java面试(持续更新),java程序员面试算法宝典pdf猿媛之家-程序员宅基地
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
1.AspectJ
2.Spring AOP
3.JBoss AOP
在维基百科上你可以找到一个AOP实现的大列表。
4.Spring中有哪些不同的通知类型
通知(advice)是你在你的程序中想要应用在其他模块中的横切关注点的实现。Advice主要有以下5种类型:
1.前置通知(Before Advice): 在连接点之前执行的Advice,不过除非它抛出异常,否则没有能力中断执行流。使用 @Before 注解使用这个Advice。
2.返回之后通知(After Retuning Advice): 在连接点正常结束之后执行的Advice。例如,如果一个方法没有抛出异常正常返回。通过 @AfterReturning 关注使用它。
3.抛出(异常)后执行通知(After Throwing Advice): 如果一个方法通过抛出异常来退出的话,这个Advice就会被执行。通用 @AfterThrowing 注解来使用。
4.后置通知(After Advice): 无论连接点是通过什么方式退出的(正常返回或者抛出异常)都会执行在结束后执行这些Advice。通过 @After 注解使用。
5.围绕通知(Around Advice): 围绕连接点执行的Advice,就你一个方法调用。这是最强大的Advice。通过 @Around 注解使用。
5.Spring AOP 代理是什么?
代理是使用非常广泛的设计模式。简单来说,代理是一个看其他像另一个对象的对象,但它添加了一些特殊的功能。
Spring AOP是基于代理实现的。AOP 代理是一个由 AOP 框架创建的用于在运行时实现切面协议的对象。
Spring AOP默认为 AOP 代理使用标准的 JDK 动态代理。这使得任何接口(或者接口的集合)可以被代理。Spring AOP 也可以使用 CGLIB 代理。这对代理类而不是接口是必须的。
如果业务对象没有实现任何接口那么默认使用CGLIB。
6.引介(Introduction)是什么?
引介让一个切面可以声明被通知的对象实现了任何他们没有真正实现的额外接口,而且为这些对象提供接口的实现
使用 @DeclareParaents 注解来生成一个引介。
更多详情,请参考 官方文档
7.连接点(Joint Point)和切入点(Point cut)是什么?
连接点是程序执行的一个点。例如,一个方法的执行或者一个异常的处理。在 Spring AOP 中,一个连接点总是代表一个方法执行。举例来说,所有定义在你的 EmpoyeeManager 接口中的方法都可以被认为是一个连接点,如果你在这些方法上使用横切关注点的话。
切入点(切入点)是一个匹配连接点的断言或者表达式。Advice 与切入点表达式相关联,并在切入点匹配的任何连接点处运行(比如,表达式 execution(* EmployeeManager.getEmployeeById(…)) 可以匹配 EmployeeManager 接口的 getEmployeeById() )。由切入点表达式匹配的连接点的概念是 AOP 的核心。Spring 默认使用 AspectJ 切入点表达式语言。
8.什么是织入(weaving)?
Spring AOP 框架仅支持有限的几个 AspectJ 切入点的类型,它允许将切面运用到在 IoC 容器中声明的 bean 上。如果你想使用额外的切入点类型或者将切面应用到在 Spring IoC 容器外部创建的类,那么你必须在你的 Spring 程序中使用 AspectJ 框架,并且使用它的织入特性。
织入是将切面与外部的应用类型或者类连接起来以创建通知对象(adviced object)的过程。这可以在编译时(比如使用 AspectJ 编译器)、加载时或者运行时完成。Spring AOP 跟其他纯 Java AOP 框架一样,只在运行时执行织入。在协议上,AspectJ 框架支持编译时和加载时织入。
AspectJ 编译时织入是通过一个叫做 ajc 特殊的 AspectJ 编译器完成的。它可以将切面织入到你的 Java 源码文件中,然后输出织入后的二进制 class 文件。它也可以将切面织入你的编译后的 class 文件或者 Jar 文件。这个过程叫做后编译时织入(post-compile-time weaving)。在 Spring IoC 容器中声明你的类之前,你可以为它们运行编译时和后编译时织入。Spring 完全没有被包含到织入的过程中。更多关于编译时和后编译时织入的信息,请查阅 AspectJ 文档。
AspectJ 加载时织入(load-time weaving, LTW)在目标类被类加载器加载到JVM时触发。对于一个被织入的对象,需要一个特殊的类加载器来增强目标类的字节码。AspectJ 和 Spring 都提供了加载时织入器以为类加载添加加载时织入的能力。你只需要简单的配置就可以打开这个加载时织入器。
9.Spring怎样解决循环依赖的问题
引言:循环依赖就是N个类中循环嵌套引用,如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错。下面说一下Spring是如果解决循环依赖的。
第一种:构造器参数循环依赖
表示通过构造器注入构成的循环依赖,此依赖是无法解决的,只能抛出BeanCurrentlyIn CreationException异常表示循环依赖。
如在创建TestA类时,构造器需要TestB类,那将去创建TestB,在创建TestB类时又发现需要TestC类,则又去创建TestC,最终在创建TestC时发现又需要TestA,从而形成一个环,没办法创建。
Spring容器会将每一个正在创建的Bean 标识符放在一个“当前创建Bean池”中,Bean标识符在创建过程中将一直保持
在这个池中,因此如果在创建Bean过程中发现自己已经在“当前创建Bean池”里时将抛出
BeanCurrentlyInCreationException异常表示循环依赖;而对于创建完毕的Bean将从“当前创建Bean池”中清除掉。
首先我们先初始化三个Bean。
```java
public class StudentA {
private StudentB studentB ;
public void setStudentB(StudentB studentB) {
this.studentB = studentB;
}
public StudentA() {
}
public StudentA(StudentB studentB) {
this.studentB = studentB;
}
}
public class StudentB {
private StudentC studentC ;
public void setStudentC(StudentC studentC) {
this.studentC = studentC;
}
public StudentB() {
}
public StudentB(StudentC studentC) {
this.studentC = studentC;
}
}
public class StudentC {
private StudentA studentA ;
public void setStudentA(StudentA studentA) {
this.studentA = studentA;
}
public StudentC() {
}
public StudentC(StudentA studentA) {
this.studentA = studentA;
}
}
OK,上面是很基本的3个类,,StudentA有参构造是StudentB。StudentB的有参构造是StudentC,StudentC的有参构造是StudentA ,这样就产生了一个循环依赖的情况,我们都把这三个Bean交给Spring管理,并用有参构造实例化
```java
<bean id="a" class="com.zfx.student.StudentA">
<constructor-arg index="0" ref="b"></constructor-arg>
</bean>
<bean id="b" class="com.zfx.student.StudentB">
<constructor-arg index="0" ref="c"></constructor-arg>
</bean>
<bean id="c" class="com.zfx.student.StudentC">
<constructor-arg index="0" ref="a"></constructor-arg>
</bean>
下面是测试类:
public class Test {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("com/zfx/student/applicationContext.xml");
//System.out.println(context.getBean("a", StudentA.class));
}
}
执行结果报错信息为:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException:
Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
如果大家理解开头那句话的话,这个报错应该不惊讶,Spring容器先创建单例StudentA,StudentA依赖StudentB,然后将A放在“当前创建Bean池”中,此时创建StudentB,StudentB依赖StudentC ,然后将B放在“当前创建Bean池”中,此时创建StudentC,StudentC又依赖StudentA, 但是,此时Student已经在池中,所以会报错,,因为在池中的Bean都是未初始化完的,所以会依赖错误 ,(初始化完的Bean会从池中移除)
第二种:setter方式单例,默认方式
如果要说setter方式注入的话,我们最好先看一张Spring中Bean实例化的图
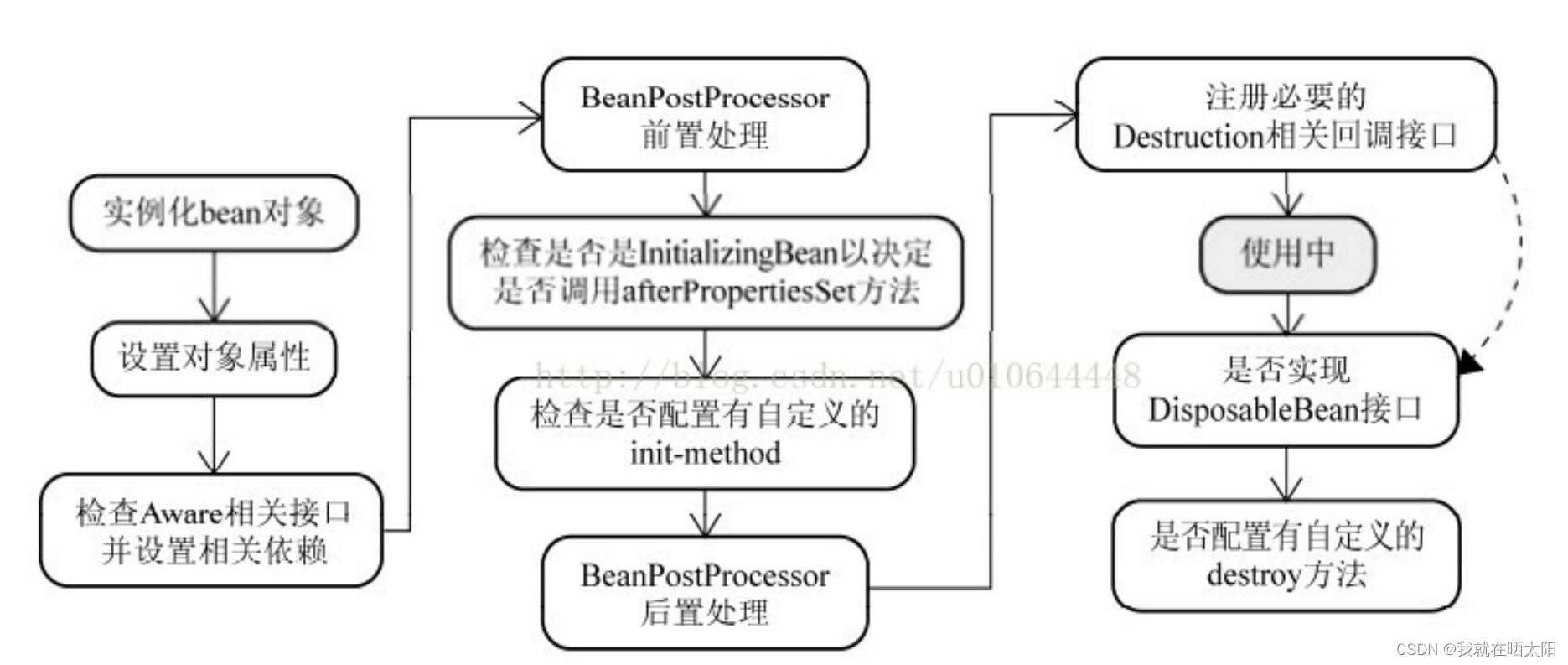
如图中前两步骤得知:Spring是先将Bean对象实例化之后再设置对象属性的
修改配置文件为set方式注入
<!--scope="singleton"(默认就是单例方式) -->
<bean id="a" class="com.zfx.student.StudentA" scope="singleton">
<property name="studentB" ref="b"></property>
</bean>
<bean id="b" class="com.zfx.student.StudentB" scope="singleton">
<property name="studentC" ref="c"></property>
</bean>
<bean id="c" class="com.zfx.student.StudentC" scope="singleton">
<property name="studentA" ref="a"></property>
</bean>
下面是测试类:
public class Test {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("com/zfx/student/applicationContext.xml");
System.out.println(context.getBean("a", StudentA.class));
}
}
打印结果为:
com.zfx.student.StudentA@1fbfd6
为什么用set方式就不报错了呢 ?
