2[y[k] - k + N - 1] > 1 || dia1[y[k] + k] > 1;
// }
void final_test()
{
//对剩下不满足要求的棋盘进行交换
for(int i = N - dissa - 1; i < N; i++)
{
int times = 0;//这里需要固定一个迭代次数
//避免过少太偶然也不能太多浪费时间
int b ;
if(dia2[y[i] - i + N - 1] > 1 || dia1[y[i] + i] > 1)
{
do
{
int j = my_random(0 , N);
times++;
swap(i, j, 2);
int collision1 = (dia2[y[i] - i + N - 1] > 1) || (dia1[y[i] + i] > 1);
int collision2 = (dia2[y[j] - j + N - 1] > 1) || (dia1[y[j] + j] > 1);
b = collision1 || collision2;
if(b)
swap(i, j, 2);
//如果在一个点超过1w次没有成功则重新再来
if(times > 10000)
{
first_test();
i = N - dissa - 1;
break;
}
} while (b);
}
}
}
int main()
{
cin >> N;
if(N == 1)
{
cout << 0;
return 0;
}
else if(N == 2 || N == 3 || N < 1)
{
return 0;
}
y = new int[N];
dia1 = new int[2*N-1];
dia2 = new int[2*N-1];
dia3 = new int[2*N-1];
dia4 = new int[2*N-1];
srand(time(NULL));
//init();
first_test();//先初始化看看能否一次就可以满足要求
if(dissa > 0)
{
final_test();
}
for(int i = 0; i < N; i++)
cout << y[i] << endl;
}
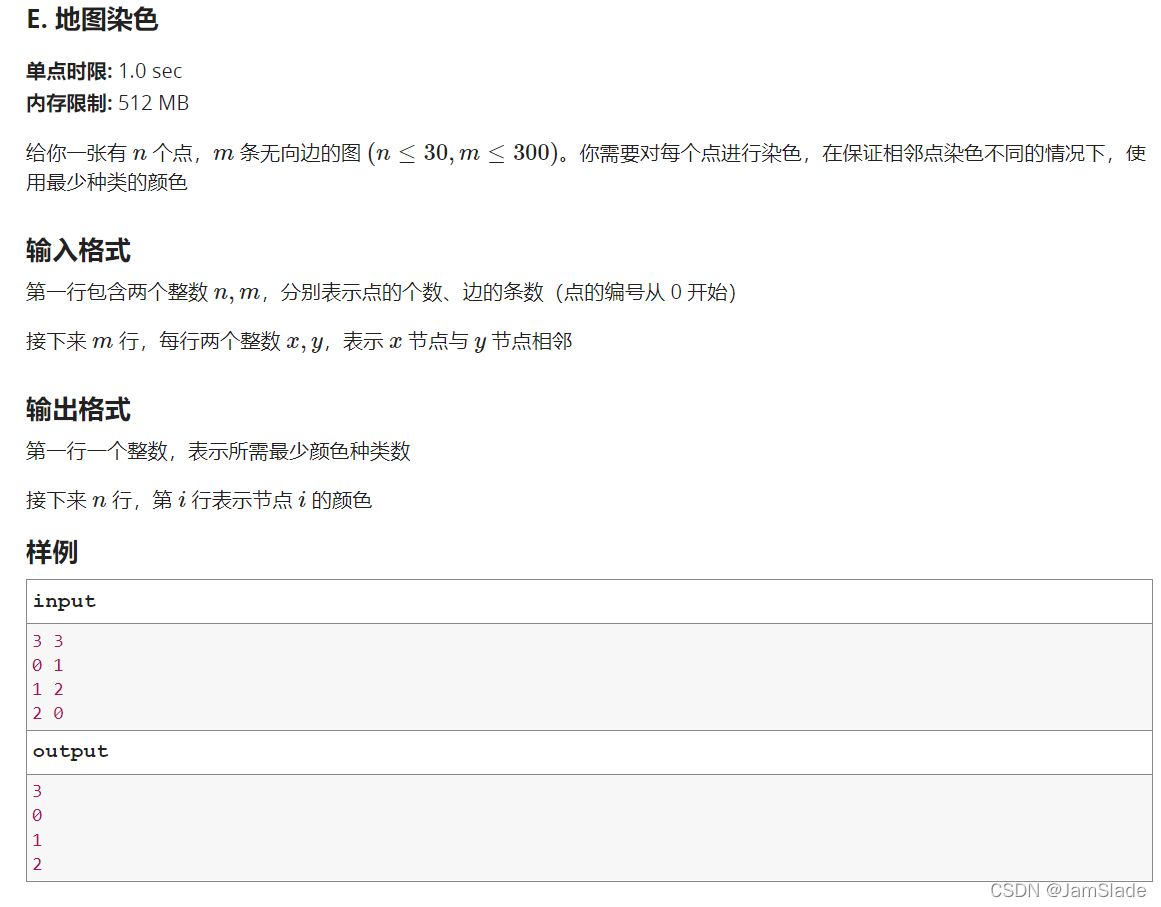
E. 地图染色
思路
这个数量级直接DFS就行,甚至不需要过多的剪枝
代码
#include<algorithm>
#include<iostream>
#include<vector>
#include<cstring>
using namespace std;
const int maxn = 1005;
int n,m;
int all = 0x3f3f3f3f;//最小颜色量
int map[maxn][maxn];//图
int color_to_point[maxn][maxn];//一个颜色
int color_num[maxn];
int color[maxn];//最后输出的out
int color_final[maxn];
void out()//最终输出
{
cout << all << endl;
for(int i = 0; i < n; i++)
cout << color_final[i] << endl;
}
void change()//改最小情况
{
for(int i = 0; i < n; i++)
color_final[i] = color[i];
}
void dfs(int seq, int total) // seq 表示第几个人, tot表示已经用了的颜色
{
if(total >= all)
return;
if(seq == n)//鉴定完前n个
{
if(all > total)//最优情况迭代
{
all = total;
change();
}
return;
}
for(int i = 0; i < total; i++)
{
//遍历所有使用过的颜色
int size = color_num[i];
int not_counter = 0;
for(int j = 0; j < size; j++)
{
int to_judge = color_to_point[i][j];
if(!map[to_judge][seq])//seq对应的点和这个是否相邻?
{
not_counter++;
}
}
if(not_counter == size)//所有点都不冲突
{
color[seq] = i;//保存节点颜色
color_to_point[i][color_num[i]++] = seq;//并储存好
dfs(seq + 1, total);
//回溯
color_num[i]--;
//color[seq] = -1;
}
}
color[seq] = total;//已经选了的颜色都有冲突
color_to_point[total][color_num[total]++] = seq;//选一个新的颜色
dfs(seq + 1, total + 1);
//回溯
color_num[total]--;
//color[seq] = -1;
}
int main()
{
memset(map, 0 ,sizeof(map));
memset(color_to_point,0, sizeof(color_to_point));
memset(color_num,0,sizeof(color_num));
memset(color, -1, sizeof(color));
memset(color_final, 0 ,sizeof(color_final));
cin >> n >> m;// amounts of points and edges
int x, y;
for(int i = 0; i < m; i++)
{
color[i]=-1;
cin >> x >> y;
map[x][y] = map[y][x] = 1;
}
dfs(0,0);
out();//
}
F.字符路径

思路1
DFS暴力穷举,然后发现平均每次开五个节点
复杂度可以到达 5 26 5^{26} 526次妥妥超时
所以找寻DP思路
思路2
利用DP思想,我们可以将每次走“1步“视为一个状态
例如road路径给的是”abcd"
那么每次我们要求的是a->d,那么我们先得求出a->c和a->b的状态
而这里的状态用一个二维数组保存
我们先假定a点有n个,b点m个,c点x个
具体的保存形式就是:
a->b 用 n × m n\times m n×m大小得数组进行储存,每个a到b之间的最短距离
那么再状态转移的时候,利用floyed或者dijkstra的图算法,来利用b->c和一开始村好的a->b来计算出来 n × x n\times x n×x个a到c的最短路径
最后求到a->d的所有可能,再遍历一遍得到最终的最短路径
代码
思路一代码
#include<iostream>
#include<map>
#include<vector>
#include<algorithm>
using namespace std;
struct point
{
int x;
int y;
int last_point_dis;
};
typedef vector<point> vp;
typedef map<char,vp> mcv;
const int maxn = 1024;
int ans = 0x3f3f3f3f;
int len;
char MAP[maxn][maxn];
int cal_Man(point a, point b)
{
return abs(a.x - b.x) + abs(a.y-b.y);
}
void test_map(const mcv& ma)
{
for(mcv::const_iterator it = ma.begin(); it != ma.end(); it++)
{
cout << it->first << ":\n";
for(vp::const_iterator itt = it->second.begin(); itt != it->second.end(); itt++)
{
cout << itt->x << " y: " << itt->y << " dis:" << itt->last_point_dis<< endl;
}
}
}
int cmp(point a, point b)
{
return a.last_point_dis < b.last_point_dis;
}
void dfs(mcv ma, string& str, point prev, int depth, int cost = 0)
//由于避免dfs后续影响前部分内容这里不用引用ma
{
if(cost > ans) return;
if(depth > len)
return;
if(depth == len)
{
if(cost < ans)
{
ans = cost;
}
return;
}
char seq = str[depth];
for(vp::iterator it = ma[seq].begin(); it != ma[seq].end(); it++)
{
it->last_point_dis = cal_Man(*it, prev);
}
sort(ma[seq].begin(), ma[seq].end(), cmp);//end就不用加size了
//test_map(ma);
for(vp::iterator it = ma[seq].begin(); it != ma[seq].end() && it != ma[seq].begin() + 3; it++)
{
dfs(ma, str, *it, depth + 1, cost + it->last_point_dis);
}
}
int main()
{
mcv ma;
int n, m ,k;
cin >> n >> m >> k;
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
{
cin >> MAP[i][j];
ma[MAP[i][j]].push_back({
j, i, 0});
}
//test_map(ma);
string road;
cin >> road;
len = road.length();
char zero = road[0];
for(vp::iterator it = ma[zero].begin(); it !=ma[zero].end(); it++)
{
dfs(ma, road, *it, 1);
}
cout << ans;
}
思路二
#include<iostream>
#include<cstring>
#include<unordered_map>
#include<vector>
using namespace std;
struct point
{
int y;
int x;
};
typedef vector<point> vp;
typedef unordered_map<char,vp> mcv;
const int inf = 0x3f3f3f3f;
const int maxn = 105;
int ans = inf;
int len;
char MAP[maxn][maxn];
int start_mid[maxn][maxn];
int mid_next[maxn][maxn];
string road;
int cal_Man(point a, point b)
{
return abs(a.x - b.x) + abs(a.y-b.y);
}
void test_map(const mcv& ma)
{
for(mcv::const_iterator it = ma.begin(); it != ma.end(); it++)
{
cout << it->first << ":\n";
for(vp::const_iterator itt = it->second.begin(); itt != it->second.end(); itt++)
{
cout << itt->x << " y: " << itt->y << endl;
}
}
}
void array_init(mcv& ma)
{
char zero = road[0];
int zero_num = ma[zero].size();
char one = road[1];
int one_num = ma[one].size();
for(int i = 0; i < zero_num; i++)
