cuda编程(一)基础-程序员宅基地
- 基于c/c++的编程方法
- 支持异构编程的扩展方法
- 简单明了的apis,能够轻松的管理存储系统
cuda支持的编程语言:c/c++/python/fortran/java…
1、CUDA并行计算基础
- 异构计算
- CUDA 安装
- CUDA 程序的编写
- CUDA 程序编译
- 利用NVProf查看程序执行情况
gpu不是单独的在计算机中完成任务,而是通过协助cpu和整个系统完成计算机任务,把一部分代码和更多的计算任务放到gpu上处理,逻辑控制、变量处理以及数据预处理等等放在cpu上处理。
host 指的是cpu和内存
device 指的是gpu和显存
nvidia-smi 查看当前gpu的运行状态
2、第一个cuda程序
系统中安装了cuda但是执行nvcc找不到命令。
添加环境变量。
vim ~/.bashrc
加入环境变量
export PATH="/usr/local/cuda-10.2/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH"
source ~/.bashrc
再次执行nvcc -V结果如下。

2.1 helloword
nvcc也可以支持纯c的代码,所以先写一个helloword的代码进行,使用nvcc进行编译!
cuda程序的编译器驱动nvcc支持编译纯粹的c++代码,一个标准的CUDA程序中既有C++代码也有不属于C++的cuda代码。cuda程序的编译器驱动nvcc在编译一个cuda程序时,会将纯粹的c++代码交给c++的编译器,他自己负责编译剩下的部分(cuda)代码。
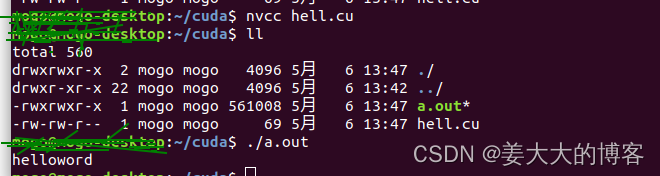
创建hell.cu文件,cuda的代码需要以cu为后缀结尾。
#include<stdio.h>
int main()
{
printf("helloword\n");
return 0;
}
~
nvcc hell.cu
./a.out
运行结果如下。
2.2 核函数
cuda 中的核函数与c++中的函数是类似的,cuda的核函数必须被限定词__global__修饰,核函数的返回类型必须是空类型,即void.
#include<stdio.h>
__global__ void hello_from_gpu()
{
printf("hello word from the gpu!\n");
}
int main()
{
hello_from_gpu<<<1,1>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
~
运行结果如下。

在核函数的调用格式上与普通C++的调用不同,调用核函数的函数名和()之间有一对三括号,里面有逗号隔开的两个数字。因为一个GPU中有很多计算核心,可以支持很多个线程。主机在调用一个核函数时,必须指明需要在设备中指派多少个线程,否则设备不知道怎么工作。三括号里面的数就是用来指明核函数中的线程数以及排列情况的。核函数中的线程常组织为若干线程块(thread block)。
三括号中的第一个数时线程块的个数,第二个数可以看作每个线程中的线程数。一个核函数的全部线程块构成一个网格,而线程块的个数记为网格大小,每个线程块中含有同样数目的线程,该数目称为线程块大小。所以核函数中的总的线程就等与网格大小乘以线程块大小,即<<<网格大小,线程块大小 >>>
核函数中的printf函数的使用方法和C++库中的printf函数的使用方法基本上是一样的,而在核函数中使用printf函数时也需要包含头文件<stdio.h>,核函数中不支持C++的iostream。
cudaDeviceSynchronize();这条语句调用了CUDA运行时的API函数,去掉这个函数就打印不出字符了。因为cuda调用输出函数时,输出流是先放在缓存区的,而这个缓存区不会核会自动刷新,只有程序遇到某种同步操作时缓存区才会刷新。这个函数的作用就是同步主机与设备,所以能够促进缓存区刷新。
3、cuda中的线程组织
3.1 使用多个线程的核函数
核函数中允许指派很多线程,一个GPU往往有几千个计算核心,而总的线程数必须至少等与计算核心数时才有可能充分利用GPU的全部计算资源。实际上,总的线程数大于计算核心数时才能更充分地利用GPU中的计算资源,因为这会让计算和内存访问之间及不同的计算之间合理地重叠,从而减小计算核心空闲的时间。
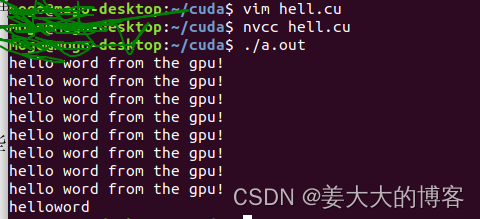