我们结合上面那张图看,Spring先是用构造实例化Bean对象 ,此时Spring会将这个实例化结束的对象放到一个Map中,并且Spring提供了获取这个未设置属性的实例化对象引用的方法。 结合我们的实例来看,,当Spring实例化了StudentA、StudentB、StudentC后,紧接着会去设置对象的属性,此时StudentA依赖StudentB,就会去Map中取出存在里面的单例StudentB对象,以此类推,不会出来循环的问题喽、
下面是Spring源码中的实现方法,。以下的源码在Spring的Bean包中的
DefaultSingletonBeanRegistry.java类中
/\*\* Cache of singleton objects: bean name --> bean instance(缓存单例实例化对象的Map集合) \*/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);
/\*\* Cache of singleton factories: bean name --> ObjectFactory(单例的工厂Bean缓存集合) \*/
private final Map<String, ObjectFactory> singletonFactories = new HashMap<String, ObjectFactory>(16);
/\*\* Cache of early singleton objects: bean name --> bean instance(早期的单身对象缓存集合) \*/
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
/\*\* Set of registered singletons, containing the bean names in registration order(单例的实例化对象名称集合) \*/
private final Set<String> registeredSingletons = new LinkedHashSet<String>(64);
/\*\*
\* 添加单例实例
\* 解决循环引用的问题
\* Add the given singleton factory for building the specified singleton
\* if necessary.
\* <p>To be called for eager registration of singletons, e.g. to be able to
\* resolve circular references.
\* @param beanName the name of the bean
\* @param singletonFactory the factory for the singleton object
\*/
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
第三种:setter方式原型,prototype
对于"prototype"作用域bean,Spring容器无法完成依赖注入,因为Spring容器不进行缓存"prototype"作用域的bean,因此无法提前暴露一个创建中的bean。
修改配置文件为:
<bean id="a" class="com.zfx.student.StudentA" <span style="color:#FF0000;">scope="prototype"</span>>
<property name="studentB" ref="b"></property>
</bean>
<bean id="b" class="com.zfx.student.StudentB" <span style="color:#FF0000;">scope="prototype"</span>>
<property name="studentC" ref="c"></property>
</bean>
<bean id="c" class="com.zfx.student.StudentC" <span style="color:#FF0000;">scope="prototype"</span>>
<property name="studentA" ref="a"></property>
</bean>
scope=“prototype” 意思是 每次请求都会创建一个实例对象。两者的区别是:有状态的bean都使用Prototype作用域,无状态的一般都使用singleton单例作用域。
测试用例:
public class Test {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("com/zfx/student/applicationContext.xml");
<strong>//此时必须要获取Spring管理的实例,因为现在scope="prototype" 只有请求获取的时候才会实例化对象</strong>
System.out.println(context.getBean("a", StudentA.class));
}
}
打印结果:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException:
Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
为什么原型模式就报错了呢 ?
对于“prototype”作用域Bean,Spring容器无法完成依赖注入,因为“prototype”作用域的Bean,Spring容器不进行缓存,因此无法提前暴露一个创建中的Bean。
GC
1.什么是GC?
大白话说就是垃圾回收机制,内存空间是有限的,你创建的每个对象和变量都会占据内存,gc做的就是对象清除将内存释放出来,这就是GC要做的事。
2.需要GC的区域
说起垃圾回收的场所,了解过JVM(Java Virtual Machine Model)内存模型的朋友应该会很清楚,堆是Java虚拟机进行垃圾回收的主要场所,其次要场所是方法区。
3.堆内存的结构(1.7)
在JDK1.8之后,堆的永久区取消了
由元空间取代
Java将堆内存分为3大部分:新生代、老年代和永久代,其中新生代又进一步划分为Eden、S0、S1(Survivor)三个区
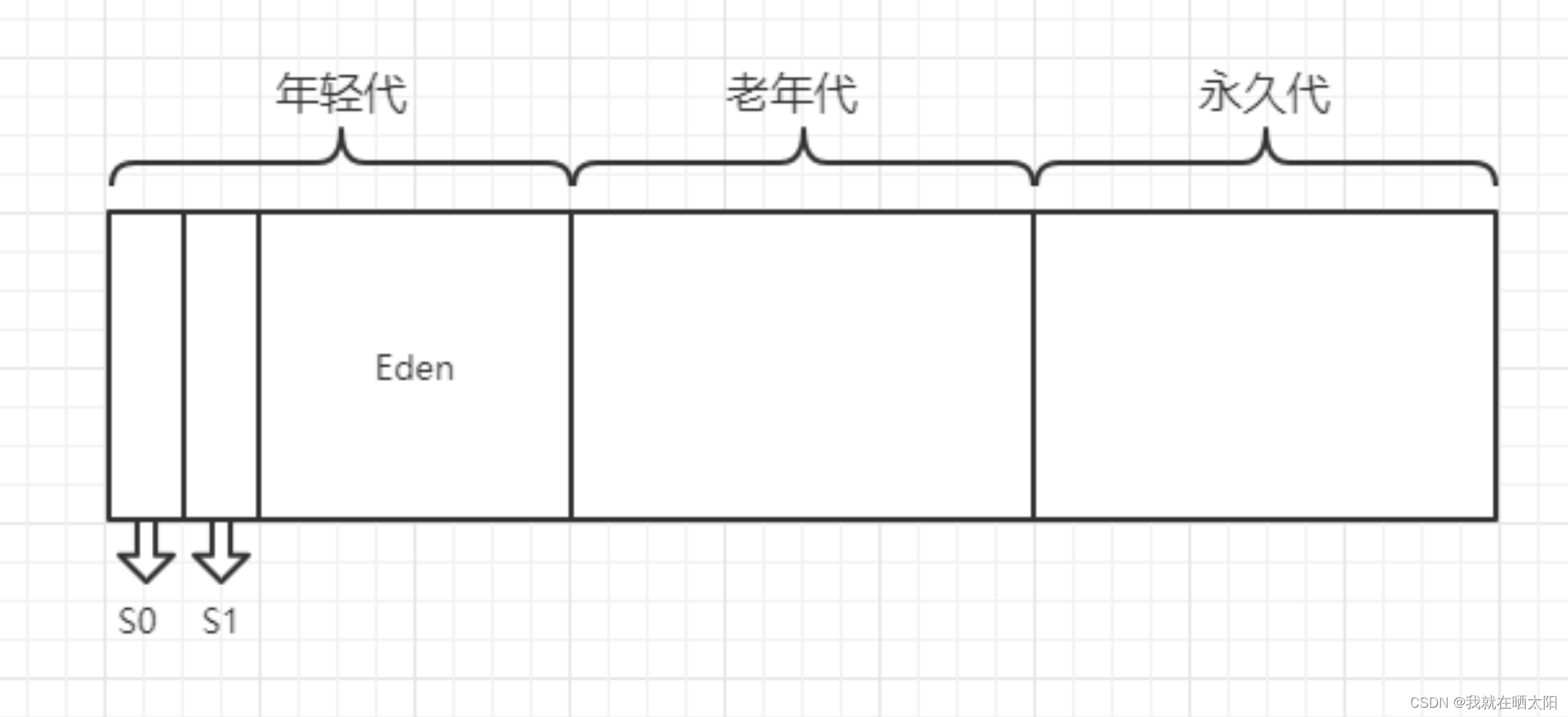
4.堆内存上对象的分配与回收:
我们创建的对象会优先在Eden分配,如果是大对象(很长的字符串数组)则可以直接进入老年代。虚拟机提供一个-XX:PretenureSizeThreadhold参数,令大于这个参数值的对象直接在老年代中分配,避免在Eden区和两个Survivor区发生大量的内存拷贝。
另外,长期存活的对象将进入老年代,每一次MinorGC(年轻代GC),对象年龄就大一岁,默认15岁晋升到老年代,通过-XX:MaxTenuringThreshold设置晋升年龄。
堆内存上的对象回收也叫做垃圾回收,那么垃圾回收什么时候开始呢?