{
for(int j = 0; j < one_num; j++)
{
start_mid[i][j] = cal_Man(ma[zero][i], ma[one][j]);
//cout << start_mid[i][j] << " ";
}//cout << endl;
}
}
void dp(mcv& ma, int depth)
{
//test_map(ma);
char mid = road[depth - 1];
int mid_num = ma[mid].size();
char next = road[depth];
int next_num = ma[next].size();
for(int i = 0; i < mid_num; i++)
{
for(int j = 0; j < next_num; j++)
{
mid_next[i][j] = cal_Man(ma[mid][i], ma[next][j]);
}
}
char zero = road[0];
int zero_num = ma[zero].size();
int temp[maxn][maxn];
memset(temp, inf, sizeof(temp));
// cout << zero_num <<" " << mid_num << " "<<next_num << endl;
// cout << next << endl;
// cout << zero << mid << next << endl;
for(int k = 0; k < mid_num; k++)
for(int i = 0; i < zero_num; i++)
for(int j = 0; j < next_num; j++)
if(temp[i][j] > start_mid[i][k] + mid_next[k][j])
temp[i][j] = start_mid[i][k] + mid_next[k][j];
for(int i = 0; i < zero_num; i++)
for(int j = 0; j < next_num; j++)
start_mid[i][j] = temp[i][j];
// for(int i = 0; i < zero_num; i++){
// for(int j = 0; j < next_num; j++)
// {cout << temp[i][j] << "..";}
// cout << endl;}
//cout << "?" << endl;
}
int main()
{
int n, m ,k;
cin >> n >> m >> k;
mcv ma;
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
{
cin >> MAP[i][j];
ma[MAP[i][j]].push_back({
i,j});
}
// for(int i = 0; i < n; i++)
// for(int j = 0; j < m; j++)
// cout << MAP[i][j] << " ";
cin >> road;
len = road.length();
array_init(ma);//初始化start_mid;
for(int i = 2; i < len; i++)
{
dp(ma, i);
}
int zero_num = ma[road[0]].size();
int next_num = ma[road[len-1]].size();
for(int i = 0; i < zero_num; i++)
for(int j = 0; j < next_num; j++)
//cout << start_mid[i][j] << " ";
if(ans > start_mid[i][j])
ans = start_mid[i][j];
cout << ans;
}
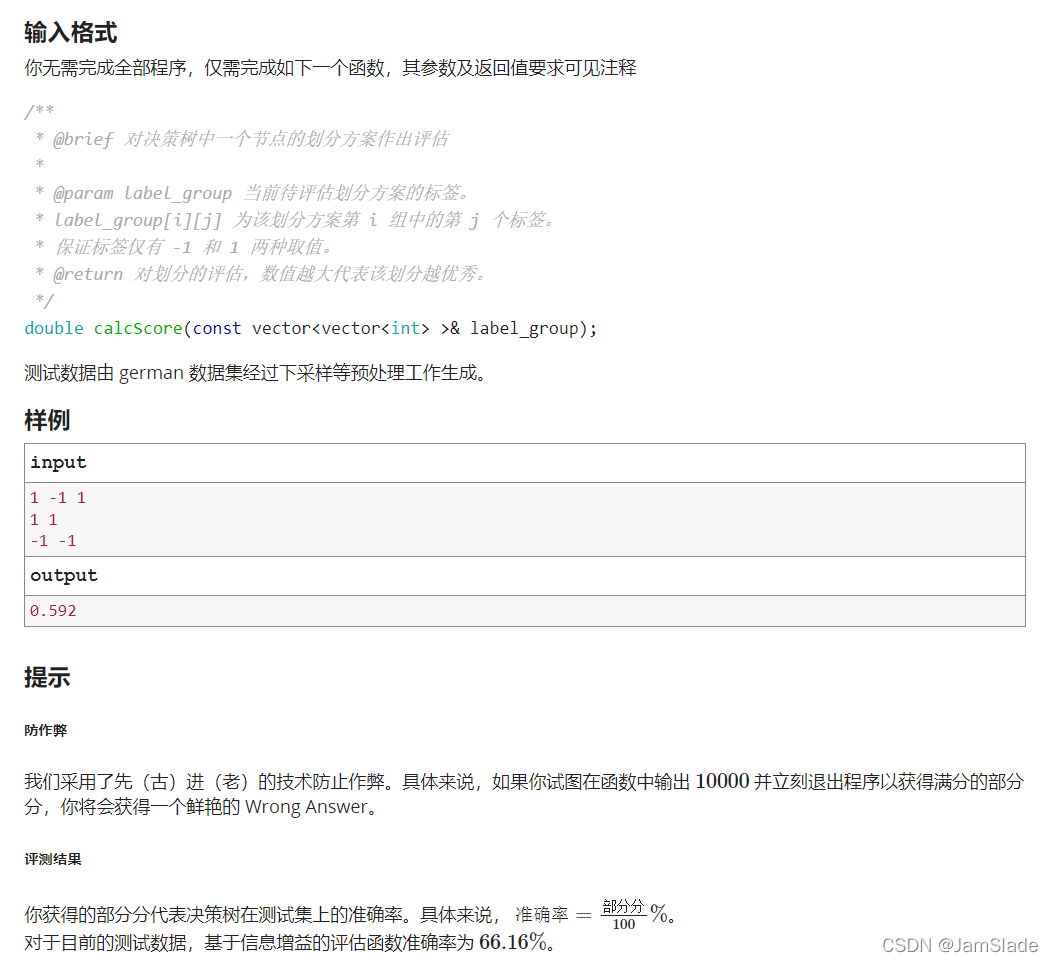
G.决策树

测评代码
#include <bits/stdc++.h>
using namespace std;
// 每个数据或是整数或是浮点数,实际使用时每个数据仅其中一个值有效
struct Val
{
int i;
double d;
Val(int _i): i(_i), d(0) {
}
Val(double _d): i(0), d(_d) {
}
};
bool operator != (const Val& lhs, const Val& rhs)
{
return lhs.i != rhs.i || lhs.d != rhs.d;
}
// 样本,包括每种属性及标签(1 或 -1)
struct Sample
{
vector<Val> atr;
int label;
Sample(): atr(), label(0) {
}
};
typedef vector<Sample> Data;
// 决策树节点
struct Tnode
{
int label; // 为 0 说明不为叶节点;否则标识叶节点对应标签
int atrno; // 该节点的划分属性的下标
int tp; // 0 代表连续值;1代表离散值
double par; // 若为连续值, 为划分点的值;若为离散值, 则无效
vector<Tnode> son; // 该节点的所有子节点
Tnode(): label(0), atrno(-1), tp(-1), par(0), son() {
}
};
string readLine(istream& fin)
{
string s;
// 读入数据并输入到 stringstream
if (fin.eof()) {
return s;
}
getline(fin, s);
for (int i = 0; i < s.length(); ++i) {
if (s[i] == ',') s[i] = ' ';
}
return s;
}
void readData(Data& data_all, vector<int>& type_all)
{
string s;
stringstream ss;
// 读入数据类型
s = readLine(cin);
ss << s;
while (true) {
int x;
ss >> x;
if (ss.fail()) break;
type_all.push_back(x);
}
// 读入数据
bool flag = true;
while (flag) {
string s;
stringstream ss;
s = readLine(cin);
ss << s;
Sample sp;
for (int t : type_all) {
if (t == 0) {
double x;
ss >> x;
if (ss.fail()) {
flag = false;
break;
}
sp.atr.push_back(x);
}
else {
int x;
ss >> x;
if (ss.fail()) {
flag = false;
break;
}
sp.atr.push_back(x);
}
}
if (!flag) break;
// 读取 label
int x;
ss >> x;
if (ss.fail()) break;
sp.label = x;
data_all.push_back(sp);
}
}
// 若数据集中所有样本有相同 label,返回该 label 值;否则返回 0
int getLabel(const Data& data_set)
{
int label = data_set[0].label;
for (int i = 1; i < data_set.size(); ++i) {
if (data_set[i].label != label) {
return 0;
}
}
return label;
}
// 判断数据集中所有样本是否在 atr_set 中的每个属性上取值都相同
bool sameAtr(const Data& data_set, const vector<int>& atr_set)
{
Sample sp = data_set[0];
for (int i = 1; i < data_set.size(); ++i) {
for (int atrno : atr_set) {
if (sp.atr[atrno] != data_set[i].atr[atrno]) {
return false;
}
}
}
return true;
}
// 计算数据集中样本数最多的类。若相同,随机取一个
int getMostLabel(const Data& data_set)
{
map<int, int> mp;
mp[-1] = 0;
mp[1] = 0;
for (auto sp : data_set) {
mp[sp.label]++;
}
if (mp[-1] > mp[1]) return -1;
if (mp[-1] < mp[1]) return 1;
return rand() % 2 == 0 ? -1 : 1;
}
// 将数据集按某一属性分割,若为连续值则以 par 为分界点分割
vector<Data> splitData(const Data& data_set, int atrno, double par, const vector<int>& type_all)
{
int tp = type_all[atrno];
vector<Data> datas(2);
if (tp == 0) {
for (auto e : data_set) {
if (e.atr[atrno].d < par) {
datas[0].push_back(e);
}
else {
datas[1].push_back(e);
}
}
}
else {
for (auto e : data_set) {
datas[e.atr[atrno].i].push_back(e);
}
}
return datas;
}
/**
* @brief 对决策树中一个节点的划分方案作出评估
*
* @param label_group 当前待评估划分方案的标签。label_group[i][j] 为该划分方案第 i 组中的第 j 个标签。保证标签仅有 -1 和 1 两种取值。
* @return 对划分的评估,数值越大代表该划分越优秀。
*/
double calcScore(const vector<vector<int> >& label_group);
// 你的代码将被嵌入此处
// 将 datas 中的 label 提取出来,调用 calcScore 获取得分
double getScore(const vector<Data>& datas)
{
vector<vector<int> > label_group;
for (const Data& dt : datas) {
vector<int> labels;
for (auto sp : dt) {
labels.push_back(sp.label);
}
label_group.push_back(labels);
}
return calcScore(label_group);
}
// 获取某一划分的分数及划分点(若为连续变量)
pair<double, double> getScoreAndPar(const Data& data_set, int atrno, const vector<int>& type_all)
{
if (type_all[atrno] == 0) {
vector<double> points;
for (auto dt : data_set) {
points.push_back(dt.atr[atrno].d);
}
sort(points.begin(), points.end());
points.push_back(points.back() + 1);
vector<pair<double, double> > rets;
for (int i = 0; i < points.size() - 1; ++i) {
if (points[i] == points[i + 1]) continue;
double par = (points[i] + points[i + 1]) / 2;
vector<Data> datas = splitData(data_set, atrno, par, type_all);