使用网格数为2,线程块大小为4的计算核心,所以总的线程数就是2x4=8,所以核函数的调用将指派8个线程完成。
核函数中的代码的执行方式是“单指令-多线程”,即每一个线程都执行同一指令的内容。
#include<stdio.h>
__global__ void hello_from_gpu()
{
printf("hello word from the gpu!\n");
}
int main()
{
hello_from_gpu<<<2,4>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
运行结果如下。
3.2 线程索引的使用
一个核函数可以指派多个线程,而这些线程的组织结构是由执行配置(<<<网格大小,线程块大小 >>>)来决定的,这是的网格大小和线程块大小一般来说是一个结构体类型的变量,也可以是一个普通的整形变量。
一个核函数允许指派的线程数是巨大的,能够满足几乎所有应用程序的要求。但是一个核函数中虽然可以指派如此巨大数目的线程数,但在执行时能够同时活跃(不活跃的线程处于等待状态)的线程数是由硬件(主要是CUDA核心数)和软件(核函数的函数体)决定的。
每个线程在核函数中都有一个唯一的身份标识。由于我们在三括号中使用了两个参数制定了线程的数目,所以线程的身份可以由两个参数确定。在程序内部,程序是知道执行配置参数grid_size和block_size的值的,这两个值分别保存在内建变量(built-in vari-
able)中。
gridDim.x :该变量的数值等与执行配置中变量grid_size的数值。
blockDim.x: 该变量的数值等与执行配置中变量block_size的数值。
在核函数中预定义了如下标识线程的内建变量:
blockIdx.x :该变量指定一个线程在一个网格中的线程块指标。其取值范围是从0到gridDim.x-1
threadIdx.x:该变量指定一个线程在一个线程块中的线程指标,其取值范围是从0到blockDim.x-1
代码如下。
#include<stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("hello word from block %d and thread %d\n",bid,tid);
}
int main()
{
hello_from_gpu<<<2,4>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
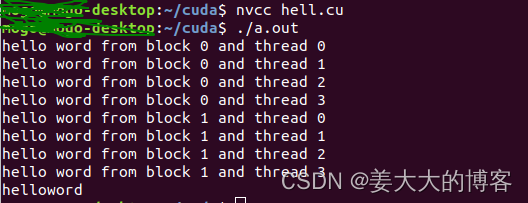
有时候线程块的顺序会发生改变,有时候是第1个先执行有时候是第0个先执行,这说明了cuda程序执行时每个线程块的计算都是相互独立的,不管完成计算的次序如何,每个线程块中间的每个线程都进行一次计算。
3.3 cuda多维网格
上述四个内建变量都使用了C++中的结构体或者类的成员变量的语法,其中blockIdx和threadIdx是类型为uint3的变量,该类型是一个结构体,具有x,y,z三个成员变量。所以blockIdx只是三个成员中的一个,threadIdx也有xyz三个成员变量。结构体uint3在头文件vector_types.h中定义有。
 同样的gridDim和blockDim是dim3类型的变量。也有xyz三个成员变量。
同样的gridDim和blockDim是dim3类型的变量。也有xyz三个成员变量。
在前面三括号内的网格大小和线程块大小都是通过一维表示,可以通过dim3定义多维网格和线程块,通过C++的构造函数的方法实现。di3 grid_size(Gx.Gy,Gz);
如果第三个维度是1,可以省去不写。
多维的网格和线程块本质上还是一维的,就像多维数组本质上也是一维数组一样。一个多维线程指标threadIdx.x、threadIdx.y、threadIdx.z对应的一维指标为。
int tid = threadIdx.z * blockDim.x * blockDim.y +threadIdx.y * blockDim.x + threadIdx.x;
也就是说,x维度是最内层的变化最快的,而z维度是最外层的变化最满的。
代码如下。
#include<stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int yid = threadIdx.y;
printf("hello word from block %d and thread (%d,%d)\n",bid,tid,yid);
}