垃圾回收主要是完成清理对象,整理内存的工作。上面说到GC经常发生的区域是堆区,堆区还可以细分为新生代、老年代。新生代还分为一个Eden区和两个Survivor区。垃圾回收分为年轻代区域发生的Minor GC和老年代区域发生的Full GC,分别介绍如下。
Minor GC(年轻代GC):
对象优先在Eden中分配,当Eden中没有足够空间时,虚拟机将发生一次Minor GC,因为Java大多数对象都是朝生夕灭,所以Minor GC非常频繁,而且速度也很快。
Full GC(老年代GC):
Full GC是指发生在老年代的GC,当老年代没有足够的空间时即发生Full GC,发生Full GC一般都会有一次Minor GC。
MinorGC和FullGC的触发条件
动态对象年龄判定:
如果Survivor空间中相同年龄所有对象的大小总和大于Survivor空间的一半,那么年龄大于等于该对象年龄的对象即可晋升到老年代,不必要等到-XX:MaxTenuringThreshold。
空间分配担保:
发生Minor GC时,虚拟机会检测之前每次晋升到老年代的平均大小是否大于老年代的剩余空间大小。如果大于,则进行一次Full GC(老年代GC),如果小于,则查看HandlePromotionFailure设置是否允许担保失败,如果允许,那只会进行一次Minor GC,如果不允许,则改为进行一次Full GC。
5.目前会问到的问题
1.年轻代三个区比例
Eden,S0,S1比例8:1:1
2.为什么要有Survivor区
为什么需要Survivor空间。我们看看如果没有 Survivor 空间的话,垃圾收集将会怎样进行:一遍新生代 gc 过后,不管三七二十一,活着的对象全部进入老年代,即便它在接下来的几次 gc 过程中极有可能被回收掉。这样的话老年代很快被填满, Full GC 的频率大大增加。我们知道,老年代一般都会被规划成比新生代大很多,对它进行垃圾收集会消耗比较长的时间;如果收集的频率又很快的话,那就更糟糕了。基于这种考虑,虚拟机引进了“幸存区”的概念:如果对象在某次新生代 gc 之后任然存活,让它暂时进入幸存区;以后每熬过一次 gc ,让对象的年龄+1,直到其年龄达到某个设定的值(比如15岁), JVM 认为它很有可能是个“老不死的”对象,再呆在幸存区没有必要(而且老是在两个幸存区之间反复地复制也需要消耗资源),才会把它转移到老年代。
Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
3.为什么有两个Survivor区
为什么 Survivor 分区不能是 1 个?
如果 Survivor 分区是 1 个的话,假设我们把两个区域分为 1:1,那么任何时候都有一半的内存空间是闲置的,显然空间利用率太低不是最佳的方案。
但如果设置内存空间的比例是 8:2 ,只是看起来似乎“很好”,假设新生代的内存为 100 MB( Survivor 大小为 20 MB ),现在有 70 MB 对象进行垃圾回收之后,剩余活跃的对象为 15 MB 进入 Survivor 区,这个时候新生代可用的内存空间只剩了 5 MB,这样很快又要进行垃圾回收操作,显然这种垃圾回收器最大的问题就在于,需要频繁进行垃圾回收。
为什么 Survivor 分区是 2 个?
刚刚新建的对象在Eden中,经历一次Minor GC,Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;等Eden区再满了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生)。S0和Eden被清空,然后下一轮S0与S1交换角色,如此循环往复。如果对象的复制次数达到16次,该对象就会被送到老年代中。下图中每部分的意义和上一张图一样,就不加注释了。
上述机制最大的好处就是,整个过程中,永远有一个survivor space是空的,另一个非空的survivor space无碎片。
那么,Survivor为什么不分更多块呢?比方说分成三个、四个、五个?显然,如果Survivor区再细分下去,每一块的空间就会比较小,很容易导致Survivor区满
总结
根据上面的分析可以得知,当新生代的 Survivor 分区为 2 个的时候,不论是空间利用率还是程序运行的效率都是最优的,所以这也是为什么 Survivor 分区是 2 个的原因了。
6. JVM如何判定一个对象是否应该被回收?(重点掌握)
判断一个对象是否应该被回收,主要是看其是否还有引用。判断对象是否存在引用关系的方法包括引用计数法以及可达性分析。
引用计数法:
是一种比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只需要收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
可达性分析:
可达性分析的基本思路就是通过一系列可以做为root的对象作为起始点,从这些节点开始向下搜索。当一个对象到root节点没有任何引用链接时,则证明此对象是可以被回收的。以下对象会被认为是root对象:
1)栈内存中引用的对象
2)方法区中静态引用和常量引用指向的对象
3)被启动类(bootstrap加载器)加载的类和创建的对象
4)Native方法中JNI引用的对象。
7. JVM垃圾回收算法有哪些?
HotSpot 虚拟机采用了可达性分析来进行内存回收,常见的回收算法有标记-清除算法,复制算法和标记整理算法。
标记-清除算法(Mark-Sweep):
标记-清除算法执行分两阶段。
第一阶段:从引用根节点开始标记所有被引用的对象,
第二阶段:遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,并且会产生内存碎片。

缺点:
1)执行效率不稳定,会因为对象数量增长,效率变低
2)标记清除后会有大量的不连续的内存碎片,空间碎片太多就会导致无法分配较大对象,无法找到足够大的连续内存,而发生gc
复制算法:
复制算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。复制算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
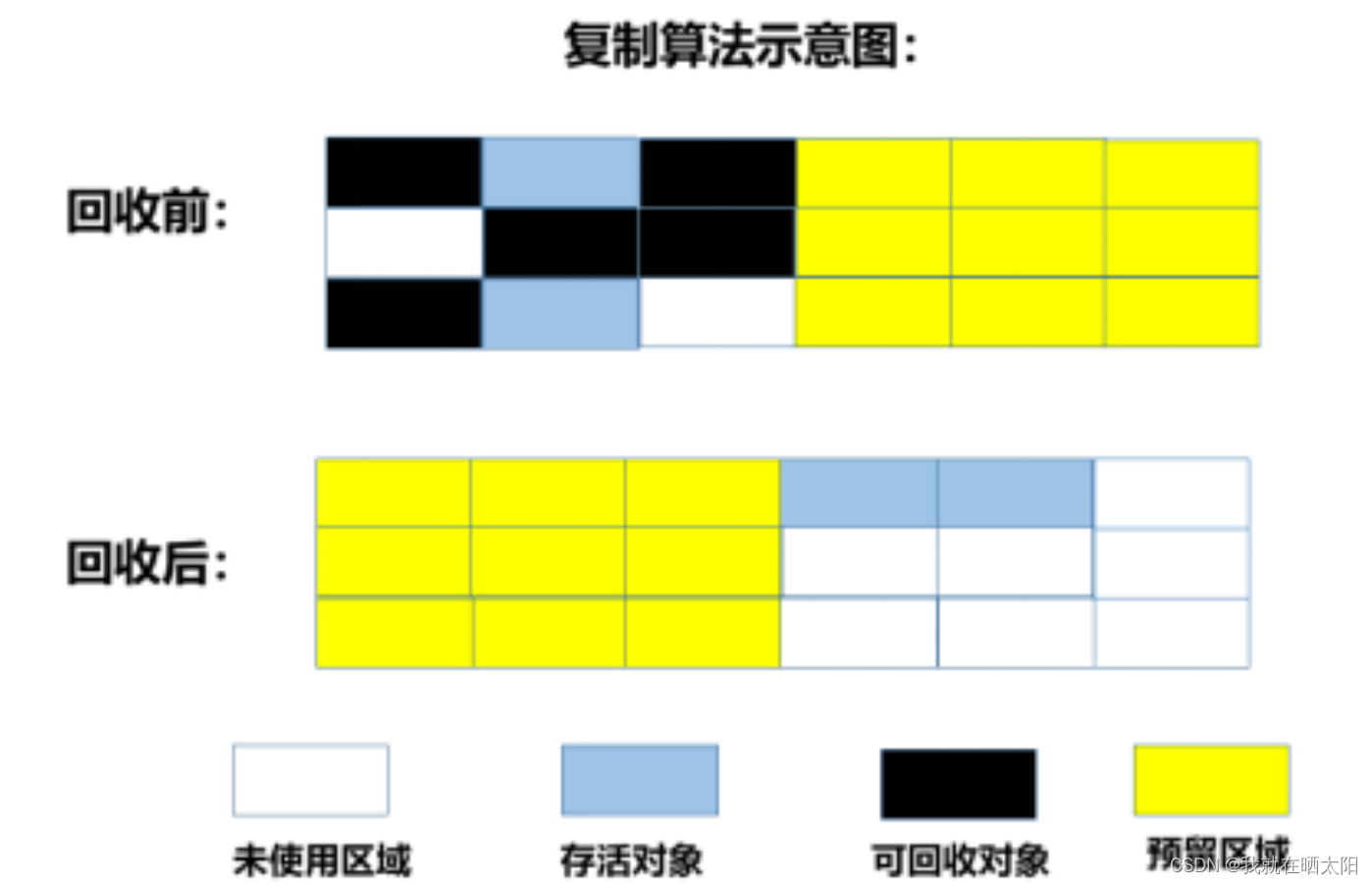
缺点:
1)可用内存缩成了一半,浪费空间
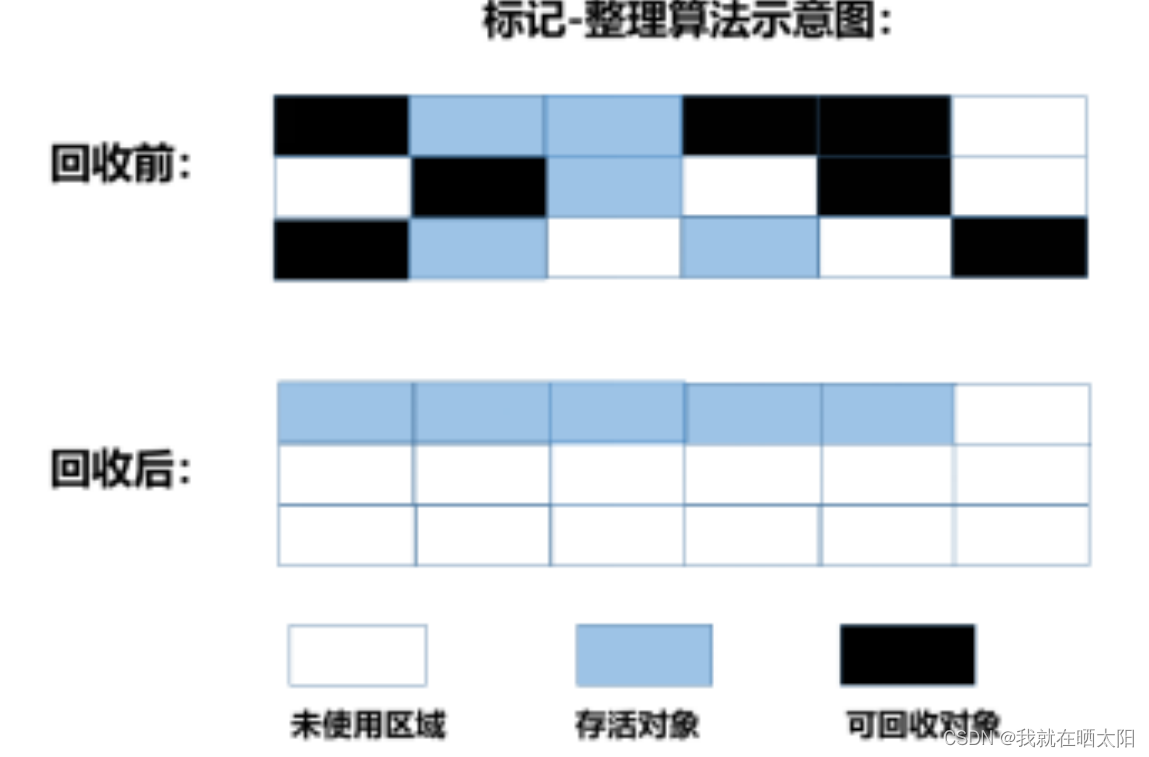
标记-整理算法:
标记-整理算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,
第一阶段从根节点开始标记所有被引用对象,
第二阶段遍历整个堆,清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
8.垃圾收集器(掌握CMS和G1)