rets.push_back({
getScore(datas), par});
}
assert(!rets.empty());
sort(rets.begin(), rets.end(), greater<pair<double, double> >());
while (rets.size() > 1 && rets.back().first != rets.front().first) {
rets.pop_back();
}
int no = rand() % rets.size();
return rets[no];
}
else {
vector<Data> datas = splitData(data_set, atrno, 0, type_all);
return {
getScore(datas), 0};
}
}
// 构建决策树
Tnode buildTree(const Data& data_set, const vector<int>& atr_set, const vector<int>& type_all)
{
Tnode node;
// 处理样本类别全部相同的情况
node.label = getLabel(data_set);
if (node.label) {
// printf("*1*\n");
return node;
}
// 处理属性集为空或所有样本在属性集上取值全部相同的情况
if (atr_set.empty() || sameAtr(data_set, atr_set)) {
// printf("*2*\n");
node.label = getMostLabel(data_set);
return node;
}
// 选择最优属性. 若有多个, 随机选择其中一个
vector<pair<pair<double, double>, int> > v;
for (auto atrno : atr_set) {
v.push_back({
getScoreAndPar(data_set, atrno, type_all), atrno});
}
sort(v.begin(), v.end(), greater<pair<pair<double, double>, int> >());
while (v.size() > 1 && v.back().first.first != v.front().first.first) {
v.pop_back();
}
int no = rand() % v.size();
node.atrno = v[no].second;
node.tp = type_all[node.atrno];
node.par = v[no].first.second;
// 生成分支
vector<Data> datas = splitData(data_set, node.atrno, node.par, type_all);
vector<int> new_atr_set;
if (node.tp == 0) {
new_atr_set = atr_set;
}
else {
for (auto atrno : atr_set) {
if (atrno != node.atrno) new_atr_set.push_back(atrno);
}
}
for (int i = 0; i < 2; ++i) {
if (datas[i].empty()) {
Tnode nd;
nd.label = getMostLabel(data_set);
node.son.push_back(nd);
}
else {
node.son.push_back(buildTree(datas[i], new_atr_set, type_all));
}
}
return node;
}
void print(const Tnode& now, int tab = 0)
{
putchar('~');
for (int i = 0; i < tab; ++i) {
putchar('|');
}
printf("(%d, %d, %d, %f)\n", now.label, now.atrno, now.tp, now.par);
if (!now.label) {
for (const Tnode& p : now.son) {
print(p, tab + 1);
}
}
}
// 预测一个数据的值
int fit(const Tnode& root, const Sample& sample_in)
{
if (root.label != 0) return root.label;
if (root.tp == 1) return fit(root.son[sample_in.atr[root.atrno].i], sample_in);
if (sample_in.atr[root.atrno].d < root.par) return fit(root.son[0], sample_in);
return fit(root.son[1], sample_in);
}
// 返回一个vector,内容为对每个输入数据的预测
vector<int> predict(const Tnode& root, const Data& data_set)
{
vector<int> ret;
for (auto e : data_set) {
ret.push_back(fit(root, e));
}
return ret;
}
double trainAndTest(const Data& data_train, const Data& data_test, const vector<int>& type_all)
{
vector<int> atr_set;
for (int i = 0; i < type_all.size(); ++i)
{
atr_set.push_back(i);
}
Tnode root = buildTree(data_train, atr_set, type_all);
vector<int> pred = predict(root, data_test);
int total_num = data_test.size();
int correct = 0;
for (int i = 0; i < total_num; ++i)
{
if (pred[i] == data_test[i].label)
++correct;
}
return double(correct) / total_num;
}
double crossValidate(const Data& data_all, const vector<int>& type_all, int folder_num)
{
vector<Data> datas(2);
for (auto dt : data_all) {
if (dt.label == -1) datas[0].push_back(dt);
else datas[1].push_back(dt);
}
for (Data& data : datas) {
random_shuffle(data.begin(), data.end());
}
vector<Data> data_folder;
for (int i = 0; i < folder_num; ++i) {
Data folder;
for (const Data& data : datas) {
int l = i * data.size() / folder_num;
int r = (i + 1) * data.size() / folder_num;
for (int i = l; i < r; ++i) {
folder.push_back(data[i]);
}
}
data_folder.push_back(folder);
}
double precision = 0;
for (int i = 0; i < folder_num; ++i) {
Data data_train, data_test;
for (int j = 0; j < folder_num; ++j) {
if (i == j) {
data_test.insert(data_test.end(), data_folder[j].begin(), data_folder[j].end());
}
else {
data_train.insert(data_train.end(), data_folder[j].begin(), data_folder[j].end());
}
}
precision += trainAndTest(data_train, data_test, type_all) / folder_num;
}
return precision;
}
int main()
{
Data data_all;
vector<int> type_all;
srand(19260817);
readData(data_all, type_all);
double precion = crossValidate(data_all, type_all, 10);
// 输出密码,防止偷鸡行为
printf("%.2f\n", precion * 100);
return 0;
}
信息增益
经过测试确实也只有66.16%概率正确
#include<vector>
#include<cmath>
using namespace std;
double calcScore(const vector<vector<int> >& label_group)
{
double EntD = 0;
vector<double>Earray;
vector<int>Enum;
int all_pos = 0, all_neg = 0;
int leni = label_group.size();
for(int i = 0; i < leni; i++)
{
int part_pos = 0, part_neg = 0;
int lenj = label_group[i].size();
for(int j = 0; j < lenj; j++)
{
int temp = label_group[i][j];
if(temp == 1)
{
part_pos += 1;
all_pos += 1;
}
else
{
part_neg += 1;
all_neg += 1;
}
}
double EntTemp;
int SUM = part_neg + part_pos;
if(!part_neg || !part_pos)//存在一个是0
EntTemp = 0;
else
{
double fac1 = (double)part_neg / SUM;
double fac2 = (double)part_pos / SUM;
EntTemp = -(fac1*log2(fac1) + fac2*log2(fac2));
}
Earray.push_back(EntTemp);
Enum.push_back(SUM);
}
double fac1 = (double)all_neg / (all_neg+all_pos);
double fac2 = (double)all_pos / (all_neg+all_pos);
double res = -(fac1*log2(fac1) + fac2*log2(fac2));
for(int i = 0; i < Earray.size(); i++)
res -= Earray[i] * ((double)Enum[i] / (all_neg + all_pos));
return res;
}
H.K_means

程序主体如下所示。
#include <iostream>
#include <algorithm>
#include <vector>
#include <cmath>
using namespace std;
const double eps = 1e-6;
struct Point {
vector<double> coordinate;
int groupId;
/**
* @brief 计算两个 Point 之间的欧氏距离的平方,
* 要求两个 Point coordinate 长度相等
*/
double distance(const Point &other) const {
// 采用欧氏距离平方作为指标.