int main()
{
const dim3 block_size(2,4);
hello_from_gpu<<<1,block_size>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
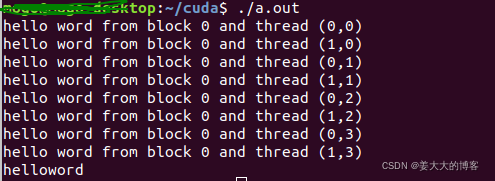
因为线程块的大小是2*4,所以在核函数中,blockDim.x的值为2,blokcDim.y值是4,threadIdx.x的取值是0到1,threadIdx.y的取值是0到3。
从结果可以看到。x维度是变量最快的是最内层的,是因为结果中,前两行的x层发生了0-1的转变,但是y层依然表示0。
3.3 网格与线程块大小的限制
cuda中对能够定义的网格大小和线程块大小做了限制,一个线程块最多只能有1024个线程。
4 cuda中的头文件
cuda有自己的头文件,但是在使用nvcc编译器驱动.cu文件时,将自动包含必要的cuda头文件,如<cuda.h>个和<cuda_runtime.h>。因为<cuda.h>包含了<stdlib.h>,所以在使用nvcc编译的cuda程序也不需要包含stdlib头文件。
5 nvcc编译cuda程序
cuda的编译器驱动nvcc会先将全部源代码分离为主机代码和设备代码。设备代码完全支持C++语法,但设备代码只部分地支持C++。nvcc先将设备代码编译为PTX伪汇编代码,再将PTX代码编译为二进制的文件cubin目标代码。在将源代码编译为PTX代码时,需要用选项-arch=compute_XY指定一个虚拟架构的计算能力,用以确定代码中共能够使用的cuda功能。在将PTX代码编译为cubin代码时,需要用选项-code=sm_ZW指定一个真实架构的计算能力,用以确定可执行文件能够使用的GPU。真实架构的计算能力必须等与或者大于虚拟架构的计算能力。
智能推荐
GoLang音视频转码_go 图片 视频转码-程序员宅基地
文章浏览阅读3.5k次。一、搭建好开发环境这一步不会的可以百度参考一下这个教程https://www.runoob.com/go/go-environment.html安装ide ,我用的是goland, 个人感觉比较好用支持的平台Linux OS X Windows二、下载第三方工具包go get github.com/xfrr/goffmpeg三、音频转码程序可以直接运行。并且同时支持音频和视频的播放提供的例子是将m4a转码成mp3格式。如果想转换其他格式,只需要修改文件后缀名._go 图片 视频转码
MPC5744P-eTimer模块-程序员宅基地
文章浏览阅读4.5k次,点赞9次,收藏32次。1.通道结构5744每个eTimer模块含有6个相同的计数通道,每个计数通道含有16位计数器、分频器、保持寄存器各一个,捕捉寄存器、比较寄存器、比较预加载寄存器各两个,还有四个控制寄存器,其通道结构如下图:2、计数模式、eTimer模块含有多种计数模式,可根据实际情况选择合适的计数模式1、计数上升沿;2、计数跳边沿(上升沿和下降沿均计数);3、当二次输入为高时计数;4、QUADRA..._etimer
Hexo折腾之改用Valine评论系统 - 更新域名绑定,评论后台管理_hexo评论valine-程序员宅基地
文章浏览阅读2k次,点赞11次,收藏9次。前几天给博客添加了来必力评论系统,但是加载速度实在是慢的可以,原因是来必力是在页面滑到底部的时候才开始加载,但是通过控制台看,来必力确实时间很久,很影响我自己的使用体验(嗯,没有别人,哭),所以在网上找到了另外的评论系统—Valine。Valine 是什么?欢迎访问 Valine 官网Valine 是一款基于 Leancloud 的快速、简洁且高效的无后端评论系统。Valine 的特性如同官网所说:快速、安全、无后端等等。更重要的是,我在 Valine 官网看到了「邮件提醒」,巧了,这正是我想要_hexo评论valine
七牛云存储的简单使用总结_7牛 s3存储的使用-程序员宅基地
文章浏览阅读1.1w次。七牛是专注文件存储的第三方服务商,服务较好。自己最近做到服务器存储图片的时候就想到用七牛来做,将图片或者文件存放在七牛,然后自己服务器只存放资源存放在七牛文件的url。今天主要分享两个内容:凭证的获取,安卓上传文件在做之前还是先把官方文档好好读几遍比较好首先说说凭证,七牛对所有上传的资源都需要身份验证,就是通过凭证来验证,验证通过,那么就可以成功上传文件,不通过,七牛服务器会反_7牛 s3存储的使用