JVM中的垃圾收集器主要包括7种,即Serial,Serial Old,ParNew,Parallel Scavenge,Parallel Old以及CMS,G1收集器。如下图所示:
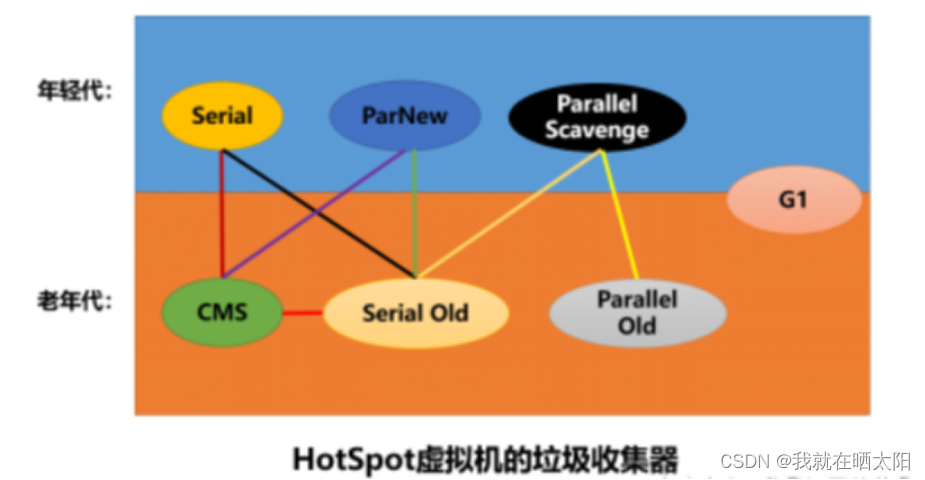
1、Serial收集器:
Serial收集器是一个单线程的垃圾收集器,并且在执行垃圾回收的时候需要 Stop The World。虚拟机运行在Client模式下的默认新生代收集器。Serial收集器的优点是简单高效,对于限定在单个CPU环境来说,Serial收集器没有多线程交互的开销。
2、Serial Old收集器:
Serial Old是Serial收集器的老年代版本,也是一个单线程收集器。主要也是给在Client模式下的虚拟机使用。在Server模式下存在主要是做为CMS垃圾收集器的后备预案,当CMS并发收集发生Concurrent Mode Failure时使用。
3、ParNew收集器:
ParNew是Serial收集器的多线程版本,新生代是并行的(多线程的),老年代是串行的(单线程的),新生代采用复制算法,老年代采用标记整理算法。可以使用参数:-XX:UseParNewGC使用该收集器,使用 -XX:ParallelGCThreads可以限制线程数量。
4、Parallel Scavenge垃圾收集器:
Parallel Scavenge是一种新生代收集器,使用复制算法的收集器,而且是并行的多线程收集器。Paralle收集器特点是更加关注吞吐量(吞吐量就是cpu用于运行用户代码的时间与cpu总消耗时间的比值)。可以通过-XX:MaxGCPauseMillis参数控制最大垃圾收集停顿时间;通过-XX:GCTimeRatio参数直接设置吞吐量大小;通过-XX:+UseAdaptiveSizePolicy参数可以打开GC自适应调节策略,该参数打开之后虚拟机会根据系统的运行情况收集性能监控信息,动态调整虚拟机参数以提供最合适的停顿时间或者最大的吞吐量。自适应调节策略是Parallel Scavenge收集器和ParNew的主要区别之一。
5、Parallel Old收集器:
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法。
6、CMS(Concurrent Mark Sweep)收集器(并发标记清除)
CMS收集器是一种以获取最短回收停顿时间为目标的收集器。CMS收集器是基于标记-清除算法实现的,是一种老年代收集器,通常与ParNew一起使用。
CMS的垃圾收集过程分为4步:
1)初始标记:需要“Stop the World”,初始标记仅仅只是标记一下GC Root能直接关联到的对象,速度很快。
2)并发标记:是主要标记过程,这个标记过程是和用户线程并发执行的。
3)重新标记:需要“Stop the World”,为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录(停顿时间比初始标记长,但比并发标记短得多)。
4)并发清除:和用户线程并发执行的,基于标记结果来清理对象。
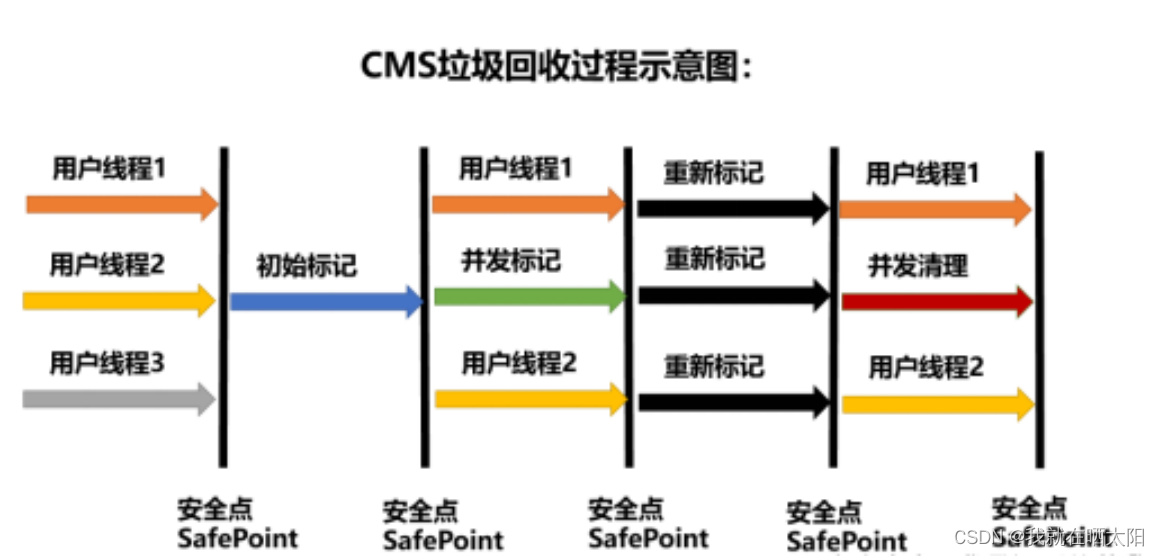
那么问题来了,如果在重新标记之前刚好发生了一次MinorGC,会不会导致重新标记阶段Stop the World时间太长?
答:不会的,在并发标记阶段其实还包括了一次并发的预清理阶段,虚拟机会主动等待年轻代发生垃圾回收,这样可以将重新标记对象引用关系的步骤放在并发标记阶段,有效降低重新标记阶段Stop The World的时间。
CMS垃圾回收器的优缺点分析:
CMS以降低垃圾回收的停顿时间为目的,很显然其具有并发收集,停顿时间低的优点。
缺点主要包括如下:
1)对CPU资源非常敏感,因为并发标记和并发清理阶段和用户线程一起运行,当CPU数变小时,性能容易出现问题。
2)收集过程中会产生浮动垃圾,所以不可以在老年代内存不够用了才进行垃圾回收,必须提前进行垃圾收集。通过参数-XX:CMSInitiatingOccupancyFraction的值来控制内存使用百分比。如果该值设置的太高,那么在CMS运行期间预留的内存可能无法满足程序所需,会出现Concurrent Mode Failure失败,之后会临时使用Serial Old收集器做为老年代收集器,会产生更长时间的停顿。
3)标记-清除方式会产生内存碎片,可以使用参数-XX:UseCMSCompactAtFullCollection来控制是否开启内存整理(无法并发,默认是开启的)。参数-XX:CMSFullGCsBeforeCompaction用于设置执行多少次不压缩的Full GC后进行一次带压缩的内存碎片整理(默认值是0)。
接下来,我们先看下上边介绍的浮动垃圾是怎么产生的吧。
浮动垃圾:
由于在应用运行的同时进行垃圾回收,所以有些垃圾可能在垃圾回收进行完成时产生,这样就造成了“Floating Garbage”,这些垃圾需要在下次垃圾回收周期时才能回收掉。所以,并发收集器一般需要20%的预留空间用于这些浮动垃圾。
7、G1(Garbage-First)收集器:
G1收集器将新生代和老年代取消了,取而代之的是将堆划分为若干的区域,每个区域都可以根据需要扮演新生代的Eden和Survivor区或者老年代空间,仍然属于分代收集器,区域的一部分包含新生代,新生代采用复制算法,老年代采用标记-整理算法。
通过将JVM堆分为一个个的区域(region),G1收集器可以避免在Java堆中进行全区域的垃圾收集。G1跟踪各个region里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据回收时间来优先回收价值最大的region。
G1收集器的特点:
1)并行与并发:G1能充分利用多CPU,多核环境下的硬件优势,来缩短Stop the World,是并发的收集器。
2)分代收集:G1不需要其他收集器就能独立管理整个GC堆,能够采用不同的方式去处理新建对象、存活一段时间的对象和熬过多次GC的对象。
3)空间整合:G1从整体来看是基于标记-整理算法,从局部(两个Region)上看基于复制算法实现,G1运作期间不会产生内存空间碎片。
4)可预测的停顿:能够建立可以预测的停顿时间模型,预测停顿时间。
和CMS收集器类似,G1收集器的垃圾回收工作也分为了四个阶段:
初始标记
并发标记
最终标记
筛选回收
其中,筛选回收阶段首先对各个Region的回收价值和成本进行计算,根据用户期望的GC停顿时间来制定回收计划。
9.Java常用版本垃圾收集器
1.首先说如果看怎么看
我的版本是jdk1.8
java -XX:+PrintCommandLineFlags -version

2.jdk1.8和1.9用的版本
jdk1.8默认的新生代垃圾收集器:Parallel Scavenge,老年代:Parallel Old
jdk1.9 默认垃圾收集器G1
Springboot
什么是 Spring Boot?