double ans = 0;
int sz = max(coordinate.size(), other.coordinate.size());
for (int i = 0; i < sz; ++i)
ans += (coordinate[i] - other.coordinate[i]) * (coordinate[i] - other.coordinate[i]);
return ans;
}
/**
* @brief 将另一个 Point 赋值给当前 Point
*/
Point &operator=(const Point &other) {
if (this == &other) return *this;
coordinate = other.coordinate;
groupId = other.groupId;
return *this;
}
/**
* @brief 按 coordinate 顺序比较两个 Point 的大小,
* 要求两个 Point coordinate 长度相等
*/
bool operator<(const Point &other) const {
auto sz = max(coordinate.size(), other.coordinate.size());
for (auto i = 0; i < sz; ++i)
if (fabs(coordinate[i] - other.coordinate[i]) > eps)
return coordinate[i] < other.coordinate[i];
return false;
}
};
// 你的代码会被嵌入在这
bool vectorIsEqual(const vector<Point> ¢ers, const vector<Point> &temp) {
auto v1 = centers;
sort(v1.begin(), v1.end());
auto v2 = temp;
sort(v2.begin(), v2.end());
auto k = max(v1.size(), v2.size());
for (auto i = 0; i < k; ++i)
if (v1[i] < v2[i] || v2[i] < v1[i])
return false;
return true;
}
vector<Point> kMeans(vector<Point> &points, const int k) {
vector<Point> centers(k);
vector<Point> temp;
for (auto i = 0; i < k; ++i)
centers[i] = points[i];
do {
temp = centers;
centers = update(points, temp);
} while (!vectorIsEqual(centers, temp));
return centers;
}
double score(const vector<Point> &points, const vector<Point> ¢ers) {
auto n = points.size();
auto ans = 0.0;
for (auto i = 0; i < n; ++i)
ans += points[i].distance(centers[points[i].groupId]);
return ans;
}
int main() {
int n, m;
scanf("%d%d", &n, &m);
vector<int> target(n);
vector<Point> points(n);
for (int i = 0; i < n; ++i) {
points[i].coordinate.resize(m);
for (int j = 0; j < m; ++j) {
scanf("%lf", &(points[i].coordinate[j]));
}
scanf("%d", &target[i]);
}
auto centers = kMeans(points, 2);
printf("%f\n", (double)score(points, centers));
return 0;
}
代码
vector<Point> update(vector<Point> &points, const vector<Point> &last)
{
vector<Point> newest(last);
vector<int> count;
int lenl = last.size();
int lenp = points.size();
int cor_l = last[0].coordinate.size();
//进行迭代
//修改分组
for(int i = 0; i < lenp; i++)
{
double dis = 0xffffffff;
int id = 0;
for(int j = 0; j < lenl; j++)
{
double temp = points[i].distance(last[j]);
if(temp < dis)
{
dis = temp;
id = j;
}
}
points[i].groupId = id;
}//一开始只进行迭代 就能获得6分
//记录新的组的情况
//清零
int* cnt = new int[lenl];
for(int i = 0; i < lenl; i++)
{
cnt[i] = 0;
for(int j = 0; j < cor_l; j++)
{
newest[i].coordinate[j] = 0;
}
}//完成归零这一步能上到35分
//更新最近点
//每个点都加进去,并计算一个集合的数量
for(int i = 0; i < lenp; i++)
{
cnt[points[i].groupId] ++;
for(int j = 0; j < cor_l; j++)
{
int id = points[i].groupId;
newest[id].coordinate[j] += points[i].coordinate[j];
}
}
//相除
for(int i = 0; i < lenl; i++)
{
for(int j = 0; j < cor_l; j++)
{
// if(cnt[i])
newest[i].coordinate[j] /= cnt[i];
}
}
delete[] cnt;
return newest;
}
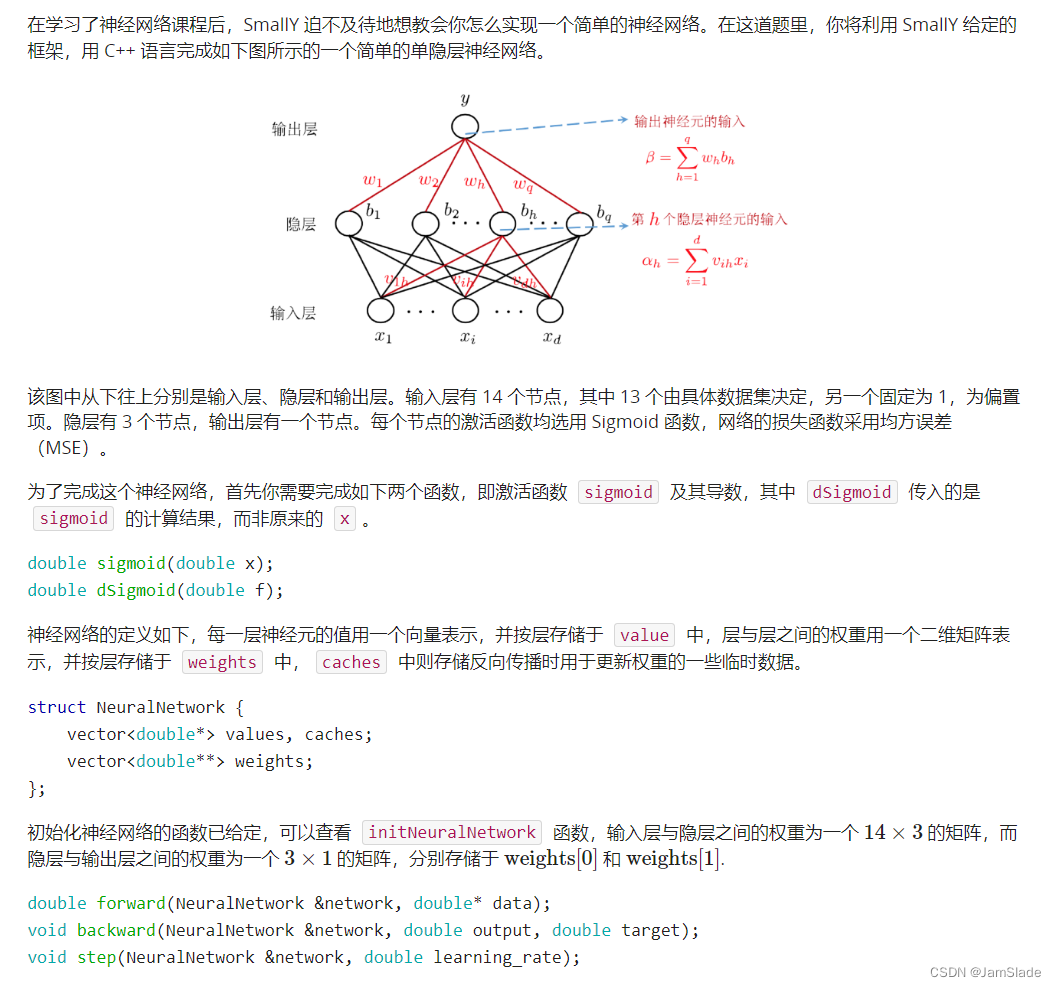
I.神经网络入门
#include "bits/stdc++.h"
using namespace std;
double mseLoss(double x, double target) {
return 0.5 * (x - target) * (x - target);
}
struct NeuralNetwork {
vector<double*> values, caches;
vector<double**> weights;
};
void standardize(double **data, int dataSize, int featureSize) {
for (int j = 0; j <= featureSize; ++j) {
double mean = 0;
for (int i = 0; i < dataSize; ++i)
mean += data[i][j] / dataSize;
double variance = 0;
for (int i = 0; i < dataSize; ++i)
variance += (data[i][j] - mean) * (data[i][j] - mean) / (dataSize - 1);
for (int i = 0; i < dataSize; ++i)
data[i][j] = (data[i][j] - mean) / sqrt(variance);
}
}
pair<vector<double*>, vector<double*>> make_dataset(int dataSize, int featureNum) {
double **data = (double**)malloc(dataSize * sizeof(double*));
for (int i = 0; i < dataSize; ++i) {
data[i] = (double*)malloc((featureNum + 2) * sizeof(double));
data[i][0] = 0;
for (int j = 0; j <= featureNum; ++j)
scanf("%lf", &data[i][j]);
}
standardize(data, dataSize, featureNum);
for (int i = 0; i < dataSize; ++i) {
data[i][featureNum + 1] = data[i][featureNum];
data[i][featureNum] = 1; // 偏置项
}
int trainSize = 0.8 * dataSize;
vector<int> index(dataSize);
for (int i = 0; i < dataSize; ++i)
index[i] = i;
random_shuffle(index.begin(), index.end());
vector<double*> train, valid;