Windows10 -64 安装tensorflow遇到的:cuda安装后找不到安装文件目录_没有nvidia gpu computing toolkit文件夹-程序员宅基地
文章浏览阅读3w次,点赞32次,收藏114次。Windows10 -64 安装tensorflow遇到的:cuda安装后找不到安装文件目录目录 一、错误:cuda安装后找不到安装文件目录二、查看cuda驱动程序的版本三、补充内容四、执行测试程序出错五、常用命令总结 一、错误:cuda安装后找不到安装文件目录原因是:将临时解压目录和安装目录设置成一样的了,导致安装结束,临时解压目录被删除,所以安装目录也被删除了;..._没有nvidia gpu computing toolkit文件夹
Memcache内部剖析_memcache 架构分析-程序员宅基地
文章浏览阅读1.1k次。本文主要对memcache内部Big-O、LRU算法、内存分配(Memory allocation)、一致性哈希(Consistent hashing)等进行了深入剖析,并举例生动形象描述了一致性哈希算法_memcache 架构分析
随便推点
仿射密码解密(Affine Cipher)-程序员宅基地
文章浏览阅读4.9w次,点赞38次,收藏105次。仿射密码是一种表单代换密码,字母表的每个字母相应的值使用一个简单的数学函数对应一个数值,再把对应数值转换成字母。A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 ..._仿射密码
《Java基础入门第2版》--黑马程序员 课后答案及其详解 第1章 Java开发入门_java基础入门黑马程序员第二版-程序员宅基地
文章浏览阅读3.8w次,点赞116次,收藏425次。文章目录一、填空题二、判断题三、选择题四、简答题五、编程题六、原题及其解析一、填空题1.(1)Java SE(2)Java EE(3)Java ME2.JRE3.javac4.bin5.(1)path(2)classpath二、判断题 1.√ 2.× 3.√ 4.√ 5.×三、选择题 1.ABCD 2.C 3.D 4.B 5.B四、简答题1、 面向对象、跨平台性、健壮性、安全性、可移植性、多线程性、动态性等。2、 JRE(Java Runtime Environm._java基础入门黑马程序员第二版
OpenGL基础知识介绍和简单使用_opengl program-程序员宅基地
文章浏览阅读4.5k次,点赞3次,收藏41次。OpenGL(全写Open Graphics Library)是指定义了一个跨编程语言、跨平台的编程接口规格的专业的图形程序接口。它用于三维图像(二维的亦可),是一个功能强大,调用方便的底层图形库。OpenGL在不同的平台上有不同的实现,但是它定义好了专业的程序接口,不同的平台都是遵照该接口来进行实现的,思想完全相同,方法名也是一致的,所以使用时也基本一致,只需要根据不同的语言环境稍有不同而已。_opengl program
【51单片机】之入门详解(一)_51单片机编程入门基础知识-程序员宅基地
文章浏览阅读1.2k次,点赞21次,收藏19次。【51单片机】之入门详解(一)_51单片机编程入门基础知识
uwsgi的3个容易掉坑的配置(timeout、harakiri、buffer-size)_uwsgi harakiri-程序员宅基地
文章浏览阅读2.9w次,点赞16次,收藏27次。我采用的.ini文件[uwsgi]master = truewsgi-file=myppt/wsgi.pyprocesses = 1threads = 2chdir = /www/wwwroot/ppt_jpg/myppt/http = 127.0.0.1:9876virtualenv=/www/wwwroot/ppt_jpg/myppt/ppt_venvdaemonize=uw..._uwsgi harakiri
ffmpeg5.0+h264+h265 windows下编译方法-程序员宅基地
文章浏览阅读7.4k次,点赞14次,收藏47次。前言: 最近准备在windows上面用ffmpeg做视频编解码工作,找了很多博客对编译方法描述都不全,花了一天时间自己折腾编译通过了,写篇比较完整的博客分享给大家,希望对大家有所帮助,另外,感谢其他博主的分享!一,源码包下载1.ffmpeg下载下载地址:https://ffmpeg.org(1)在主页面中找到ffmpeg5.0版本点击(2)点击下载,这里我下载的是gzip包2,下载x264代码下载地址:x264, the best H.2..._ffmpeg5.0