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
Spring Boot 有哪些优点?
Spring Boot 主要有如下优点:
1.容易上手,提升开发效率,为 Spring 开发提供一个更快、更广泛的入门体验。
2.开箱即用,远离繁琐的配置。
3.提供了一系列大型项目通用的非业务性功能,例如:内嵌服务器、安全管理、运行数据监控、运行状况检查和外部化配置等。
4.没有代码生成,也不需要XML配置。
5.避免大量的 Maven 导入和各种版本冲突。
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
@ComponentScan:Spring组件扫描。
配置
什么是 JavaConfig?
Spring JavaConfig 是 Spring 社区的产品,它提供了配置 Spring IoC 容器的纯Java 方法。因此它有助于避免使用 XML 配置。使用 JavaConfig 的优点在于:
(1)面向对象的配置。由于配置被定义为 JavaConfig 中的类,因此用户可以充分利用 Java 中的面向对象功能。一个配置类可以继承另一个,重写它的@Bean 方法等。
(2)减少或消除 XML 配置。基于依赖注入原则的外化配置的好处已被证明。但是,许多开发人员不希望在 XML 和 Java 之间来回切换。JavaConfig 为开发人员提供了一种纯 Java 方法来配置与 XML 配置概念相似的 Spring 容器。从技术角度来讲,只使用 JavaConfig 配置类来配置容器是可行的,但实际上很多人认为将JavaConfig 与 XML 混合匹配是理想的。
(3)类型安全和重构友好。JavaConfig 提供了一种类型安全的方法来配置 Spring容器。由于 Java 5.0 对泛型的支持,现在可以按类型而不是按名称检索 bean,不需要任何强制转换或基于字符串的查找。
Spring Boot 自动配置原理是什么?
注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,
@EnableAutoConfiguration 给容器导入META-INF/spring.factories 里定义的自动配置类。
筛选有效的自动配置类。
每一个自动配置类结合对应的 xxxProperties.java 读取配置文件进行自动配置功能
你如何理解 Spring Boot 配置加载顺序?
在 Spring Boot 里面,可以使用以下几种方式来加载配置。
1)properties文件;
2)YAML文件;
3)系统环境变量;
4)命令行参数;
等等……
什么是 YAML?
YAML 是一种人类可读的数据序列化语言。它通常用于配置文件。与属性文件相比,如果我们想要在配置文件中添加复杂的属性,YAML 文件就更加结构化,而且更少混淆。可以看出 YAML 具有分层配置数据。
YAML 配置的优势在哪里 ?
YAML 现在可以算是非常流行的一种配置文件格式了,无论是前端还是后端,都可以见到 YAML 配置。那么 YAML 配置和传统的 properties 配置相比到底有哪些优势呢?
1.配置有序,在一些特殊的场景下,配置有序很关键
2.支持数组,数组中的元素可以是基本数据类型也可以是对象
3.简洁
相比 properties 配置文件,YAML 还有一个缺点,就是不支持 @PropertySource 注解导入自定义的 YAML 配置。
Spring Boot 是否可以使用 XML 配置 ?
Spring Boot 推荐使用 Java 配置而非 XML 配置,但是 Spring Boot 中也可以使用 XML 配置,通过 @ImportResource 注解可以引入一个 XML 配置。
spring boot 核心配置文件是什么?bootstrap.properties 和 application.properties 有何区别 ?
单纯做 Spring Boot 开发,可能不太容易遇到 bootstrap.properties 配置文件,但是在结合 Spring Cloud 时,这个配置就会经常遇到了,特别是在需要加载一些远程配置文件的时侯。
spring boot 核心的两个配置文件:
1.bootstrap (. yml 或者 . properties):boostrap 由父 ApplicationContext 加载的,比 applicaton 优先加载,配置在应用程序上下文的引导阶段生效。一般来说我们在 Spring Cloud Config 或者 Nacos 中会用到它。且 boostrap 里面的属性不能被覆盖;
2.application (. yml 或者 . properties): 由ApplicatonContext 加载,用于 spring boot 项目的自动化配置。
什么是 Spring Profiles?
Spring Profiles 允许用户根据配置文件(dev,test,prod 等)来注册 bean。因此,当应用程序在开发中运行时,只有某些 bean 可以加载,而在 PRODUCTION中,某些其他 bean 可以加载。假设我们的要求是 Swagger 文档仅适用于 QA 环境,并且禁用所有其他文档。这可以使用配置文件来完成。Spring Boot 使得使用配置文件非常简单。
如何在自定义端口上运行 Spring Boot 应用程序?
为了在自定义端口上运行 Spring Boot 应用程序,您可以在application.properties 中指定端口。server.port = 8090
安全
如何实现 Spring Boot 应用程序的安全性?
为了实现 Spring Boot 的安全性,我们使用 spring-boot-starter-security 依赖项,并且必须添加安全配置。它只需要很少的代码。配置类将必须扩展WebSecurityConfigurerAdapter 并覆盖其方法。
比较一下 Spring Security 和 Shiro 各自的优缺点 ?
由于 Spring Boot 官方提供了大量的非常方便的开箱即用的 Starter ,包括 Spring Security 的 Starter ,使得在 Spring Boot 中使用 Spring Security 变得更加容易,甚至只需要添加一个依赖就可以保护所有的接口,所以,如果是 Spring Boot 项目,一般选择 Spring Security 。当然这只是一个建议的组合,单纯从技术上来说,无论怎么组合,都是没有问题的。Shiro 和 Spring Security 相比,主要有如下一些特点:
1.Spring Security 是一个重量级的安全管理框架;Shiro 则是一个轻量级的安全管理框架
2.Spring Security 概念复杂,配置繁琐;Shiro 概念简单、配置简单
3.Spring Security 功能强大;Shiro 功能简单
Spring Boot 中如何解决跨域问题 ?
跨域可以在前端通过 JSONP 来解决,但是 JSONP 只可以发送 GET 请求,无法发送其他类型的请求,在 RESTful 风格的应用中,就显得非常鸡肋,因此我们推荐在后端通过 (CORS,Cross-origin resource sharing) 来解决跨域问题。这种解决方案并非 Spring Boot 特有的,在传统的 SSM 框架中,就可以通过 CORS 来解决跨域问题,只不过之前我们是在 XML 文件中配置 CORS ,现在可以通过实现WebMvcConfigurer接口然后重写addCorsMappings方法解决跨域问题。
@Configurationpublic class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/\*\*")
.allowedOrigins("\*")
.allowCredentials(true)
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.maxAge(3600);
}
}
项目中前后端分离部署,所以需要解决跨域的问题。
我们使用cookie存放用户登录的信息,在spring拦截器进行权限控制,当权限不符合时,直接返回给用户固定的json结果。
当用户登录以后,正常使用;当用户退出登录状态时或者token过期时,由于拦截器和跨域的顺序有问题,出现了跨域的现象。
我们知道一个http请求,先走filter,到达servlet后才进行拦截器的处理,如果我们把cors放在filter里,就可以优先于权限拦截器执行。
```java
@Configurationpublic class CorsConfig {
@Bean
public CorsFilter corsFilter() {
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.addAllowedOrigin("\*");
corsConfiguration.addAllowedHeader("\*");
corsConfiguration.addAllowedMethod("\*");
corsConfiguration.setAllowCredentials(true);
UrlBasedCorsConfigurationSource urlBasedCorsConfigurationSource = new UrlBasedCorsConfigurationSource();
urlBasedCorsConfigurationSource.registerCorsConfiguration("/\*\*", corsConfiguration);
return new CorsFilter(urlBasedCorsConfigurationSource);
}
}
什么是 CSRF 攻击?
CSRF 代表跨站请求伪造。这是一种攻击,迫使最终用户在当前通过身份验证的Web 应用程序上执行不需要的操作。CSRF 攻击专门针对状态改变请求,而不是数据窃取,因为攻击者无法查看对伪造请求的响应。
监视器
Spring Boot 中的监视器是什么?
Spring boot actuator 是 spring 启动框架中的重要功能之一。Spring boot 监视器可帮助您访问生产环境中正在运行的应用程序的当前状态。有几个指标必须在生产环境中进行检查和监控。即使一些外部应用程序可能正在使用这些服务来向相关人员触发警报消息。监视器模块公开了一组可直接作为 HTTP URL 访问的REST 端点来检查状态。
如何在 Spring Boot 中禁用 Actuator 端点安全性?
默认情况下,所有敏感的 HTTP 端点都是安全的,只有具有 ACTUATOR 角色的用户才能访问它们。安全性是使用标准的 HttpServletRequest.isUserInRole 方法实施的。 我们可以使用来禁用安全性。只有在执行机构端点在防火墙后访问时,才建议禁用安全性。
我们如何监视所有 Spring Boot 微服务?