for (int i = 0; i < trainSize; ++i)
train.push_back(data[index[i]]);
for (int i = trainSize; i < dataSize; ++i)
valid.push_back(data[index[i]]);
return make_pair(train, valid);
}
NeuralNetwork initNeuralNetwork() {
uniform_real_distribution<> random{
-1, 1};
default_random_engine eng{
0};
NeuralNetwork network{
};
double **weight = (double**)malloc(14 * sizeof(double*));
for (int i = 0; i < 14; ++i) {
weight[i] = (double*)malloc(3 * sizeof(double));
for (int j = 0; j < 3; ++j)
weight[i][j] = random(eng);
}
network.weights.push_back(weight);
weight = (double**)malloc(3 * sizeof(double*));
for (int i = 0; i < 3; ++i) {
weight[i] = (double*)malloc(sizeof(double));
for (int j = 0; j < 1; ++j)
weight[i][j] = random(eng);
}
network.weights.push_back(weight);
return network;
}
// 你的代码会被嵌入在这
double evaluate(NeuralNetwork &network, vector<double*> &valid, int featureNum) {
double loss = 0;
for (int i = 0; i < valid.size(); ++i) {
double output = forward(network, valid[i]);
loss += mseLoss(output, valid[i][featureNum + 1]);
}
return loss / valid.size();
}
int main() {
int dataSize, featureNum;
scanf("%d%d", &dataSize, &featureNum);
auto pair = make_dataset(dataSize, featureNum);
auto train = pair.first, valid = pair.second;
uniform_int_distribution<int> random{
0, (int)train.size() - 1};
default_random_engine eng{
0};
auto network = initNeuralNetwork();
for (int i = 0; i < 10000; ++i) {
int idx = random(eng);
double output = forward(network, train[idx]);
backward(network, output, train[idx][featureNum + 1]);
step(network, 0.01);
}
printf("%lf\n", evaluate(network, valid, featureNum));
return 0;
}
思路
这个ppt写的也太抽象了。。。
向前
input 加权得到隐藏层的数据
比如input 1 , 2 , 3 1,2,3 1,2,3
隐藏层第一个点权分别是 0.1 , 0.2 , 0.3 0.1,0.2,0.3 0.1,0.2,0.3
第二个点的权是 0.2 , 0.2 , 0.2 0.2,0.2,0.2 0.2,0.2,0.2
于是就有第一个点加权和为
1 × 0.1 + 2 × 0.2 + 3 × 0.3 = 1.4 1\times 0.1 + 2\times 0.2 + 3\times 0.3 = 1.4 1×0.1+2×0.2+3×0.3=1.4
第二个点加权和
1 × 0.2 + 2 × 0.2 + 3 × 0.2 = 1.2 1\times 0.2 + 2\times 0.2 + 3\times 0.2 = 1.2 1×0.2+2×0.2+3×0.2=1.2
第一个点最后的输出要经过sigmoid函数激活
o u t 1 = 1 1 + e − 1.4 out_1 = \frac{1}{1+e^{-1.4}} out1=1+e−1.41
同理
o u t 2 = 1 1 + e − 1.2 out_2 = \frac{1}{1+e^{-1.2}} out2=1+e−1.21
然后拿这两个输出再进行加权和得到最终的output加权
o u t p u t 加权 = o u t 1 × w e i g h t 1 + o u t p u t 2 × w e i g h t 2 output_{加权} = out_1\times weight_1+output_2\times weight_2 output加权=out1×weight1+output2×weight2
o u t p u t f i n a l = o u t 1 = 1 1 + e o u t p u t 加权 output_{final} =out_1 = \frac{1}{1+e^{output_{加权}}} outputfinal=out1=1+eoutput加权1
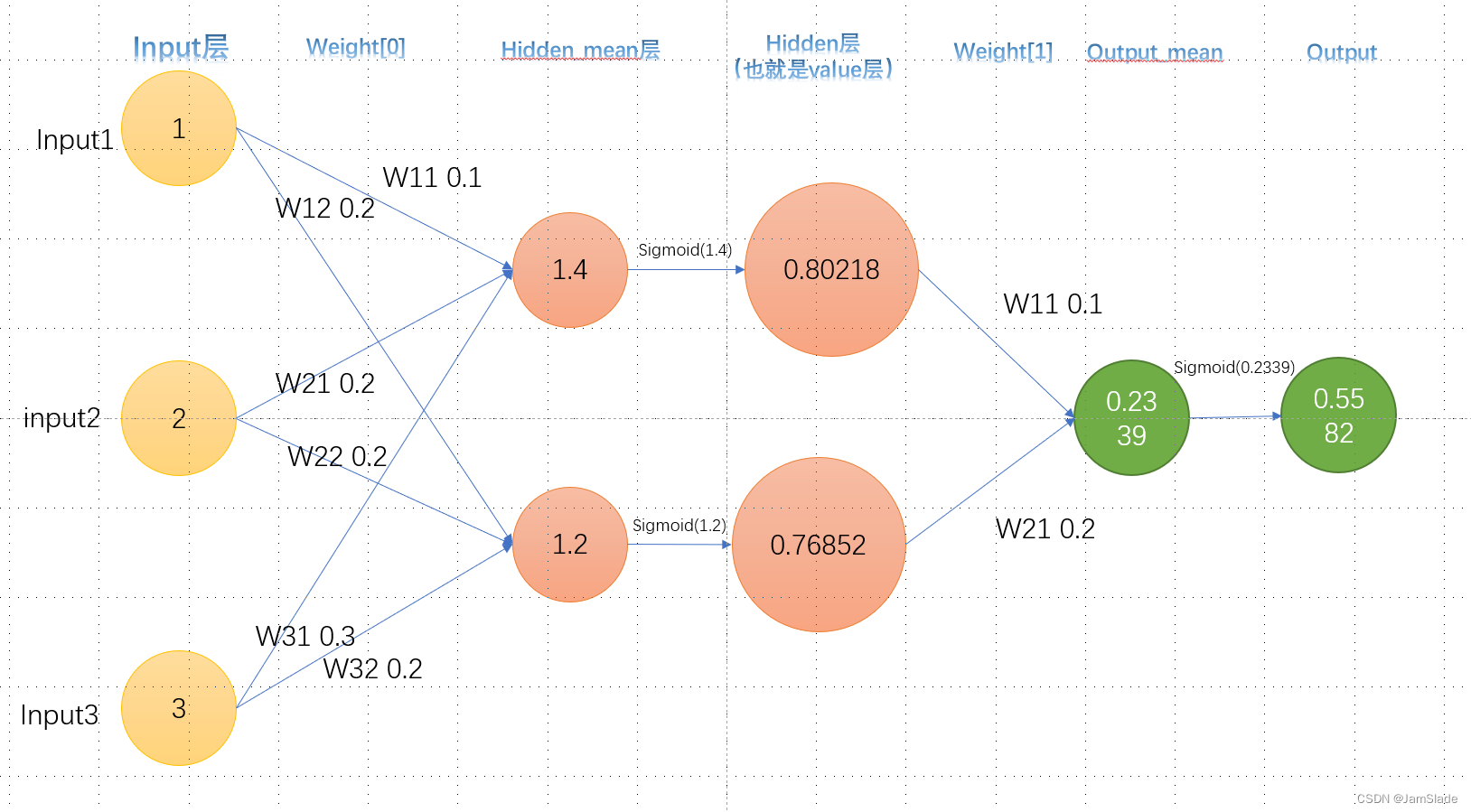
在forward里面,我们需要保留的是input层,hidden层和output层,也就是第一列,第三列和第五列
向后
backward部分由于要找到每个weight 对于output和target的差距的影响
【这里用的是mseLoss函数,就是求output到target距离的一半大小】
要对每个对应的权求微分
如何求呢?
我们从近的开始求
hidden层的weight变化
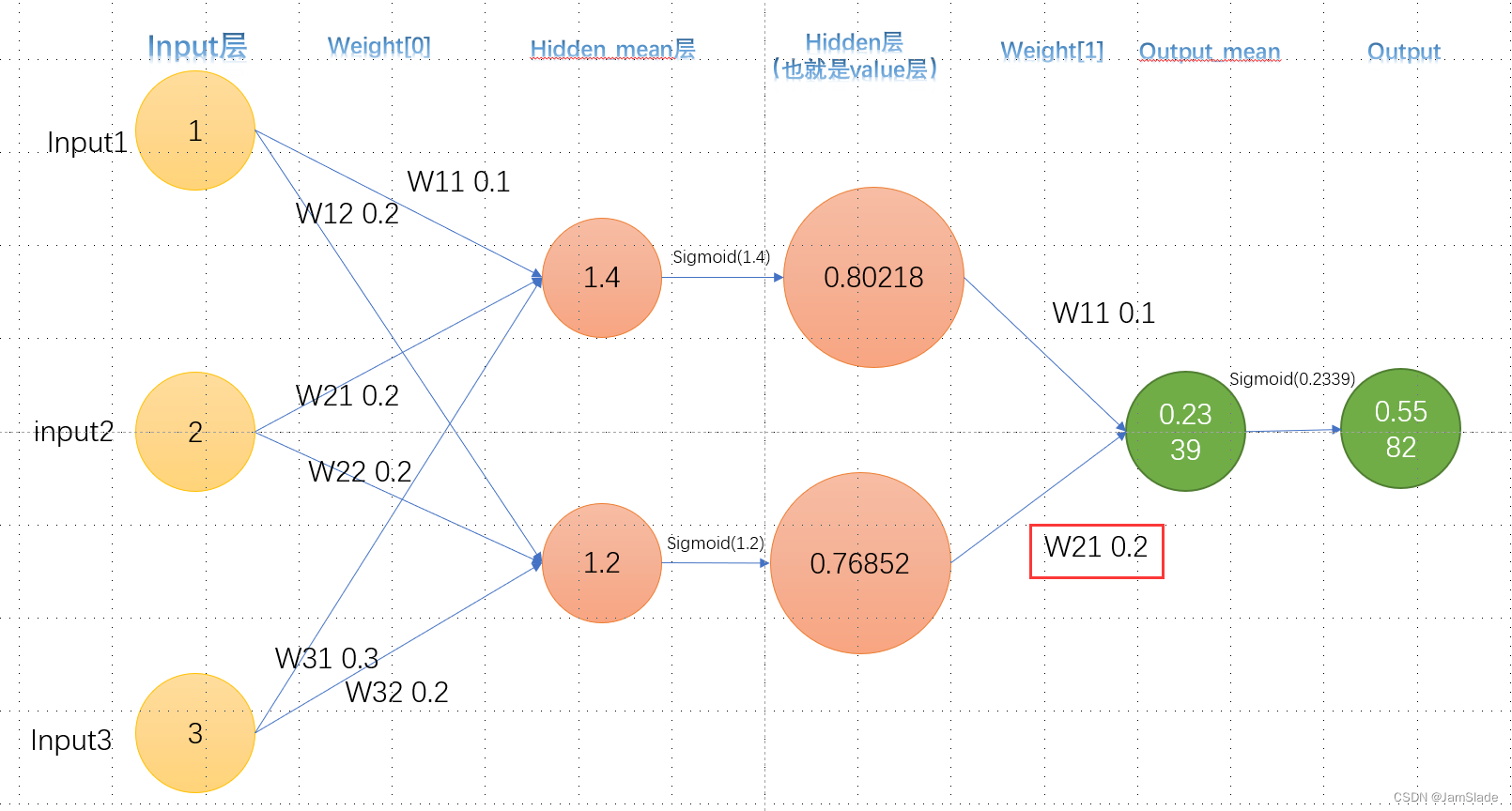
不妨叫这个红色部分的W21为
W 121 : 在 w e i g h t 1 下的第 2 个 h i d d e n 对第 1 个 o u t p u t W_{121}:在weight1下的第2个hidden对第1个output W121:在weight1下的第2个hidden对第1个output
我们就是要求
∂ L o s s ∂ W 121 \frac{\partial Loss}{\partial W_{121}} ∂W121∂Loss
Loss是output(在这个图里面就是最后的0.5582)和目标输出的差距
L o s s = 1 2 ( t a r g e t − O ) 2 Loss = \frac{1}{2}( target - O)^2 Loss=21(target−O)2
根据链式求导法则我们可以展开
∂ L o s s ∂ W 121 = ∂ L o s s ∂ O ∂ O ∂ O m e a n ∂ O m e a n ∂ W 121 \frac{\partial Loss}{\partial W_{121}}=\frac{\partial Loss}{\partial O}\frac{\partial O}{\partial O_{mean}}\frac{\partial O_{mean}}{\partial W_{121}} ∂W121∂Loss=∂O∂Loss∂Omean∂O∂W121∂Omean
这里做如下解释
- Loss就是上文公式,对O求导得到 ( O − t a r g e t ) (O-target) (O−target)
- O就是第五列的输出,而 O m e a n O_{ mean} Omean指的是第四列,实际上就是对 S i g m o i d ( O ) Sigmoid(O) Sigmoid(O)里面对O求导 ∂ S i g m o i d ( O ) ∂ O = S i g m o i d ( O ) × ( 1 − S i g m o i d ( O ) ) \frac{\partial Sigmoid(O)}{\partial O} = Sigmoid(O)\times(1-Sigmoid(O)) ∂O∂Sigmoid(O)=Sigmoid(O)×(1−Sigmoid(O))
3. O m e a n = H 1 × W 111 + H 2 × W 121 O_{mean} = H_1\times W_{111}+H_2\times W_{121} Omean=H1×W111+H2×W121,所以对Weight求导就是H2了
对应MseLoss的导数以及下图的两个部分
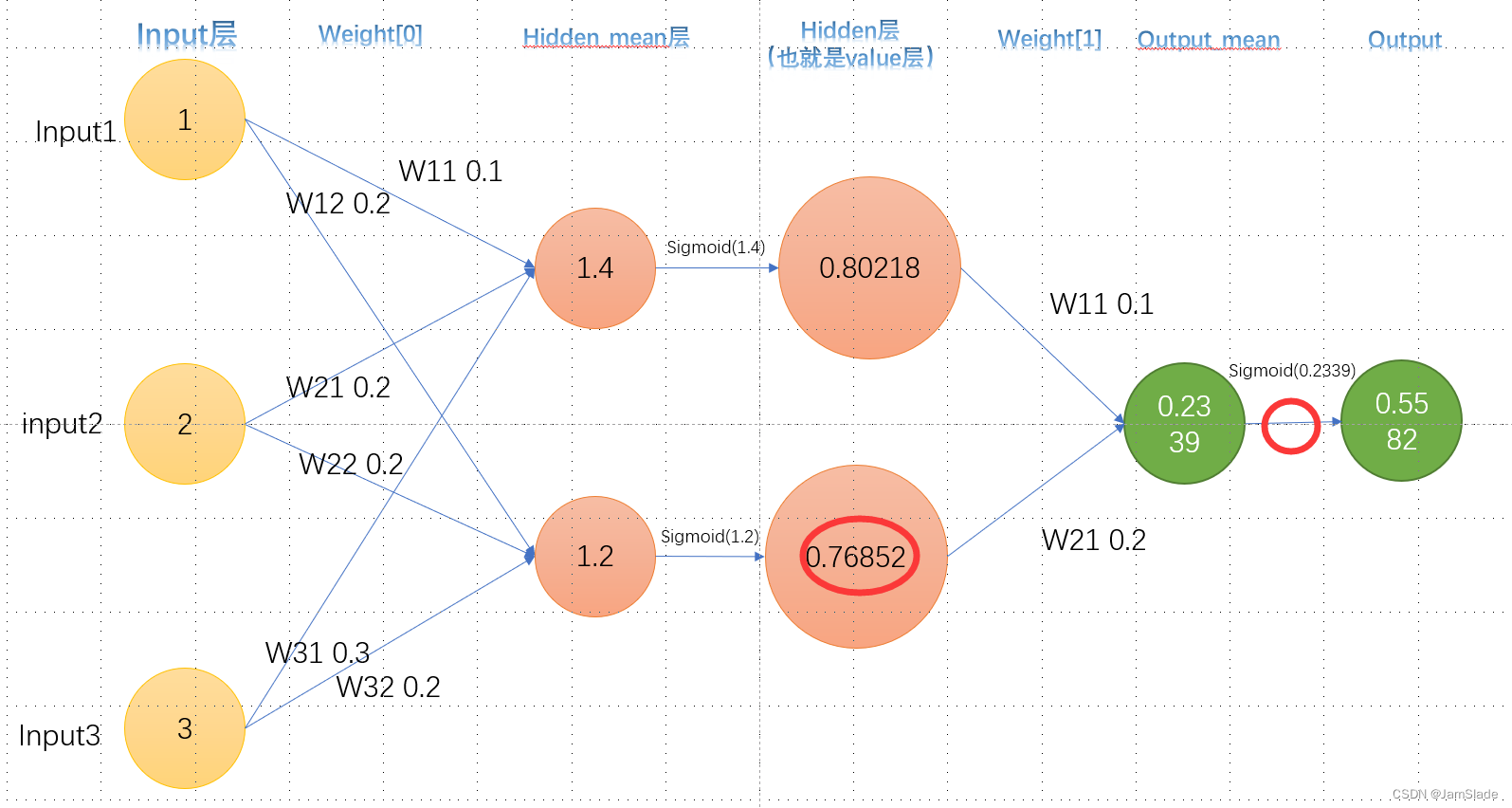
这样我们把上面的式子相乘就可以求 ∂ L o s s ∂ W 121 \frac{\partial Loss}{\partial W_{121}} ∂W121∂Loss
然后我们对这一个 W 121 W_{121} W121进行相减操作
W 121 = W 121 − η ∂ L o s s ∂ W 121 W_{121} = W_{121}-\eta\frac{\partial Loss}{\partial W_{121}} W121=W121−η∂W121∂Loss