Spring Boot 提供监视器端点以监控各个微服务的度量。这些端点对于获取有关应用程序的信息(如它们是否已启动)以及它们的组件(如数据库等)是否正常运行很有帮助。但是,使用监视器的一个主要缺点或困难是,我们必须单独打开应用程序的知识点以了解其状态或健康状况。想象一下涉及 50 个应用程序的微服务,管理员将不得不击中所有 50 个应用程序的执行终端。为了帮助我们处理这种情况,我们将使用位于的开源项目。 它建立在 Spring Boot Actuator 之上,它提供了一个 Web UI,使我们能够可视化多个应用程序的度量。
整合第三方项目
什么是 WebSockets?
WebSocket 是一种计算机通信协议,通过单个 TCP 连接提供全双工通信信道。
1、WebSocket 是双向的 -使用 WebSocket 客户端或服务器可以发起消息发送。
2、WebSocket 是全双工的 -客户端和服务器通信是相互独立的。
3、单个 TCP 连接 -初始连接使用 HTTP,然后将此连接升级到基于套接字的连接。然后这个单一连接用于所有未来的通信
4、Light -与 http 相比,WebSocket 消息数据交换要轻得多。
什么是 Spring Data ?
Spring Data 是 Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。Spring Data 具有如下特点:
SpringData 项目支持 NoSQL 存储:
1.MongoDB (文档数据库)
2.Neo4j(图形数据库)
3.Redis(键/值存储)
4.Hbase(列族数据库)
SpringData 项目所支持的关系数据存储技术:
1.JDBC
2.JPA
Spring Data Jpa 致力于减少数据访问层 (DAO) 的开发量. 开发者唯一要做的,就是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成!Spring Data JPA 通过规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
什么是 Spring Batch?
Spring Boot Batch 提供可重用的函数,这些函数在处理大量记录时非常重要,包括日志/跟踪,事务管理,作业处理统计信息,作业重新启动,跳过和资源管理。它还提供了更先进的技术服务和功能,通过优化和分区技术,可以实现极高批量和高性能批处理作业。简单以及复杂的大批量批处理作业可以高度可扩展的方式利用框架处理重要大量的信息。
什么是 FreeMarker 模板?
FreeMarker 是一个基于 Java 的模板引擎,最初专注于使用 MVC 软件架构进行动态网页生成。使用 Freemarker 的主要优点是表示层和业务层的完全分离。程序员可以处理应用程序代码,而设计人员可以处理 html 页面设计。最后使用freemarker 可以将这些结合起来,给出最终的输出页面。
如何集成 Spring Boot 和 ActiveMQ?
对于集成 Spring Boot 和 ActiveMQ,我们使用依赖关系。 它只需要很少的配置,并且不需要样板代码。
什么是 Apache Kafka?
Apache Kafka 是一个分布式发布 - 订阅消息系统。它是一个可扩展的,容错的发布 - 订阅消息系统,它使我们能够构建分布式应用程序。这是一个 Apache 顶级项目。Kafka 适合离线和在线消息消费。
什么是 Swagger?你用 Spring Boot 实现了它吗?
Swagger 广泛用于可视化 API,使用 Swagger UI 为前端开发人员提供在线沙箱。Swagger 是用于生成 RESTful Web 服务的可视化表示的工具,规范和完整框架实现。它使文档能够以与服务器相同的速度更新。当通过 Swagger 正确定义时,消费者可以使用最少量的实现逻辑来理解远程服务并与其进行交互。因此,Swagger消除了调用服务时的猜测。
前后端分离,如何维护接口文档 ?
前后端分离开发日益流行,大部分情况下,我们都是通过 Spring Boot 做前后端分离开发,前后端分离一定会有接口文档,不然会前后端会深深陷入到扯皮中。一个比较笨的方法就是使用 word 或者 md 来维护接口文档,但是效率太低,接口一变,所有人手上的文档都得变。在 Spring Boot 中,这个问题常见的解决方案是 Swagger ,使用 Swagger 我们可以快速生成一个接口文档网站,接口一旦发生变化,文档就会自动更新,所有开发工程师访问这一个在线网站就可以获取到最新的接口文档,非常方便。
其他
如何重新加载 Spring Boot 上的更改,而无需重新启动服务器?Spring Boot项目如何热部署?
这可以使用 DEV 工具来实现。通过这种依赖关系,您可以节省任何更改,嵌入式tomcat 将重新启动。Spring Boot 有一个开发工具(DevTools)模块,它有助于提高开发人员的生产力。Java 开发人员面临的一个主要挑战是将文件更改自动部署到服务器并自动重启服务器。开发人员可以重新加载 Spring Boot 上的更改,而无需重新启动服务器。这将消除每次手动部署更改的需要。Spring Boot 在发布它的第一个版本时没有这个功能。这是开发人员最需要的功能。DevTools 模块完全满足开发人员的需求。该模块将在生产环境中被禁用。它还提供 H2 数据库控制台以更好地测试应用程序。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId></dependency>
您使用了哪些 starter maven 依赖项?
使用了下面的一些依赖项
spring-boot-starter-activemq
spring-boot-starter-security
这有助于增加更少的依赖关系,并减少版本的冲突。
Spring Boot 中的 starter 到底是什么 ?
首先,这个 Starter 并非什么新的技术点,基本上还是基于 Spring 已有功能来实现的。首先它提供了一个自动化配置类,一般命名为 XXXAutoConfiguration ,在这个配置类中通过条件注解来决定一个配置是否生效(条件注解就是 Spring 中原本就有的),然后它还会提供一系列的默认配置,也允许开发者根据实际情况自定义相关配置,然后通过类型安全的属性注入将这些配置属性注入进来,新注入的属性会代替掉默认属性。正因为如此,很多第三方框架,我们只需要引入依赖就可以直接使用了。当然,开发者也可以自定义 Starter
spring-boot-starter-parent 有什么用 ?
我们都知道,新创建一个 Spring Boot 项目,默认都是有 parent 的,这个 parent 就是 spring-boot-starter-parent ,spring-boot-starter-parent 主要有如下作用:
1.定义了 Java 编译版本为 1.8 。
2.使用 UTF-8 格式编码。
3.继承自 spring-boot-dependencies,这个里边定义了依赖的版本,也正是因为继承了这个依赖,所以我们在写依赖时才不需要写版本号。
4.执行打包操作的配置。
5.自动化的资源过滤。
6.自动化的插件配置。
7.针对 application.properties 和 application.yml 的资源过滤,包括通过 profile 定义的不同环境的配置文件,例如 application-dev.properties 和 application-dev.yml。
Spring Boot 打成的 jar 和普通的 jar 有什么区别 ?
Spring Boot 项目最终打包成的 jar 是可执行 jar ,这种 jar 可以直接通过 java -jar xxx.jar 命令来运行,这种 jar 不可以作为普通的 jar 被其他项目依赖,即使依赖了也无法使用其中的类。
Spring Boot 的 jar 无法被其他项目依赖,主要还是他和普通 jar 的结构不同。普通的 jar 包,解压后直接就是包名,包里就是我们的代码,而 Spring Boot 打包成的可执行 jar 解压后,在 \BOOT-INF\classes 目录下才是我们的代码,因此无法被直接引用。如果非要引用,可以在 pom.xml 文件中增加配置,将 Spring Boot 项目打包成两个 jar ,一个可执行,一个可引用。
运行 Spring Boot 有哪几种方式?
1)打包用命令或者放到容器中运行
2)用 Maven/ Gradle 插件运行
3)直接执行 main 方法运行
Spring Boot 需要独立的容器运行吗?
可以不需要,内置了 Tomcat/ Jetty 等容器。
开启 Spring Boot 特性有哪几种方式?
1)继承spring-boot-starter-parent项目
2)导入spring-boot-dependencies项目依赖
如何使用 Spring Boot 实现异常处理?
Spring 提供了一种使用 ControllerAdvice 处理异常的非常有用的方法。 我们通过实现一个 ControlerAdvice 类,来处理控制器类抛出的所有异常。
如何使用 Spring Boot 实现分页和排序?
使用 Spring Boot 实现分页非常简单。使用 Spring Data-JPA 可以实现将可分页的传递给存储库方法。
微服务中如何实现 session 共享 ?
在微服务中,一个完整的项目被拆分成多个不相同的独立的服务,各个服务独立部署在不同的服务器上,各自的 session 被从物理空间上隔离开了,但是经常,我们需要在不同微服务之间共享 session ,常见的方案就是 Spring Session + Redis 来实现 session 共享。将所有微服务的 session 统一保存在 Redis 上,当各个微服务对 session 有相关的读写操作时,都去操作 Redis 上的 session 。这样就实现了 session 共享,Spring Session 基于 Spring 中的代理过滤器实现,使得 session 的同步操作对开发人员而言是透明的,非常简便。
Spring Boot 中如何实现定时任务 ?