其中 η \eta η是学习速率,自己定义即可
input的weight变化
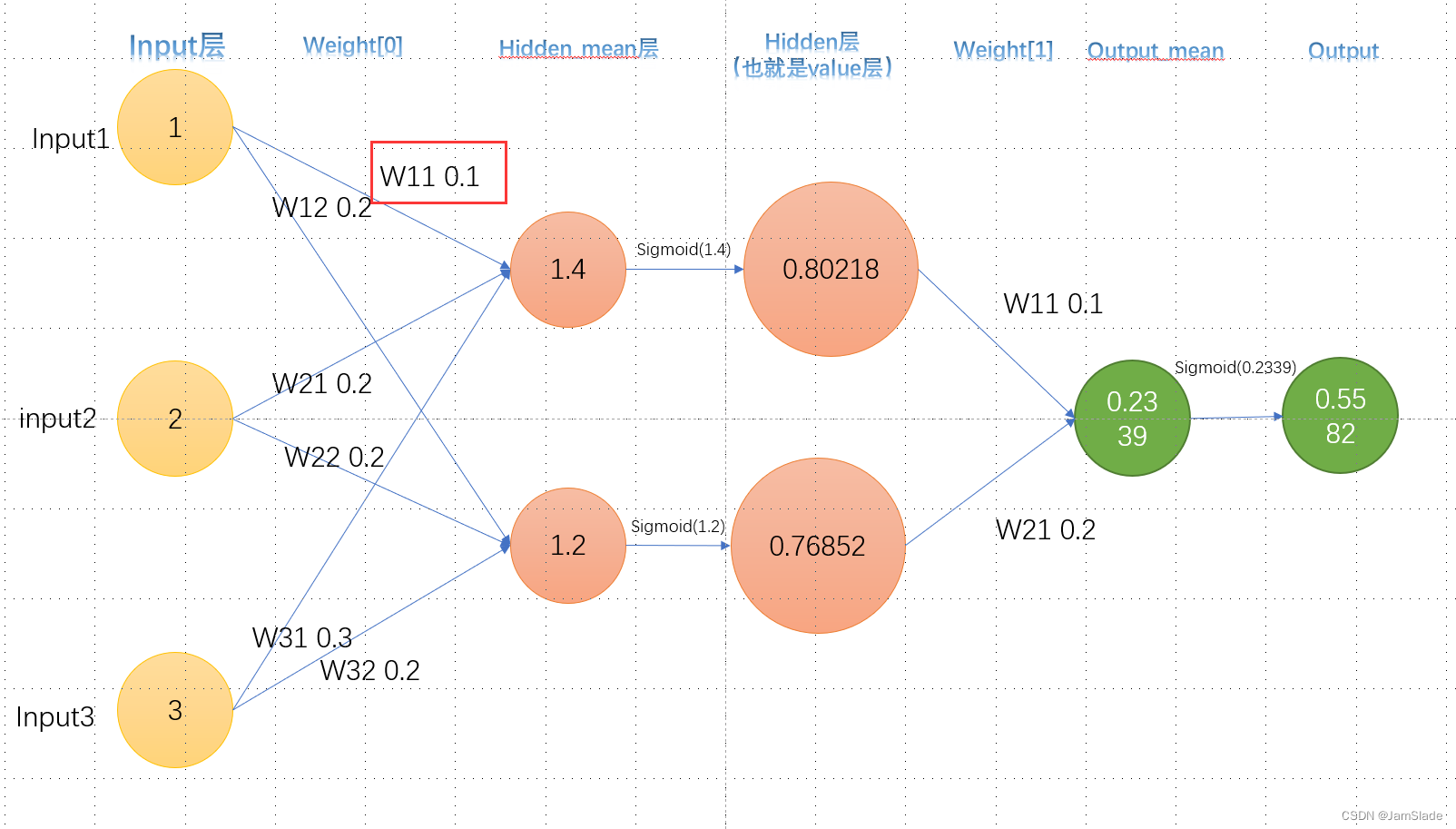
接下来求 W 011 W_{011} W011
∂ L o s s ∂ W 011 = ∂ L o s s ∂ H 1 ∂ H 1 ∂ H m e a n ∂ H m e a n ∂ W 011 = ∂ L o s s ∂ O ∂ O ∂ O m e a n ∂ O m e a n ∂ H 1 ∂ H 1 ∂ H m e a n ∂ H m e a n ∂ W 011 \left.\begin{aligned}\frac{\partial Loss}{\partial W_{011}} &=\frac{\partial Loss}{\partial H_1}\frac{\partial H_1}{\partial H_{mean}}\frac{\partial H_{mean}}{\partial W_{011}}\\ &=\frac{\partial Loss}{\partial O}\frac{\partial O}{\partial O_{mean}}\frac{\partial O_{mean}}{\partial H_1}\frac{\partial H_1}{\partial H_{mean}}\frac{\partial H_{mean}}{\partial W_{011}} \end{aligned}\right. ∂W011∂Loss=∂H1∂Loss∂Hmean∂H1∂W011∂Hmean=∂O∂Loss∂Omean∂O∂H1∂Omean∂Hmean∂H1∂W011∂Hmean
对应为MseLoss的求导和下图的4个部分

从左到右分别是【可以自己求一下偏导试试】
- o u t p u t − t a g e r t output - tagert output−tagert
- S i g m o i d ( O m e a n ) × ( 1 − S i g m o i d ( O m e a n ) ) Sigmoid(O_{mean})\times(1-Sigmoid(O_{mean})) Sigmoid(Omean)×(1−Sigmoid(Omean))
- W 111 W_{111} W111
- S i g m o i d ( H m e a n ) × ( 1 − S i g m o i d ( H m e a n ) ) Sigmoid(H_{mean})\times(1-Sigmoid(H_{mean})) Sigmoid(Hmean)×(1−Sigmoid(Hmean))
- i n p u t 1 input_1 input1
output不止一种的情况
如果最终输出output不止一个,对于第二种情况来说要求的偏导会稍微麻烦一点可以参考这篇文章
一文弄懂神经网络中的反向传播法——BackPropagation
代码
double sigmoid(double x);
double dSigmoid(double f);
double forward(NeuralNetwork &network, double* data);
void backward(NeuralNetwork &network, double output, double target);
void step(NeuralNetwork &network, double learning_rate);
double sigmoid(double x)
{
return (1/(1+exp(-x)));
}
double dSigmoid(double f)
{
return f*(1-f);
}
double forward(NeuralNetwork &network, double* data)
{
network.values.clear();
double* input = new double[14];
double* sig_hidden = new double[3];
double* sig_output = new double[1];
for(int i = 0; i < 14; i++)
input[i] = data[i];
double** dp = network.weights[0];
for(int i = 0; i < 3; i++)
{
double ave_sum = 0.0;
for(int j = 0; j < 14; j++)
{
ave_sum += dp[j][i] * input[j];
}
sig_hidden[i] = sigmoid(ave_sum);
}
dp = network.weights[1];
for(int i = 0; i < 1; i++)
{
double ave_sum = 0.0;
for(int j = 0; j < 3; j++)
{
ave_sum += dp[j][i] * sig_hidden[j];
}
sig_output[i] = sigmoid(ave_sum);
}
network.values.push_back(input);
network.values.push_back(sig_hidden);
network.values.push_back(sig_output);
return sig_output[0];
}
void backward(NeuralNetwork &network, double output, double target)
{
network.caches.clear();
double* pEloss_pOut_pAve = new double[1];
double* pEloss_pOut_pAve_pHid_pAveHid = new double[3];
pEloss_pOut_pAve[0] = (output - target) * dSigmoid(output);
double** dp = network.weights[1];
double* hid = network.values[1];
for(int i = 0; i < 3; i++)
{
pEloss_pOut_pAve_pHid_pAveHid[i] = pEloss_pOut_pAve[0] \
* dp[i][0] * dSigmoid(hid[i]);
}
network.caches.push_back(pEloss_pOut_pAve);
network.caches.push_back(pEloss_pOut_pAve_pHid_pAveHid);
}
void step(NeuralNetwork &network, double learning_rate)
{
for(int i = 0; i < 3; i++)
network.weights[1][i][0] -= learning_rate * network.caches[0][0] * network.values[1][i];
for(int i = 0; i < 13; i++)
for(int j = 0; j < 3; j++)
network.weights[0][i][j] -= learning_rate * network.caches[1][j] * network.values[0][i];
for(int i = 13; i < 14; i++)
for(int j = 0; j < 3; j++)
network.weights[0][i][j] += learning_rate * network.caches[1][j] * network.values[0][i];
// 需要的是针对第13项(偏置项)需要特殊处理一下,把-=变成+=
// 如果不改的话其实单纯调参(修改learning rate)也是可行的
return;
}
细节修改版
#include<bits/stdc++.h>
using namespace std;
struct NeuralNetwork {
vector<double*> values, caches;
vector<double**> weights;
};
double sigmoid(double x);
double dSigmoid(double f);
double forward(NeuralNetwork &network, double* data);
void backward(NeuralNetwork &network, double output, double target);
void step(NeuralNetwork &network, double learning_rate);
double sigmoid(double x)
{
return (1 /(1 + exp(-x)));
}
double dSigmoid(double f)
{
return f*(1-f);
}
double forward(NeuralNetwork &network, double* data)
{
network.values.clear();
double* input = new double[14];
double* sig_hidden = new double[3];
double* sig_out = new double[1];
for(int i = 0; i < 14; i++)
input[i] = data[i];
double** dp = network.weights[0];
for(int j = 0; j < 3; j++)
{
double SUM = 0.0;
for(int i = 0; i < 14; i++)
{
SUM += dp[i][j] * data[i];
}
sig_hidden[j] = sigmoid(SUM);
}
dp = network.weights[1];
for(int j = 0; j < 1; j++)
{
double SUM = 0.0;
for(int i = 0; i < 3; i++)
{
SUM += dp[i][j] * sig_hidden[i];
}
sig_out[0] = sigmoid(SUM);
}
network.values.push_back(input);
network.values.push_back(sig_hidden);
network.values.push_back(sig_out);
return network.values[2][0];
}
void backward(NeuralNetwork &network, double output, double target)
{
network.caches.clear();
double* temp1 = new double[1];
double* temp2 = new double[1];
double* temp3 = new double[3];
double* temp4 = new double[3];
double* temp5 = new double[14];
double* temp__ = new double[3];
// 第一步,获得mseLoss对 output的求导
temp1[1] = network.values[2][0] - target;
// 第二,获取sig_output的导数
temp2[1] = dSigmoid(network.values[2][0]);
//第三,获取sig_output对三个sig_hidden对应的权的求导
for(int i = 0; i < 3; i++)
{
temp3[i] = network.values[1][i];
//也就是sig_hidden
}
//插入一步 获取权
for(int i = 0; i < 3; i++)
{
temp__[i] = network.weights[1][i][0];
//也就是sig_hidden
}
//第四 获取sig_hidden的导数
for(int i = 0; i < 3; i++)
{
temp4[i] = dSigmoid(network.values[1][i]);
//也就是sig_hidden
}
//第五 获取sig_hidden对input对应的权的导数
for(int i = 0; i < 14; i++)
{
temp5[i] = network.values[0][i];
//也就是input
}
network.caches.push_back(temp1);
network.caches.push_back(temp2);
network.caches.push_back(temp__);
network.caches.push_back(temp3);
network.caches.push_back(temp4);
network.caches.push_back(temp5);
}
void step(NeuralNetwork &network, double learning_rate)
{
double** a = network.weights[1];
for(int i = 0; i < 3; i++)
{
for(int j = 0; j < 1; j++)
{
a[i][j] -= learning_rate * network.caches[0][j]\
* network.caches[1][j] * network.caches[2][i];
}
}
a = network.weights[0];
for(int k = 0; k < 14; k++)
for(int i = 0; i < 3; i++)
{
for(int j = 0; j < 1; j++)
{
a[k][i] -= learning_rate * network.caches[0][j]\
* network.caches[1][j] * network.caches[3][i]\
* network.caches[4][i] * network.caches[5][k];
}
}
return;
}
J.迷宫寻宝
#include <bits/stdc++.h>
using namespace std;
const int maxn = 21;
const int epics = 50000;
const int target_success = 5000;
const double inf = 1e8;
bool cmp(pair<int,double> X, pair<int,double> Y)
{
if(X.second == Y.second) return X.first < Y.first;
return X.second > Y.second;
}
// 迷宫尺寸 n*m
// x,y坐标从1开始 起点(1,1) 终点(n,m)
// 对于每个位置(i,j),可以向U,L,R,D四个方向移动,不可走出迷宫边界,不可走到障碍物上
int n,m;
// maze[maxn+5][maxn+5]存储迷宫 0代表可走通 1代表陷阱 (maze[i][j], 1<=i<=n,1<=j<=m)
// 答案保证有解 即 maze[1][1] = 0, maze[n][m] = 0, 起点与终点之间保证至少存在一条路径
int maze[maxn+5][maxn+5];
// 奖励函数R 设置普通格子奖励为-(abs(i-n)+abs(j-m)) 陷阱奖励为-10000 终点奖励为100000 衰减因子alpha = 0.9 , gama = 0.9
const double alpha = 0.9;
const double gama = 0.9;
double Reward[maxn+5][maxn+5];
// 状态函数Q 下一步的选取采用1-ϵ贪心
// 关于Qstate[pos]中的pos索引到二维坐标(px,py)的转换:
// px = (pos - 1) / m + 1
// py = (pos - (px-1) * m) % (m+1);
const double greedy_factor = 0.1;
vector< pair<int,double> > Qstate[(maxn+5)*(maxn+5)];
// 存储答案
vector< pair<int,int> > ans;
// 初始化奖励函数R和状态函数Q
void init_RQ(int i,int j)
{
// 陷阱不设置奖励函数(可理解成均为-inf)
if (maze[i][j] == 1) return;
// Up
if (Reward[i-1][j]) {
Qstate[(i-1)*m+j].push_back({
(i-2)*m+j,-1});
}
// Left
if (Reward[i][j-1]) {
Qstate[(i-1)*m+j].push_back({
(i-1)*m+j-1,-1});
}
// Right
if (Reward[i][j+1]) {
Qstate[(i-1)*m+j].push_back({
(i-1)*m+j+1,-1});
}
// Down
if (Reward[i+1][j]) {
Qstate[(i-1)*m+j].push_back({
i*m+j,-1});
}
}
int success_time = 0;
bool isEnd(int i,int j)
{
if (i == n && j == m) {
++success_time;
return true;
}
if (maze[i][j] == 1) {
return true;
}
return false;
}
void Qlearning()
{
int nx = 1 + rand() % n, ny = 1 + rand() % m;
int cnt = 0;
while (!isEnd(nx,ny) && cnt < n*m) {
auto &s0 = Qstate[(nx-1)*m+ny];
int siz = s0.size();
int _next = -1,idx = 0;
if (!siz) return;
if (siz == 1) _next = s0[0].first;
else {
sort(s0.begin(),s0.end(),cmp);
double p = rand() / double(RAND_MAX);
if (p < 1 - greedy_factor) {
_next = s0[0].first;
}
else {
idx = 1 + rand() % (siz - 1);
_next = s0[idx].first;
}
}
auto &s1 = Qstate[_next];
sort(s1.begin(),s1.end(),cmp);
double _nextMax = (int)s1.size() ? s1[0].second : 0.0;
nx = (_next - 1) / m + 1;ny = (_next - (nx-1) * m) % (m+1);
/********/
// TODO