定时任务也是一个常见的需求,Spring Boot 中对于定时任务的支持主要还是来自 Spring 框架。
在 Spring Boot 中使用定时任务主要有两种不同的方式,一个就是使用 Spring 中的 @Scheduled 注解,另一个则是使用第三方框架 Quartz。
使用 Spring 中的 @Scheduled 的方式主要通过 @Scheduled 注解来实现。
使用 Quartz ,则按照 Quartz 的方式,定义 Job 和 Trigger 即可。
Springcloud
1.springcloud与dubbo的区别?
https://jingyan.baidu.com/article/b0b63dbf3784294a483070fa.html
1.1 springcloud与dubbo支持技术栈比较
1.2 springcloud和dubbo的最大区别:springcloud抛弃了dubbo的rpc通信,采用的是基于http的rest方式。
1.3 springboot与dubbo就相当于品牌机与组装机的区别。
1.4 springcloud与dubbo的社区活跃度对比。
1
2
3
4
5
6
7
8
9
10
11 二、整体比较
1、dubbo由于是二进制的传输,占用带宽会更少
2、springCloud是http协议传输,带宽会比较多,同时使用http协议一般会使用JSON报文,消耗会更大
3、dubbo的开发难度较大,原因是dubbo的jar包依赖问题很多大型工程无法解决
4、springcloud的接口协议约定比较自由且松散,需要有强有力的行政措施来限制接口无序升级
5、dubbo的注册中心可以选择zk,redis等多种,springcloud的注册中心只能用eureka或者自研
2.ribbon的负载均衡策略
2.1 RoundRobinRule: 轮询策略,Ribbon以轮询的方式选择服务器,这个是默认值。所以示例中所启动的两个服务会被循环访问;
2.2 RandomRule: 随机策略,也就是说Ribbon会随机从服务器列表中选择一个进行访问;
2.3 BestAvailableRule: 最大可用策略,即先过滤出故障服务器后,选择一个当前并发请求数最小的;
2.4 WeightedResponseTimeRule: 带有加权的轮询策略,对各个服务器响应时间进行加权处理,然后在采用轮询的方式来获取相应的服务器;
2.5 AvailabilityFilteringRule: 可用过滤策略,先过滤出故障的或并发请求大于阈值的一部分服务实例,然后再以线性轮询的方式从过滤后的实例清单中选出一个;
2.6 ZoneAvoidanceRule: 区域感知策略,先使用主过滤条件(区域负载器,选择最优区域)对所有实例过滤并返回过滤后的实例清单,依次使用次过滤条件列表中的过滤条件对主过滤条件的结果进行过滤,判断最小过滤数(默认1)和最小过滤百分比(默认0),最后对满足条件的服务器则使用RoundRobinRule(轮询方式)选择一个服务器实例。
3.ribbon和feign的区别
3.1 启动类使用的注解不同,Ribbon用的是@RibbonClient,Feign用的是@EnableFeignClients。
3.2 服务的指定位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
3.3 调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。
Feign则是在Ribbon的基础上进行了一次改进,采用接口的方式,将需要调用的其他服务的方法定义成抽象方法即可,
不需要自己构建http请求。不过要注意的是抽象方法的注解、方法签名要和提供服务的方法完全一致。
4.ribbon、feign以及hystrix的超时、重试设置
参考:https://blog.csdn.net/hsz2568952354/article/details/89508707
https://blog.csdn.net/hsz2568952354/article/details/89466511
4.1 ribbon的设置:
默认是没有超时,需开启,把ribbon.http.client.enabled设置为true。开启后,而如果不配超时时间,默认超时时间是1秒,超时后默认会重试一次。
做如下配置,以上配置最多会调用6次((MaxAutoRetries+1)*(MaxAutoRetriesNextServer+1)),也就是最多会重试5次。
1
2
3
4
5
6
7
8
9 ribbon:
ReadTimeout: 2000
ConnectionTimeout: 2000
OkToRetryOnAllOperations: true
MaxAutoRetriesNextServer: 1 # 当前实例全部失败后可以换1个实例再重试
MaxAutoRetries: 2 # 在当前实例只重试2次
http:
client:
enabled: true
4.2 feign设置
feign默认的超时时间是1秒,重试1次。
4.3 hystrix设置
配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 server:
port: 8002
eureka:
client:
serviceUrl:
defaultZone: http://localhost:5000/eureka/
spring:
application:
name: service-hystrix
feign:
hystrix:
enabled: true # 开启
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 10000 # 断路器的超时时间需要大于ribbon的超时时间,不然重试没有意义
ribbon:
ReadTimeout: 2000
ConnectionTimeout: 2000
OkToRetryOnAllOperations: true
MaxAutoRetriesNextServer: 1
MaxAutoRetries: 0
当超时并且重试也超时时,会执行降级逻辑,而不会报错。这里,断路器的超时时间需要大于ribbon的超时时间,不然重试没有意义。比如将一下设置去掉(默认值是1秒)或设置较低。
可以看到,第一次超时了并重试一次,第二次没有超时,但是页面已经显示error,执行降级逻辑,是因为远程调用的超时时间已经超过了断路器的超时时间,意思是第一次还没执行完就已经执行降级逻辑返回,虽然后台还在重试。
5.hystrix的隔离策略
5.1 隔离策略有两种:
线程隔离、信号量隔离。
5.2 隔离策略的区别
详见:https://blog.csdn.net/dengqiang123456/article/details/75935122
6.hystrix功能实现的具体方式
6.1 服务降级,设置超时时间
6.2 服务限流,通过隔离策略进行限流按制。
6.3 服务熔断:
6.3.1 熔断的三种状态:
1
2 正常状态下,电路处于关闭状态(Closed),如果调用持续出错或者超时,电路被打开进入熔断状态(Open),后续一段时间内的所有调用都会被拒绝(Fail Fast),
这个拒绝时间withCircuitBreakerSleepWindowInMilliseconds控制默认是5s
一段时间以后,保护器会尝试进入半熔断状态(Half-Open),允许少量请求进来尝试,如果调用仍然失败,则回到熔断状态,如果调用成功,则回到电路闭合状态;
断路器
(1)hystrix.command.default.circuitBreaker.requestVolumeThreshold(当在配置时间窗口内达到此数量的失败后,进行短路。默认20个)
For example, if the value is 20, then if only 19 requests are received in the rolling window (say a window of 10 seconds) the circuit will not trip open even if all 19 failed.
简言之,10s内请求失败数量达到20个,断路器开。
(2)hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds(短路多久以后开始尝试是否恢复,默认5s)
(3)hystrix.command.default.circuitBreaker.errorThresholdPercentage(出错百分比阈值,当达到此阈值后,开始短路。默认50%)
6.3.2 熔断机制简述:
1 当出现问题时,Hystrix会检查一个一定时长(图中为10s)的一个时间窗(window),在这个时间窗内是否有足够多的请求,如果有足够多的请求,是否错误率已经达到阈值,
如果达到则启动断路器熔断机制,这时再有请求过来就会直接到fallback路径。在断路器打开之后,
会有一个sleep window(图中为5s),每经过一个sleep window,当有请求过来的时候,断路器会放掉一个请求给remote 服务,
让它去试探下游服务是否已经恢复,如果成功,断路器会恢复到正常状态,让后续请求重新请求到remote 服务,否则,保持熔断状态。
参考自:https://www.cnblogs.com/amazement/p/8445294.html
https://www.jianshu.com/p/6e9619cbdfc3?tdsourcetag=s_pctim_aiomsg
https://blog.csdn.net/tongtong_use/article/details/78611225
7.项目中zuul常用的功能
7.1 提供动态路由
7.2 提供安全、鉴权处理
7.3 跨域处理
7.4 全局动态路由的hystrix(熔断、降级、限流)处理
消息队列
为什么使用MQ?MQ的优点
简答
异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
日志处理 - 解决大量日志传输。
消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
详答
主要是:解耦、异步、削峰。
解耦:A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?A 系统负责人几乎崩溃…A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。
就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用 MQ 给它异步化解耦。
异步:A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求。如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms。
削峰:减少高峰时期对服务器压力。
消息队列有什么优缺点?RabbitMQ有什么优缺点?
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点有以下几个:
系统可用性降低
本来系统运行好好的,现在你非要加入个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低;
系统复杂度提高
加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,需要考虑的东西更多,复杂性增大。
一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,用,还是得用的。
你们公司生产环境用的是什么消息中间件?
这个首先你可以说下你们公司选用的是什么消息中间件,比如用的是RabbitMQ,然后可以初步给一些你对不同MQ中间件技术的选型分析。
举个例子:比如说ActiveMQ是老牌的消息中间件,国内很多公司过去运用的还是非常广泛的,功能很强大。
但是问题在于没法确认ActiveMQ可以支撑互联网公司的高并发、高负载以及高吞吐的复杂场景,在国内互联网公司落地较少。而且使用较多的是一些传统企业,用ActiveMQ做异步调用和系统解耦。
然后你可以说说RabbitMQ,他的好处在于可以支撑高并发、高吞吐、性能很高,同时有非常完善便捷的后台管理界面可以使用。
另外,他还支持集群化、高可用部署架构、消息高可靠支持,功能较为完善。
而且经过调研,国内各大互联网公司落地大规模RabbitMQ集群支撑自身业务的case较多,国内各种中小型互联网公司使用RabbitMQ的实践也比较多。
除此之外,RabbitMQ的开源社区很活跃,较高频率的迭代版本,来修复发现的bug以及进行各种优化,因此综合考虑过后,公司采取了RabbitMQ。
但是RabbitMQ也有一点缺陷,就是他自身是基于erlang语言开发的,所以导致较为难以分析里面的源码,也较难进行深层次的源码定制和改造,毕竟需要较为扎实的erlang语言功底才可以。
然后可以聊聊RocketMQ,是阿里开源的,经过阿里的生产环境的超高并发、高吞吐的考验,性能卓越,同时还支持分布式事务等特殊场景。
而且RocketMQ是基于Java语言开发的,适合深入阅读源码,有需要可以站在源码层面解决线上生产问题,包括源码的二次开发和改造。
另外就是Kafka。Kafka提供的消息中间件的功能明显较少一些,相对上述几款MQ中间件要少很多。
但是Kafka的优势在于专为超高吞吐量的实时日志采集、实时数据同步、实时数据计算等场景来设计。
因此Kafka在大数据领域中配合实时计算技术(比如Spark Streaming、Storm、Flink)使用的较多。但是在传统的MQ中间件使用场景中较少采用。
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
ActiveMQ RabbitMQ RocketMQ Kafka ZeroMQ
单机吞吐量 比RabbitMQ低 2.6w/s(消息做持久化) 11.6w/s 17.3w/s 29w/s
开发语言 Java Erlang Java Scala/Java C
主要维护者 Apache Mozilla/Spring Alibaba Apache iMatix,创始人已去世
成熟度 成熟 成熟 开源版本不够成熟 比较成熟 只有C、PHP等版本成熟
订阅形式 点对点(p2p)、广播(发布-订阅) 提供了4种:direct, topic ,Headers和fanout。fanout就是广播模式 基于topic/messageTag以及按照消息类型、属性进行正则匹配的发布订阅模式 基于topic以及按照topic进行正则匹配的发布订阅模式 点对点(p2p)
持久化 支持少量堆积 支持少量堆积 支持大量堆积 支持大量堆积 不支持
顺序消息 不支持 不支持 支持 支持 不支持
性能稳定性 好 好 一般 较差 很好
集群方式 支持简单集群模式,比如’主-备’,对高级集群模式支持不好。 支持简单集群,'复制’模式,对高级集群模式支持不好。 常用 多对’Master-Slave’ 模式,开源版本需手动切换Slave变成Master 天然的‘Leader-Slave’无状态集群,每台服务器既是Master也是Slave 不支持
管理界面 一般 较好 一般 无 无
综上,各种对比之后,有如下建议:
一般的业务系统要引入 MQ,最早大家都用 ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了;
后来大家开始用 RabbitMQ,但是确实 erlang 语言阻止了大量的 Java 工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也高;
不过现在确实越来越多的公司会去用 RocketMQ,确实很不错,毕竟是阿里出品,但社区可能有突然黄掉的风险(目前 RocketMQ 已捐给 Apache,但 GitHub 上的活跃度其实不算高)对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃的开源社区,绝对不会黄。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
MQ 有哪些常见问题?如何解决这些问题?