// HINTS: 使用s0[idx].second、alpha、gama、_nextMax、Reward[nx][ny]变量,
// 完成Qlearning的状态更新公式
// 你的代码将被嵌在此处
/********/
cnt++;
}
}
int main()
{
ios::sync_with_stdio(false);
srand(2022);
cin >> n >> m;
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= m; j++) {
int t;
cin >> t;
maze[i][j] = t;
Reward[i][j] = (t == 0 ? -(abs(i-n)+abs(j-m)) : -10000.0);
}
}
Reward[n][m] = 100000.0;
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
init_RQ(i,j);
}
}
int cnt = 0;
while (cnt < epics && success_time != target_success) {
Qlearning();
++cnt;
}
cnt = 0;
int x = 1, y = 1;
while ((x!=n || y!=m) && cnt < n*m) {
auto &s = Qstate[(x-1)*m+y];
if (!(int)s.size()) {
// 无解情况,可忽略
cout << "Something Wrong!" << endl;
return 0;
}
ans.push_back({
x,y});
sort(s.begin(),s.end(),cmp);
int _next = s[0].first;
x = (_next - 1) / m + 1; y = (_next - (x-1) * m) % (m+1);
++cnt;
}
ans.push_back({
n,m});
cout << (int)ans.size() << endl;
for(auto& u : ans) {
cout << u.first << ' ' << u.second << endl;
}
return 0;
}
思路
搞清楚每个部分干啥套公式即可
代码
double former = (1 - alpha) * s0[idx].second;
double later = alpha * (Reward[nx][ny] + gama * _nextMax);
s0[idx].second = former + later;
智能推荐
Elasticsearch Scripting脚本使用总结_elasticsearch 脚本script-程序员宅基地
文章浏览阅读3.4k次,点赞5次,收藏10次。目录一、概述二、Scripting脚本使用一、概述Elasticsearch提供的增删改查相关API虽然能解决大部分业务场景的问题,但是在一些相对复杂的业务场景,使用增删改查不太好实现的时候,此时就需要借助Elasticsearch脚本进行实现,Elasticsearch脚本可以帮助我们解决复杂业务问题,如:自定义评分、自定义文本相关度、自定义过滤、自定义聚合分析等。首先了解一下Scripting 使用语法:"script": { "lang": "...", // _elasticsearch 脚本script
java有什么岗位_java开发有哪些岗位?相关岗位及工作职责-程序员宅基地
文章浏览阅读1.2w次,点赞2次,收藏15次。Java是所有编程语言排名第一的语言,受众范围非常广,大家学习了java之后,就可以出去找工作,那么java开发有哪些相关岗位呢?接下来我们就来给大家讲解一下相关岗位及工作职责。一、JAVA开发工程师1. 协助团队负责人,按照产品功能需求和任务进度要求,完成指派的研发与运维工作;2. 负责具体功能模块的需求分析、设计及编码实现;3. 遵守技术规范,保障代码质量;4. 负责系统运维的日常技术支持与快..._与java相关的岗位
SQL语言的四大组成部分——DCL(数据控制语言)-程序员宅基地
文章浏览阅读1.3w次,点赞132次,收藏154次。DCL语言是SQL语言中非常重要的一个部分,它可以帮助数据库管理员控制用户对数据库的访问权限,保证数据库中数据的安全性和完整性。_dcl
log_checkpoint_interval和log_checkpoint_timeout-程序员宅基地
文章浏览阅读1.3k次。9i以后可能大家都喜欢通过设置fast_start_mttr_target来控制instance recovery的粒度。但是仍然有两个参数一直影响着我们的checkpoint,就是log_checkpoint_interval和log_checkpoint_timeout log_checkpoint_intervalOracle8.1版本后log_checkpoint_in..._log_checkpoint_interval
unity3d事件函数整理,事件,回调函数,消息处理_unity3d 客户端停止运行有没事件通知-程序员宅基地
文章浏览阅读4.8k次。Unity3D中所有控制脚本的基类MonoBehaviour有一些虚函数用于绘制中事件的回调,也可以直接理解为事件函数,例如大家都很清楚的Start,Update等函数,以下做个总结。Awake当前控制脚本实例被装载的时候调用。一般用于初始化整个实例使用。Start当前控制脚本第一次执行Update之前调用。Update每帧都执行一次。这是最常用的事件函数。Fi_unity3d 客户端停止运行有没事件通知
(狼人杀,骑士飞行棋,歹徒逃亡)_"jue_se[1].name = \"普通人 \"; jue_se[2].name = \"坏人 -程序员宅基地
文章浏览阅读85次。在济宁市任城区的五年级的小学生2022/9/3_"jue_se[1].name = \"普通人 \"; jue_se[2].name = \"坏人 \"; jue_se[3].name = \"医生"
随便推点
vue-print设置页眉和页脚_掌握这5个Word页码设置技巧,写论文足够用了-程序员宅基地
文章浏览阅读3.6k次。1、每页添加一个文档双击页眉处,进入相应的编辑状态,将鼠标移到页脚处,点击设计——页眉和页脚——页码,插入合适的样式即可。PS:页码插入的方式还可以通过插入——页眉和页脚——页码方式来实现。2、第几页共几页如何将文档设置成第几页共几页的格式?点击插入——页码——选择第几页共几页的页码格式(即X/Y格式),之后选中页码按Shift+F9切换域代码,输入内容【第{PAGE}页/共{NUMPAGES}页..._v-print 设置页眉
云计算介绍-1.1,IaaS\PaaS\SaaS辨析_paas msb-程序员宅基地
文章浏览阅读6.4k次,点赞4次,收藏6次。云计算是个很神奇的词汇,神奇在一切基于WEB的应用似乎都可以套到云计算范围内。一个原因是:云计算几乎没有标准,因为大家都不清楚什么是云计算,大家觉得各种概念都像云计算,所以可以任意用,随意扩展云计算范围。作为一个研发人员,我希望从底层实现来了解云计算的实质。所以在介绍云计算时,我希望能够找到一种直观、容易理解、直接从底层实现而非商业模式入手 的介绍方法,这个突破口就是:1,计费模式,从中可以理解什么是按需购买,2,与旧技术对比(没有一种技术是凭空产生,大多数技术都是旧技术演进而来)。_paas msb
历年CSP-J(NOIP普及组)考点分析与分类汇总(纯干货)_cspj历年真题考点-程序员宅基地
文章浏览阅读2k次,点赞35次,收藏36次。noip/csp-j历年真题考点分类_cspj历年真题考点
idea报错-java file outside of source root_idea提示:java file outside of source-程序员宅基地
文章浏览阅读1.7w次,点赞25次,收藏15次。IntelliJ IDEA 工程Java文件上红色的无效符(红色表示该类是不可编译文件)在Java文件夹点击右键找到Mark Direc tory as -->Sources Root(告诉IntelliJ IDEA,Java文件夹及其子文件夹中包含的源代码,可以编译为构建过程的一部分)果然ok..._idea提示:java file outside of source
攻防世界--Web_php_unserialize_unserialize脚本-程序员宅基地
文章浏览阅读849次。攻防世界--Web_php_unserialize考点WP__wakeup的绕过正则表达式绕过PHP脚本和注意事项(重要)参考连接考点__wakeup魔术方法的绕过O:数字正则表达式的绕过php代码编写WP<?php class Demo { private $file = 'index.php'; public function __construct($file) { $this->file = $file; } fun_unserialize脚本
用户需求分析是什么?重难点是什么?_用户需求的主要困难有哪些-程序员宅基地
文章浏览阅读5.1k次。用户分析需要考虑以下几个方面的内容:第一:受众群体分析。用户需求分析的第一个内容是受众群体分析,通常来说,不同类型的产品往往都有明确的用户定位,通过受众群体的数据分析能够发现定位与实际运营之间的差距,从而调整运营策略。受众群体的数据分析越详细越好,因为受众群体往往关系到产品未来的发展速度和影响面。第二:功能利用率分析。功能利用率分析主要是体现产品的核心价值,通过功能利用率的分析可以直观的体现出..._用户需求的主要困难有哪些