MQ 的常见问题有:
1.消息的顺序问题
2.消息的重复问题
消息的顺序问题
消息有序指的是可以按照消息的发送顺序来消费。
假如生产者产生了 2 条消息:M1、M2,假定 M1 发送到 S1,M2 发送到 S2,如果要保证 M1 先于 M2 被消费,怎么做?
解决方案:
(1)保证生产者 - MQServer - 消费者是一对一对一的关系
缺陷:
并行度就会成为消息系统的瓶颈(吞吐量不够)
更多的异常处理,比如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的精力来解决阻塞的问题。 (2)通过合理的设计或者将问题分解来规避。
不关注乱序的应用实际大量存在
队列无序并不意味着消息无序 所以从业务层面来保证消息的顺序而不仅仅是依赖于消息系统,是一种更合理的方式。
消息的重复问题
造成消息重复的根本原因是:网络不可达。
所以解决这个问题的办法就是绕过这个问题。那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
消费端处理消息的业务逻辑保持幂等性。只要保持幂等性,不管来多少条重复消息,最后处理的结果都一样。保证每条消息都有唯一编号且保证消息处理成功与去重表的日志同时出现。利用一张日志表来记录已经处理成功的消息的 ID,如果新到的消息 ID 已经在日志表中,那么就不再处理这条消息。
什么是RabbitMQ?
RabbitMQ是一款开源的,Erlang编写的,基于AMQP协议的消息中间件
rabbitmq 的使用场景
(1)服务间异步通信
(2)顺序消费
(3)定时任务
(4)请求削峰
RabbitMQ基本概念
Broker: 简单来说就是消息队列服务器实体
Exchange: 消息交换机,它指定消息按什么规则,路由到哪个队列
Queue: 消息队列载体,每个消息都会被投入到一个或多个队列
Binding: 绑定,它的作用就是把exchange和queue按照路由规则绑定起来
Routing Key: 路由关键字,exchange根据这个关键字进行消息投递
VHost: vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
Producer: 消息生产者,就是投递消息的程序
Consumer: 消息消费者,就是接受消息的程序
Channel: 消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务
由Exchange、Queue、RoutingKey三个才能决定一个从Exchange到Queue的唯一的线路。
RabbitMQ的工作模式
一.simple模式(即最简单的收发模式)
1.消息产生消息,将消息放入队列
2.消息的消费者(consumer) 监听 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除(隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失,这里可以设置成手动的ack,但如果设置成手动ack,处理完后要及时发送ack消息给队列,否则会造成内存溢出)。
二.work工作模式(资源的竞争)
1.消息产生者将消息放入队列消费者可以有多个,消费者1,消费者2同时监听同一个队列,消息被消费。C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患:高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize) 保证一条消息只能被一个消费者使用)。
三.publish/subscribe发布订阅(共享资源)
1、每个消费者监听自己的队列;
2、生产者将消息发给broker,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接收到消息。
四.routing路由模式
1.消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息;
2.根据业务功能定义路由字符串
3.从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中。
4.业务场景:error 通知;EXCEPTION;错误通知的功能;传统意义的错误通知;客户通知;利用key路由,可以将程序中的错误封装成消息传入到消息队列中,开发者可以自定义消费者,实时接收错误;
五.topic 主题模式(路由模式的一种)
1.星号井号代表通配符
2.星号代表多个单词,井号代表一个单词
3.路由功能添加模糊匹配
4.消息产生者产生消息,把消息交给交换机
5.交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
(在我的理解看来就是routing查询的一种模糊匹配,就类似sql的模糊查询方式)
如何保证RabbitMQ消息的顺序性?
拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点;或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
消息如何分发?
若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。通过路由可实现多消费的功能
消息怎么路由?
消息提供方->路由->一至多个队列消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。通过队列路由键,可以把队列绑定到交换器上。消息到达交换器后,RabbitMQ 会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则);
常用的交换器主要分为一下三种:
fanout:如果交换器收到消息,将会广播到所有绑定的队列上
direct:如果路由键完全匹配,消息就被投递到相应的队列
topic:可以使来自不同源头的消息能够到达同一个队列。 使用 topic 交换器时,可以使用通配符
消息基于什么传输?
由于 TCP 连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ 使用信道的方式来传输数据。信道是建立在真实的 TCP 连接内的虚拟连接,且每条 TCP 连接上的信道数量没有限制。
如何保证消息不被重复消费?或者说,如何保证消息消费时的幂等性?
先说为什么会重复消费:正常情况下,消费者在消费消息的时候,消费完毕后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除;
但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
针对以上问题,一个解决思路是:保证消息的唯一性,就算是多次传输,不要让消息的多次消费带来影响;保证消息等幂性;
比如:在写入消息队列的数据做唯一标示,消费消息时,根据唯一标识判断是否消费过;
假设你有个系统,消费一条消息就往数据库里插入一条数据,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下是否已经消费过了,若是就直接扔了,这样不就保留了一条数据,从而保证了数据的正确性。
如何确保消息正确地发送至 RabbitMQ? 如何确保消息接收方消费了消息?
发送方确认模式
将信道设置成 confirm 模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的 ID。
一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一 ID)。
如果 RabbitMQ 发生内部错误从而导致消息丢失,会发送一条 nack(notacknowledged,未确认)消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
接收方确认机制
消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ 才能安全地把消息从队列中删除。
这里并没有用到超时机制,RabbitMQ 仅通过 Consumer 的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ 给了 Consumer 足够长的时间来处理消息。保证数据的最终一致性;
下面罗列几种特殊情况
如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ 会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重复消费的隐患,需要去重)
如果消费者接收到消息却没有确认消息,连接也未断开,则 RabbitMQ 认为该消费者繁忙,将不会给该消费者分发更多的消息。
如何保证RabbitMQ消息的可靠传输?
消息不可靠的情况可能是消息丢失,劫持等原因;
丢失又分为:生产者丢失消息、消息列表丢失消息、消费者丢失消息;
生产者丢失消息:从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息;
transaction机制就是说:发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务(channel.txCommit())。然而,这种方式有个缺点:吞吐量下降;
confirm模式用的居多:一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;
rabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;
如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
消息队列丢数据:消息持久化。
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。
这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
那么如何持久化呢?
这里顺便说一下吧,其实也很容易,就下面两步
1.将queue的持久化标识durable设置为true,则代表是一个持久的队列
2.发送消息的时候将deliveryMode=2
这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据
消费者丢失消息:消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即可!
消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消息;
如果这时处理消息失败,就会丢失该消息;
解决方案:处理消息成功后,手动回复确认消息。
为什么不应该对所有的 message 都使用持久化机制?
首先,必然导致性能的下降,因为写磁盘比写 RAM 慢的多,message 的吞吐量可能有 10 倍的差距。
其次,message 的持久化机制用在 RabbitMQ 的内置 cluster 方案时会出现“坑爹”问题。矛盾点在于,若 message 设置了 persistent 属性,但 queue 未设置 durable 属性,那么当该 queue 的 owner node 出现异常后,在未重建该 queue 前,发往该 queue 的 message 将被 blackholed ;若 message 设置了 persistent 属性,同时 queue 也设置了 durable 属性,那么当 queue 的 owner node 异常且无法重启的情况下,则该 queue 无法在其他 node 上重建,只能等待其 owner node 重启后,才能恢复该 queue 的使用,而在这段时间内发送给该 queue 的 message 将被 blackholed 。
所以,是否要对 message 进行持久化,需要综合考虑性能需要,以及可能遇到的问题。若想达到 100,000 条/秒以上的消息吞吐量(单 RabbitMQ 服务器),则要么使用其他的方式来确保 message 的可靠 delivery ,要么使用非常快速的存储系统以支持全持久化(例如使用 SSD)。另外一种处理原则是:仅对关键消息作持久化处理(根据业务重要程度),且应该保证关键消息的量不会导致性能瓶颈。
如何保证高可用的?RabbitMQ 的集群
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
单机模式,就是 Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用单机模式
最后
码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
坑爹”问题。矛盾点在于,若 message 设置了 persistent 属性,但 queue 未设置 durable 属性,那么当该 queue 的 owner node 出现异常后,在未重建该 queue 前,发往该 queue 的 message 将被 blackholed ;若 message 设置了 persistent 属性,同时 queue 也设置了 durable 属性,那么当 queue 的 owner node 异常且无法重启的情况下,则该 queue 无法在其他 node 上重建,只能等待其 owner node 重启后,才能恢复该 queue 的使用,而在这段时间内发送给该 queue 的 message 将被 blackholed 。
所以,是否要对 message 进行持久化,需要综合考虑性能需要,以及可能遇到的问题。若想达到 100,000 条/秒以上的消息吞吐量(单 RabbitMQ 服务器),则要么使用其他的方式来确保 message 的可靠 delivery ,要么使用非常快速的存储系统以支持全持久化(例如使用 SSD)。另外一种处理原则是:仅对关键消息作持久化处理(根据业务重要程度),且应该保证关键消息的量不会导致性能瓶颈。
如何保证高可用的?RabbitMQ 的集群
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
单机模式,就是 Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用单机模式
最后
码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图
[外链图片转存中…(img-xjIB8m4B-1713068124658)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-LhFRC9Wf-1713068124659)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法